
Par Maxime Jumelle
CTO & Co-Founder
Publié le 14 janv. 2022
Catégorie Data Engineering
Apache Airflow : qu'est-ce que c'est ?
Apache Airflow est une plateforme écrites en Python qui permet d'exécuter, de planifier et de monitorer des flux automatisés (workflows). Avec Airflow, les pipelines de données (processus ETL, pipelines Machine Learning) peuvent donc être automatisés tout en fournissant des outils d'administration. C'est un outil très puissant, presque devenu un standard dans le domaine.
Mais comment fonctionne la plateforme Apache Airflow, et pourquoi est-elle aussi populaire chez les Data Engineers ? Voyons ensemble les concepts clés d'Airflow, et dans quelles situations on peut utiliser cette plateforme d'automatisation.
Concepts clés
Airflow était à l'origine développé par Airbnb. Il a ensuite été repris par la fondation Apache après avoir été rendu open source en 2016. Il s'agit aujourd'hui d'une référence dans la création de workflows automatisés, car il apporte de nombreuses fonctionnalités puissantes et une interopérabilité assez vaste avec beaucoup de services du Cloud et d'applications.
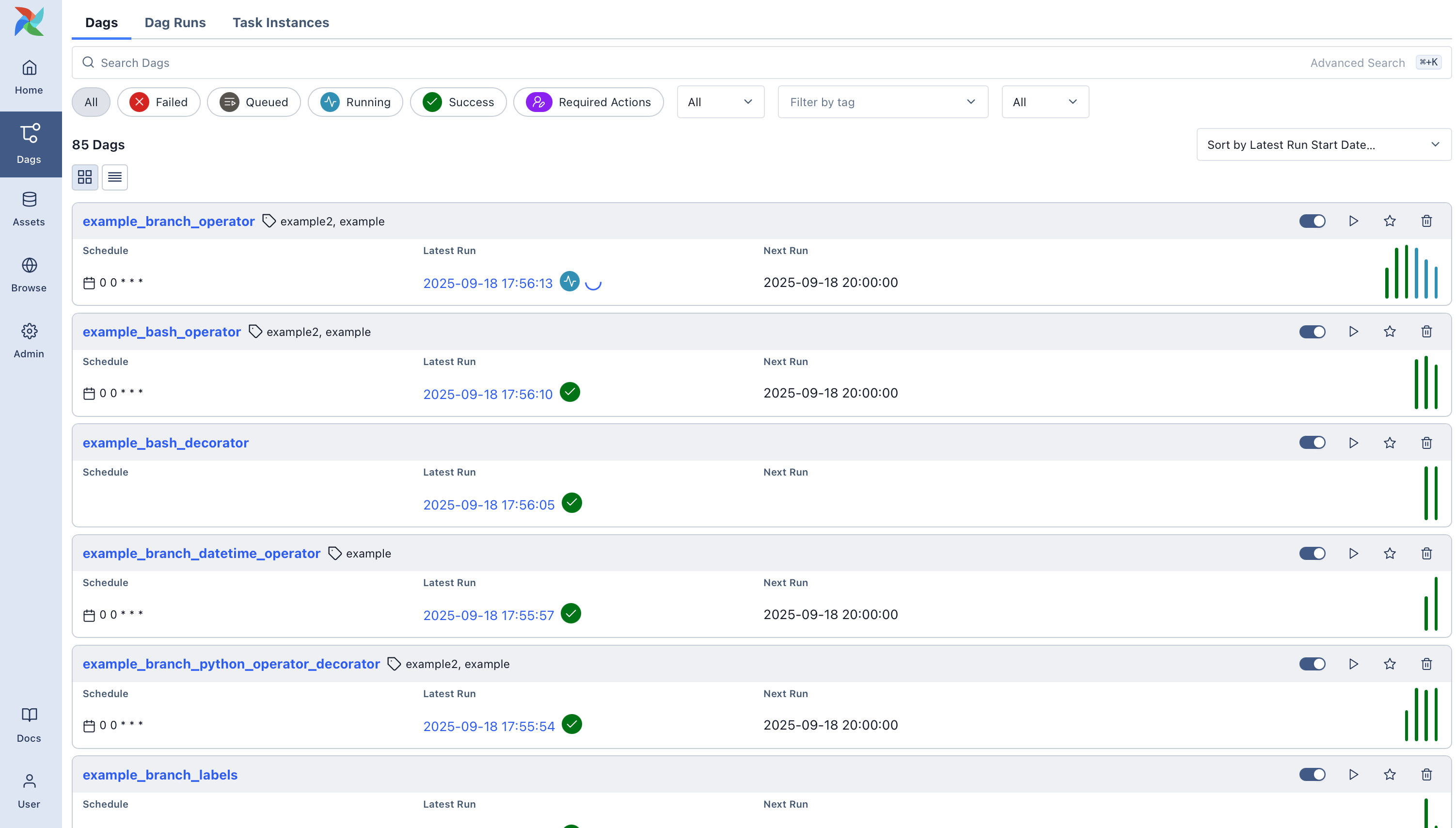
Initialement, lorsqu'il s'agissait d'automatiser des processus, nous utilisions le programme CRON, qui exécutait automatiquement des scripts, des commandes ou des programmes selon des cycles définis (intervalles de planification) et à une date et heure spécifique. Mais en pratique, avec l'apparition des microservices et du Cloud, les limites de CRON ont rapidement été atteintes.
- Il n'y a pas de monitoring ou de gestion efficace des différents processus automatisés.
- La gestion des échecs doit se faire manuellement pour chaque script/commande.
- Les exécutions sont réalisées sur la même machine hôte.
C'est ainsi qu'Airflow a été développé : proposer une alternative bien plus robuste et efficace à CRON, qui fonctionne parfaitement dans un environnement où les applications sont fortement découplées. Pour bien voir comment Airflow réalise toutes ces opérations, regardons tout d'abord les concepts clés.
À lire aussi : découvrez notre formation Data Engineer
DAG
L'élément central d'Airflow est le DAG ou Directed Acyclic Graph (Graphe Acyclique Orienté) codés en langage Python : les séquences sont modélisées par des DAG, et donc ne possèdent pas de circuits (boucles). Chaque élément (opération, traitement spécifique) du DAG possède un ou plusieurs descendants.

Cette représentation a l'avantage de pouvoir construire des workflows à la fois séquencés et en parallèle.
À l'intérieur de ces DAG, on retrouve des tâches, qui vont effectuer des traitements spécifiques et qui correspondent aux noeuds du graphe.
Operators / Sensors
Il existe deux types de tâches sous Airflow :
- Les operators effectuent des opérations/traitements. Par exemple, cela va être exécuter un code Python, lancer un serveur virtuel, lancer un calcul Spark, etc.
- Les sensors sont des déclencheurs qui seront activés lorsqu'un événement surviendra. Par exemple, lorsqu'un fichier est enregistré sur un serveur de stockage HDFS.
La définition des DAG consiste donc à créer des tâches et les connecter entre elles. Une fois le DAG défini, il ne reste plus qu'à l'exécuter. Cette fois-ci encore, nous avons plusieurs choix avec Airflow.
Une liste des opérateurs présents nativement sous Airflow est disponible ici. Si un opérateur n'existe pas, il est possible soit d'utiliser un déjà créé par la communauté, soit de le construire soi-même par héritage d'un BaseOperator.
Pour s'exécuter correctement, Airflow nécessite deux programmes.
- Le Scheduler, qui est responsable de la planification de l'exécution des tâches vers l'exécuteur.
- Le Web Server, qui permet de lancer un processus Flask pour avoir accès à l'interface Web.
Avant de lancer ces deux programmes, nous devons effectuer quelques configurations.
Scheduler et Executors
Le Scheduler est le programme principe sur Airflow qui administre chaque workflow. C'est lui qui va gérer quels sont les DAGs qui sont en cours d'exécution, interagir avec la base de données (par défaut installée en local dans un format SQLite) et planifier les exécutions futures. Ce n'est en revanche pas lui qui exécute directement les tâches, mais les Executors.
Les Executors vont exécuter des instances de tâches automatiquement en local ou sur des serveurs distants (Workers). Il existe plusieurs types d'Executors sous Airflow.
- Le SequentialExecutor exécute des instances des tâches de manière séquentielle, les unes après les autres.
- Le LocalExecutor exécute des instances des tâches en parallèle sur la machine locale.
- Le CeleryExecutor exécute des instances des tâches en parallèle sur un serveur worker : c'est l'exécuteur à priviliger lorsque le scaling horizontal est indispensable.
- Le KubernetesExecutor exécute des instances des tâches dans des pods sur un cluster K8s.
Lorsque l'on exécute le LocalExecutor, il faut spécifier une base de données externe, car la base SQLite par défaut sur Airflow ne supporte pas les connexions multiples.
Le KubernetesExecutor devient intéressant lorsqu'il y a une charge de travail importante ou que beaucoup de job qui s'exécutent en parallèle, et d'après des sondages effectués auprès de la communauté, 40% des utilisateurs utilisent le KubernetesExecutor. Le LocalExecutor est intéressant dans le cas où l'on dispose que d'une seule machine qui exécute elle-même chaque job, et le SequentialExecutor uniquement lors des phases de développement.
Définition des séquences
Airflow s'utilise comme configuration en tant que code : les DAGs se définissent directement par des codes Python (là ou d'autres outils utilisent des langages descriptifs tels que XML ou YAML) ce qui facilite la mise en place des workflows par les développeurs. L'interface Web que nous utiliserons ne permettra pas de construire des séquences, mais uniquement d'effectuer des opérations d'administration et de surveillance.
À lire aussi : découvrez notre formation Data Engineer
Depuis la version 2.x.x, Airflow intègre une nouvelle façon de construire des DAGs avec l'API Taskflow, que nous allons voir dans la suite.

Quand utiliser Apache Airflow ?
Apache Airflow peut être utilisé dès qu'il faut automatiser des traitements.
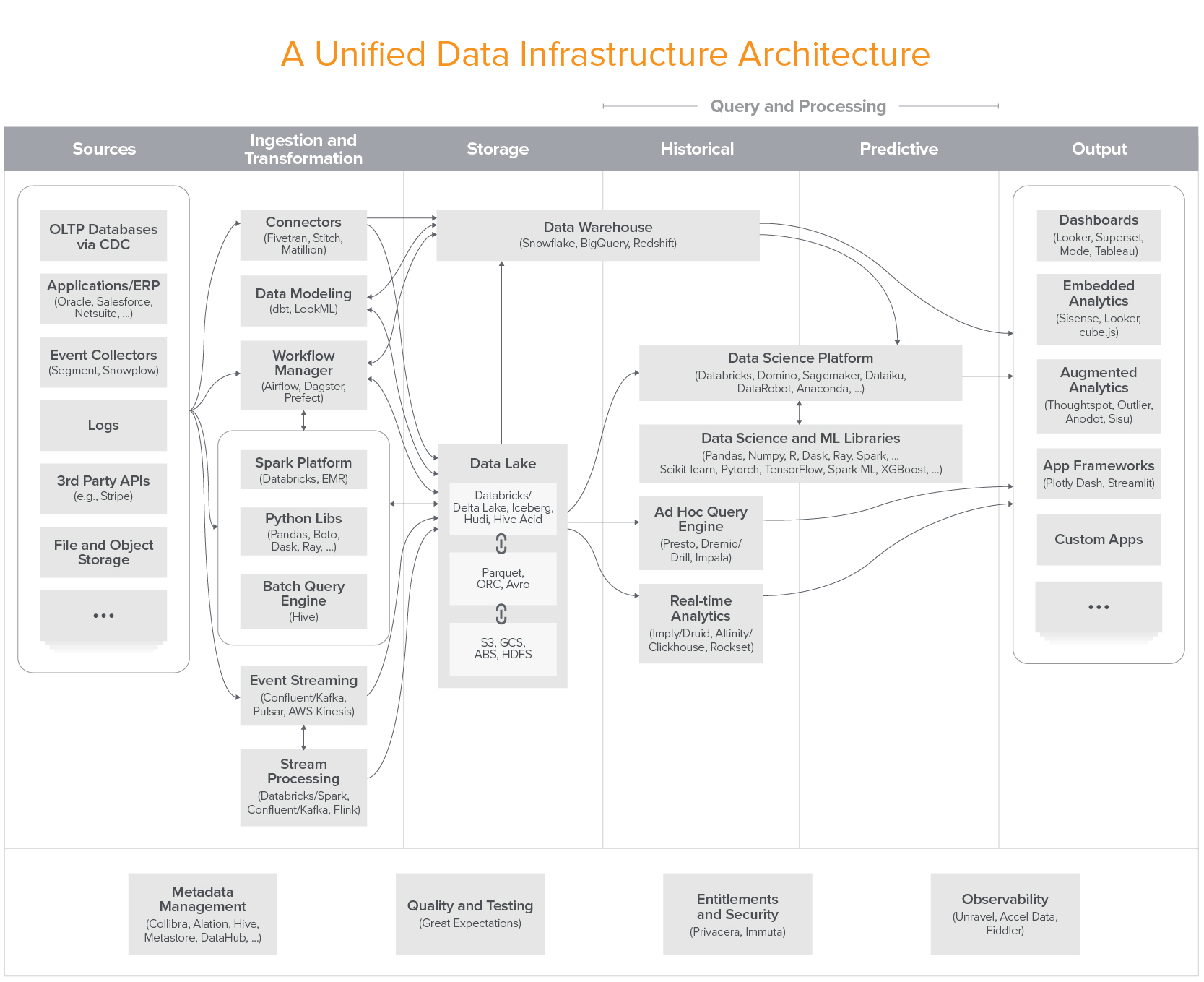
- Migration de données Data Lake - Data Warehouse : c'est sans doute le cas d'application phare d'Apache Airflow. Très souvent, les Data Engineers ont pour mission d'agréger et transformer des données brutes depuis un Data Lake, pour alimenter des Data Warehouses, qui sont plus structurés et orientés métiers. Ces Data Warehouses peuvent être utilisés plus facilement par des Data Scientists et des équipes opérationnelles (marketing, comptabilité) qui vont manipuler des données nettoyées, agrégés et historisés.
- Calcul distribué : corollaire de la première situation, Airflow est également adapté pour lancer des calculs distribués, notamment avec des outils comme Apache Spark. En effet, la plateforme dispose de nombreuses intégrations avec des fournisseurs Cloud (AWS, GCP, Azure) et des services en ligne, qui rendent facile leur intégration et leur utilisation. Par exemple, les opérateurs sont utilisés pour provisionner des clusters Spark depuis Airflow.
- Machine Learning et MLOps : par sa puissance de planification, Airflow est également utilisé par des Data Scientists qui souhaitent automatiser l'entraînement de modèles de Machine Learning. Cette approche est parfaitement adaptée à la plateforme, car les pipelines Machine Learning ne sont rien d'autres que des pipelines de données adaptées au Machine Learning.
- Sauvegardes et DevOps : la création automatisée de sauvegardes et toutes les tâches DevOps peuvent également être réalisées via Airflow.
Quand ne pas utiliser Apache Airflow ?
À l'inverse, il y a certaines situations où Apache Airflow ne va pas forcément être le meilleur choix. Dans, ce cas, il faut se tourner vers des alternatives plus adaptées à chaque situation.
- Déclenchements et flux en temps réel : par son caractère distribué, Apache Airflow peut prendre plusieurs secondes voir minutes à déclencher un traitement et exécuter les tâches. Ainsi, pour des situations où la latence doit être faible, Airflow ne convient pas pour des situations proches du temps réel. Pour cela, on préfèrera utiliser des solutions alternatives comme Prefect ou Argo.
- Automatisation du marketing : bien que cela peut être tentant, il faut éviter d'utiliser Apache Airflow pour des opérations de marketing. Pour des utilisateurs novices, Airflow est difficile à prendre en main, car il faut développer les pipelines en Python, ce qui empêche les équipes marketing de travailler la plateforme. On utilise plutôt des outils adaptés comme HubSpot pour du marketing automation.
Se former sur Apache Airflow
L'automatisation de pipelines de données concerne de nombreuses entreprises. Pour les Data Engineers, la maîtrise d'outils de planification comme Airflow est une compétence indispensable et nécessaire, et utilisé à tous les niveaux de l'entreprise.
La formation Data Engineer de Blent dispose de plusieurs modules et de contenus axés sur la maîtrise d'Apache Airflow, que ce soit sur l'installation en local/sur un serveur, la création et la configuration de pipelines, ou encore l'interaction avec des environnements Cloud.
Cette formation permet également de maîtriser les outils qui interagissent avec Apache Airflow, comme la création de clusters Spark sur Google Dataproc, ou l'entraînement automatisé de modèles de Machine Learning (MLOps), permettant au Data Engineer de mettre en production des pipelines dans n'importe quelle situation.
Vous souhaitez vous former au Data Engineering ?
Articles similaires

7 févr. 2024
Pendant de nombreuses années, le rôle des Data Engineers était de récupérer des données issues de différentes sources, systèmes de stockage et applications tierces et de les centraliser dans un Data Warehouse, dans le but de pouvoir obtenir une vision complète et organisée des données disponibles.
Maxime Jumelle
CTO & Co-Founder
Lire l'article

4 déc. 2023
Pour de nombreuses entreprises, la mise en place et la maintenant de pipelines de données est une étape cruciale pour avoir à disposition d'une vue d'ensemble nette de toutes les données à disposition. Un des challenges quotidien pour les Data Analysts et Data Engineers consiste à s'assurer que ces pipelines de données puissent répondre aux besoins de toutes les équipes d'une entreprise.
Maxime Jumelle
CTO & Co-Founder
Lire l'article

14 nov. 2023
Pour améliorer les opérations commerciales et maintenir la compétitivité, il est essentiel de gérer efficacement les données en entreprise. Cependant, la diversité des sources de données, leur complexité croissante et la façon dont elles sont stockées peuvent rapidement devenir un problème important.
Maxime Jumelle
CTO & Co-Founder
Lire l'article
60 rue François 1er
75008 Paris
Blent est une plateforme 100% en ligne pour se former aux métiers Tech & Data.
Organisme de formation n°11755985075.

Data Engineering
IA Générative
MLOps
Cloud & DevOps
À propos
Gestion des cookies
© 2025 Blent.ai | Tous droits réservés