BigQuery : le Data Warehouse de Google
Google BigQuery est un Data Warehouse en ligne qui permet aux utilisateurs de stocker, analyser et visualiser des données volumineuses. BigQuery offre une interface web pour executer des requêtes SQL sur les données stockées, ainsi qu'une API pour intégrer BigQuery à d'autres applications.

Google BigQuery est l'une des bases de données Cloud les plus populaires. Intégrée à Google Cloud Platform, elle est rapidement devenue une solution incontournable pour de nombreuses entreprises qui souhaitent stocker, historiser et effectuer des requêtes sur des données structurées et volumineuses, sans avoir à gérer de serveur ou une quelconque infrastructure.
Mais pourquoi BigQuery est-elle devenue aussi populaire ? Au cours de cet article, nous allons en détailler les principales composantes, les avantages et les comparaisons avec d'autres services similaires.
Google BigQuery : qu'est-ce que c'est ?
Google BigQuery est un Data Warehouse en ligne qui permet aux utilisateurs de stocker, analyser et visualiser des données volumineuses. BigQuery offre une interface web pour executer des requêtes SQL sur les données stockées, ainsi qu'une API pour intégrer BigQuery à d'autres applications.
Cette base est entièrement gérée, ce qui signifie qu'il n'y a pas besoin de provisionner ou de s'occuper l'infrastructure serveur qui héberge la plateforme.
Composantes de Google BigQuery
Datasets et Tables
Les Datasets de BigQuery sont des groupes logiques de tables. Ce sont les conteneurs de données qui peuvent être partagés avec d’autres utilisateurs et disposer de contrôles d’accès.
Les Tables de BigQuery sont des groupes logiques de données qui ont une structure clairement définie grâce à un schéma. Les tables peuvent être chargées à partir de n’importe quel format, y compris les fichiers JSON, CSV, AVRO, Parquet et ORC.
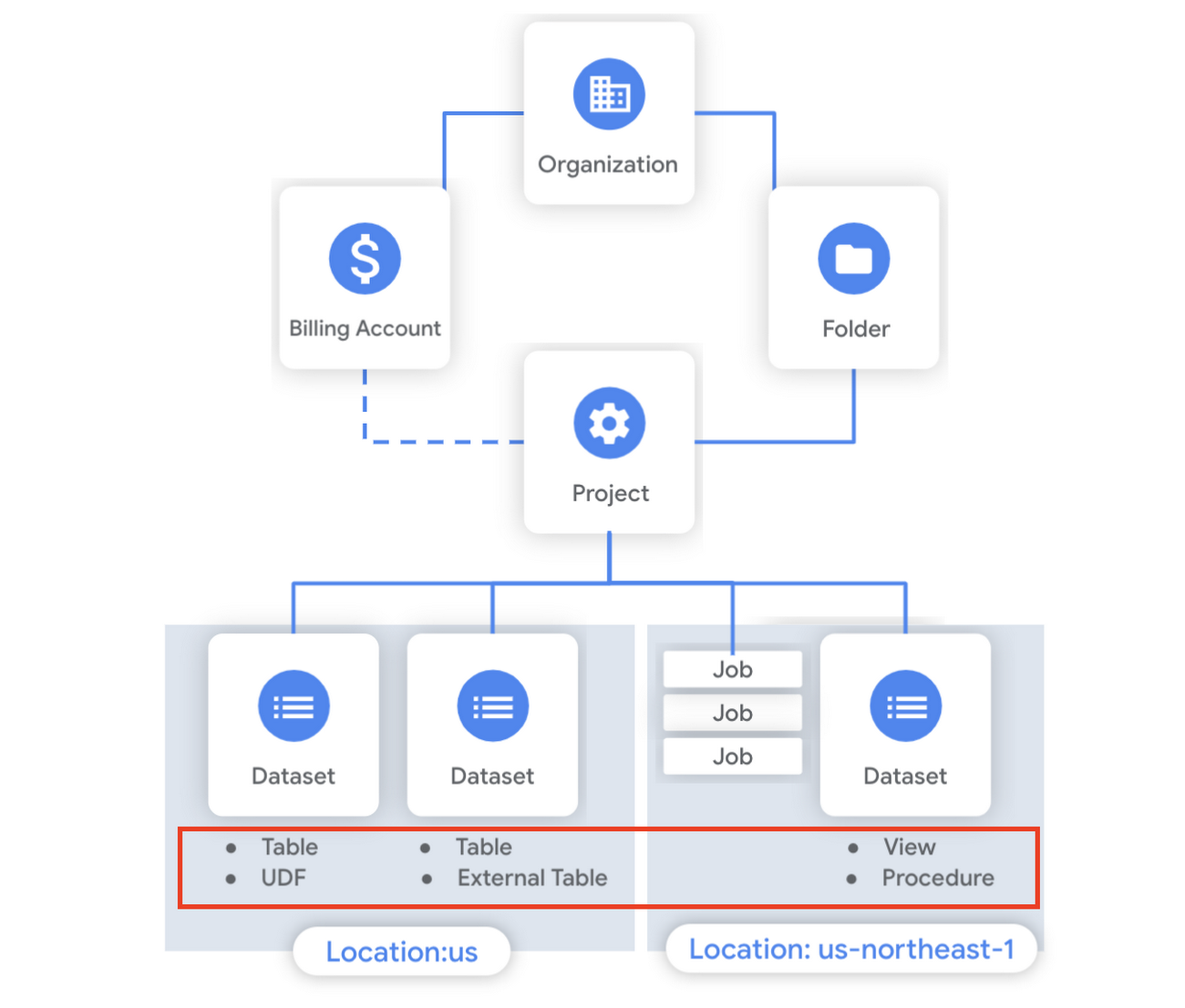
Chaque table est associée à un schéma qui définit la structure des données d’une table. Il est composé de champs définissant le type de données stockées dans la table. Ce principe est donc très similaire à celui des bases SQL plus classiques du modèle relationnel.
Moteur de requête
Google BigQuery utilise un moteur de requête SQL pour extraire les données des tables. Ce moteur permet d’exécuter des requêtes SQL sur les données stockées dans les tables, offrant ainsi une plus grande facilité d'extraction et de traitement sur des données qui peuvent être conséquences.
Ces requêtes peuvent être exécutées via une interface utilisateur Web. Cette interface permet de charger et de manipuler les données, de gérer les utilisateurs ou les autorisations. Mais BigQuery fournit également une API REST pour l'exécution de requêtes SQL à distance.
À lire aussi : découvrez notre formation Data Engineer
Ces requêtes sont ensuite converties sous forme de jobs. Les jobs sont des tâches qui sont exécutées sur les données stockées. Ces tâches peuvent inclure le chargement de données, la transformation de données, l’exécution de requêtes SQL ou l’exportation de données.
Performances de Google BigQuery
BigQuery offre une excellente performance grâce à sa architecture distribuée. Les données sont stockées sur plusieurs serveurs afin de répartir la charge de travail. Cette architecture permet également de tolérer les erreurs et les pannes de serveur.
BigQuery utilise également une technique de partitionnement des données pour améliorer la performance. Les données sont réparties entre plusieurs partitions afin de réduire la charge de travail sur chaque serveur. Cela permet également de tolérer les erreurs et les pannes de serveur.
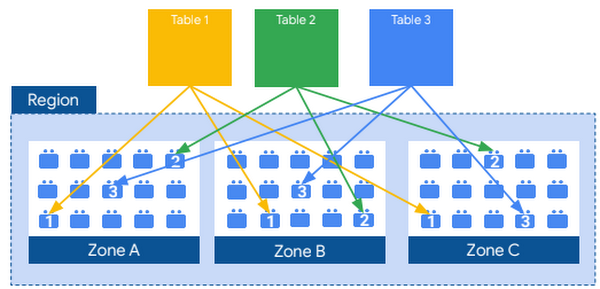
Enfin, le Data Warehouse de Google utilise une technique de compression des données pour réduire la taille des tables. Cette technique permet ainsi de lancer des requêtes dessus et de les charger plus rapidement.
Coûts de Google BigQuery
Un des principaux avantages de BigQuery est que le coût est directement liée de manière croissante au stockage et aux requêtes. Ainsi, si l'on ne stocke que quelques Mo ou Go, le coût de stockage sera très faible (quelques centimes de dollars).
Au niveau du stockage, Google propose 10 Go gratuitement tous les mois. Au-delà de 10 Go de données stockées dans les tables, la facturation s'élève à 2 centimes de dollars par mois. Pour les requêtes, le premier To de données analysés est gratuit. Ensuite, chaque To analysé s'élève à 5 dollars.
Ainsi, si une entreprise doit stocker 500 Go de données, et qu'elle effectue 10 To d'analyses par mois, alors le coût mensuel est de $10 pour le stockage et $50 pour les requêtes, soit $60 en tout.
Avantages de Google BigQuery
Il y a de nombreux avantages qui surviennent lorsque l'on utilise cette solution.
- Google BigQuery est intégrée et utilisable dans Google Cloud Platform, ce qui rend l'intégration avec les autres services beaucoup plus facile.
- Un très grand nombre d'outils (propriétaires ou open source) disposent d'intégrations ou de connecteurs permettant de charger et envoyer des données de manière totalement transparante.
- En théorie, BigQuery fournit une capacité de stockage illimitée et une analyse interactive des données, ce qui lève les contraintes de dimensionnement de serveur. Par ailleurs, cette plateforme peut être qualifiée de serverless, car en tant qu'utilisateur, il n'y a aucune infrastructure à gérer.
- Les requêtes sont plus faciles car elles peuvent être rédigées en SQL et sont optimisés pour une grande volumétrie.
À l'inverse, il y a tout de même certains inconvénients en comparaison avec d'autres solutions existantes qui sont Redshift pour AWS et Azure SQL Data pour Microsoft. Est-ce que Google BigQuery est mieux que ces deux autres solutions ?
À lire aussi : découvrez notre formation Data Engineer
Il n'y a pas de réponse définitive à cette question, car cela dépend des besoins spécifiques de l'utilisateur. Cependant, les avantages généraux d'Amazon Redshift incluent sa capacité à monter en charge rapidement et facilement, son support pour une large gamme de formats de données et son intégration avec d'autres services Amazon.
De même, dans l'ensemble, BigQuery est un meilleur choix pour les entreprises qui ont besoin d'analyser de grands ensembles de données, tandis que Azure SQL Data est un meilleur choix pour les organisations qui ont besoin de prendre en charge des requêtes complexes ou qui ont un budget limité.


