Apache Spark : tout savoir sur le framework Big Data
Apache Spark est un framework Big Data de traitement de données open source à grande échelle. Il est particulièrement adapté pour les très grandes volumétries de données (plusieurs dizaines ou centaines de Go) et fonctionne de manière distribuée, sous forme de clusters. Son utilisation est principalement dédié aux applications du Machine Learning et des pipelines de données ETL.

Apache Spark est un framework Big Data de traitement de données open source à grande échelle. Il est particulièrement adapté pour les très grandes volumétries de données (plusieurs dizaines ou centaines de Go) et fonctionne de manière distribuée, sous forme de clusters. Son utilisation est principalement dédié aux applications du Machine Learning et des pipelines de données ETL.
Créé en 2009 par Matei Zaharia, Spark est aujourd'hui maintenu par l'entreprise Databricks. Sa popularité est telle que la plateforme figure parmi les compétences les plus demandées pour les Data Engineers. Faisons un zoom sur cette technologie de pointe.
Pourquoi Apache Spark ?
Avant de détailler Spark, il faut tout d'abord comprendre pourquoi a-t-on besoin du calcul parallèle.
Tous les programmes informatiques utilisent deux types de mémoires.
- La mémoire morte (souvent EEPROM) contient des données qui sont stockés même lorsqu'il n'y a pas de courant qui alimente le composant (disques durs ou SSD). Cette dernière permet de stocker de l'information tels que des fichiers.
- La mémoire vive, à l'inverse, contient des données volatiles qui disparaissent lorsque le composant n'est plus alimenté. C'est notamment dans celle-ci que sont stockées les variables des programmes et les pointeurs (références de variables).
Lorsque l'on réalise des transformations de données, c'est dans la mémoire vive que le résultat est stocké. Ainsi, nous sommes limités par la quantité de mémoire vive disponible lors des calculs.

Dès lors qu'un fichier va peser plusieurs Go sur le disque dur, la mémoire vive (souvent entre 8 et 16 Go) de l'ordinateur ou du serveur que l'on utilise va arriver à saturation : dans le meilleur des cas, le programme plante, mais dans le pire, c'est l'ordinateur lui-même !
Un fichier pèse entre 4 et 8 fois plus sur une mémoire vive que sur une mémoire morte.
À lire aussi : découvrez notre formation Data Engineer
Pour éviter cette situation, l'objectif du calcul parallèle est de dispatcher les données sur plusieurs serveurs au sein d'un cluster pour profiter de la mémoire vive disponible sur plusieurs machines.

Ainsi, un fichier de plusieurs dizaines de Go pourra se traiter de la même manière qu'un fichier de 1 Go, à la seule différence qu'il faudra plus de serveurs dans le cluster pour supporter la charge.
❓ Mais alors, comment fait-on pour faire un traitement avec plusieurs serveurs en parallèle ?
C'est là qu'interviennent deux frameworks Big Data très connus : Hadoop et Spark.
Hadoop vs Spark
Historiquement, c'est Apache Hadoop (donc de la même fondation) qui était la solution de choix pour le traitement de données Big Data. Nous pouvons citer ses 4 modules principaux.
- Core, qui contient toutes les fonctionnalités de base.
- HDFS, un système de stockage de fichiers distribués.
- YARN, pour gérer les ressources, monitorer et administrer les clusters.
- MapReduce, permettant d'élaborer des algorithmes selon l'architecture MapReduce.
C'est surtout le module MapReduce qui nous intéresse particulièrement. Il s'agit d'un patron d'architecture de programmation développé par Google, qui permet de concevoir des algorithmes adaptés au traitement distribué. En effet, lorsque les données sont traitées en distribuée, elles se retrouvent sur des machines différentes au sein d'un même cluster.
Comment garantir que certaines données présentent dans une machine A appartiennent au même groupe que d'autres données présentes dans une machine B ? Si par exemple, on fait un tri dans chacune des machines A et B, comment s'assurer que le résultat final (concaténation des résultats des deux machines) respecte bien le tri demandé ?
C'est justement ce que cherche à résoudre MapReduce. Pour cela, l'algorithme va décomposer le traitement sous forme de plusieurs étapes, et chaque étape va produire un fichier sur HDFS. En pratique, cette approche est lente, car les temps de lecture/écriture peuvent être important, car chaque étape est décomposé en une partie Map, et une partie Reduce.
Fonctionnement de Spark
Apache Spark est développé en Scala, mais dispose de wrappers dans plusieurs langages de programmation, dont Java, R et Python. Cela signifie que l'on peut interagir avec Spark dans ces langages, sans avoir besoin d'écrire un code en Scala, ce qui est pertinent pour des profils de Data Scientists qui ont plutôt l'habitude d'utiliser R ou Python.
En mode cluster, Spark utilise les principales composantes de gestion de clusters d'Hadoop, à savoir le système de stockage de fichiers HDFS, ainsi que YARN pour la gestion des ressources. En revanche, Spark a abandonné MapReduce, au profit d'une méthode bien plus efficace.
La grande nouveauté, c'est que Spark va prendre en charge le partage de données en mémoire. Profitant de la mémoire vive, cette dernière est 10 à 100 fois plus rapide que sur une mémoire morte type disque dur ou SSD.
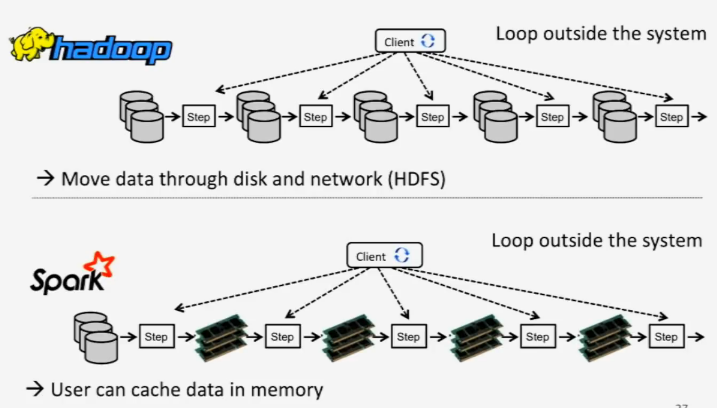
Autre différence de MapReduce, Spark cherche à proposer une API la plus simple d'utilisation pour travailler sur tous types de données. Pour cela, Spark propose plusieurs outils qui intègrent des API utilisables en Scala, Java, R et Python.
- Spark SQL pour effectuer des manipulations similaires aux requêtes SQL et adapté au cadre distribué.
- Spark Streaming pour transformer des données issues d'une source en temps réel.
- Spark MLlib pour construire des algorithmes distribués de Machine Learning.
- Spark GraphX pour les calculs sur graphes statistiques.
Enfin, Spark utilise une approche qualifiée d'évaluation paresseuse (lazy evaluation) : les calculs ne sont réellement effectués que lorsque l'on effectue des opérations de collecte de données. Cela permet alors à Spark de représenter les différentes transformations sous forme de tâches dans un graphe (appelé DAG). Cette représentation par graphe permet à Spark de reprendre certaines étapes et d'optimiser les calculs pour obtenir le résultat plus rapidement.
Spark n'est donc pas un concurrent d'Hadoop mais une alternative plus efficiente qui se repose sur les composantes YARN et HDFS de ce dernier.
Représentation des données
Sous l'environnement Spark, la représentation la plus abstraite des données est le Resilient Distributed Dataset (RDD). Il s'agit d'une collection d'éléments partitionnés sur les noeuds formant le cluster et donc les opérations ou transformations sont effectuées en parallèle. Ces derniers peuvent être créés à partir d'un fichier existant où directement en Python. Une des particularités des RDD est qu'ils sont en lecture seule : ce mécanisme permet de relancer un calcul précédent sans pour autant devoir relancer tous les calculs précédents (car cela pourrait prendre beaucoup de temps).
Apparu avec Spark, un Dataset est une collection de données distribuée qui offre l'avantage des RDD (fort typage par exemple) mais qui permet Bénéficiez également du moteur d'exécution de Spark SQL. C'est notamment avec cette dernière fonctionnalité que nous pourrons invoquer des traitements SQL-like en parallèle.
À lire aussi : découvrez notre formation Data Engineer
Enfin, le DataFrame est un Dataset organisé sous forme de colonnes, équivalant à une table dans un modèle relationnel. Il s'agit du format le plus adapté pour manipuler des données tabulaires, et ressemble fortement à ceux rencontrés sous R ou Python.
Un DataFrame Spark n'est pas un DataFrame
pandas: les fonctions que l'on utilisera seront différentes.
En résumé, Spark est un framework Big Data qui contient notamment un moteur d'exécution SQL permettant de manipuler des DataFrames distribués à grande échelle.
Pour se familiariser avec Spark SQL, nous allons reproduire les transformations réalisées avec pandas.
Quand doit-on utiliser Apache Spark ?
Apache Spark est une solution à privilégier dès lors que des transformations sont à appliquer sur des données qui pèsent plusieurs dizaines de Go : tout projet qui traite avec cette typologie est concerné.
- L'analyse de données est sans doute l'utilisation principale de Spark. Lorsque l'on doit extraire des informations depuis une vaste source, Spark permet d'avoir directement des résultats par des requêtes simples à formuler.
- Les pipelines ETL et les opérations d'agrégations ou de tri, car le modèle SQL de Spark va permettre d'exécuter des opérations SQL-like (similaire à celle que l'on retrouve sur les DataFrames) de manière simple et claire.
- L'entraînement de modèles de Machine Learning, car par nature, certains algorithmes de Data Science peuvent être entraînés en parallèle : c'est le cas par exemple des Random Forest.
- La migration et l'insertion de données, lorsqu'il faut récupérer des données depuis une base source ou depuis un système de stockage de fichiers, pour ensuite les envoyer vers un autre système cible. C'est le cas lorsque l'on requête sur des bases distribués comme Cassandra ou MongoDB.
Quand ne faut-il pas utiliser Apache Spark ?
À l'inverse, il y a certaines situations où Spark ne doit pas être utilisé, soit parce qu'il n'est adapté, soit pire encore, parce que l'utiliser va être moins efficace dans son projet.
- Le traitement en temps réel n'est pas un cas d'usage adapté pour Spark. Par son fonctionnement et ses nombreuses opérations de lecture/écriture, le temps réel ne peut être garanti, car les jobs sont qualifiés de batch-oriented, c'est-à-dire pour un traitement par batch, à froid. Pour une utilisation temps réel, on se dirigera plutôt vers des solutions comme Apache Kafka, Apache Flink ou encore Apache Storm.
- Les données de faible volumétrie ne devraient pas être transformées via Spark. En effet, si l'on souhaite traiter un fichier qui ne pèse que quelques centaines de Mo, alors il est plus judicieux d'utiliser un serveur classique avec du Python et du
pandasinstallé dessus, qui sera beaucoup plus simple à mettre en place.
Se former sur Apache Spark
Aujourd'hui, il est indispensable pour tout Data Engineer de maîtriser Apache Spark. De très nombreuses entreprises ont des besoins importants en traitement Big Data, bien avant que les besoins Data Science apparaissent. On retrouve donc cette plateforme chez les entreprises de toutes tailles, des startups jusqu'aux multinationales.
La formation Data Engineer de Blent permet de maîtriser l'ensemble des composantes d'Apache Spark, donc l'outil Spark SQL pour manipuler des DataFrames distribués ou Spark Streaming pour traiter à la volée des données issues d'une source qui produit en continu. La formation s'adresse aux développeurs ou Data Scientists qui souhaitent maîtriser les compétences du traitement Big Data.
La formation présente aussi d'autres solutions Big Data nécessaires à Spark, comme les outils Dataproc qui proposent des clusters managés dans le Cloud, permettant ainsi de travailler directement sur des grandes quantités de données sans complexité technique.


