Terraform : automatiser son infrastructure Cloud
Construire une infrastructure Cloud peut vite devenir difficile à gérer pour toute une équipe, surtout si elle doit faire des modifications sur plusieurs services à la fois. C'est là qu'intervient Terraform, un outil d'Infrastructure-as-Code très populaire qui permet de construire et déployer toute une infrastructure Cloud à l'aide de fichiers de configuration.

Construire une infrastructure Cloud n'est pas de tout repos. Il faut configurer les réseaux (sous-réseaux, passerelles Internet et NAT), provisionner des serveurs, exécuter des bases de données et configurer toute une couche de sécurité. Cela peut vite devenir difficile à gérer pour toute une équipe, surtout si elle doit faire des modifications sur plusieurs services à la fois.
C'est là qu'intervient Terraform, un outil d'Infrastructure-as-Code très populaire qui permet de construire et déployer toute une infrastructure Cloud à l'aide de fichiers de configuration.
Mais comment fonctionne Terraform ? Avec quels fournisseurs Cloud fonctionne-t-il ? Quelles sont ses fonctionnalités ? Nous allons découvrir tout cela dans cet article.
Histoire de Terraform
Terraform est un outil open source développé depuis 2014 par la société HashiCorp. Il a très rapidement connu un grand succès car son utilisation est essentielle : automatiser le provisionnement et la gestion des ressources Cloud.
La définition d'une infrastructure s'effectue de manière descriptive dans plusieurs fichiers de configuration, à l'aide d'un langage spécialement développé, le HCL (HashiCorp Configuration Language). Lorsque ces fichiers sont créés, ils peuvent ensuite être exécutés à l'aide d'une interface en ligne de commandes (CLI), qui va récupérer l'ensemble des définitions établies dans les fichiers.
Ces fichiers peuvent contenir tout type de ressource, tant qu'elle est prise en charge par le fournisseur Cloud. Il peut s'agir de serveurs, de bases de données, mais aussi d'entités réseaux, des utilisateurs Cloud ou des règles de pare-feu.
Par exemple, le code Terraform suivant permet de créer une machine virtuelle sur Google Cloud, en spécifiant différents paramètres (le type de machine, la zone, le système d'exploitation, etc).
resource "google_compute_instance" "default" {
name = "server"
machine_type = "e2-medium"
zone = "us-central1-c"
boot_disk {
initialize_params {
image = "debian-cloud/debian-10"
}
}
network_interface {
network = "default"
access_config {}
}
metadata = {
ssh-keys = "admin:${file("ssh_key.pub")}"
}
}
json
À noter que dans une certaine mesure, Terraform supporte également le format JSON, bien qu'il soit conseillé d'opter en faveur de HCL si possible.
Providers Terraform
Si Terraform est aussi populaire, c'est parce qu'il dispose d'un grand nombre de providers. Mais à quoi sert un provider ?
Définition d'un provider
Lorsque l'on doit créer une ressource dans un Cloud par exemple, il faut utiliser l'API exposée par ce même fournisseur Cloud pour pouvoir provisionner une nouvelle ressource de manière automatisée. Or, chaque fournisseur Cloud dispose de ses propres types de ressources, et donc de sa propre API.
En théorie, il faudrait donc soi-même configurer Terraform de sorte à ce que chaque ressource puisse être associé à une API d'un Cloud, ce qui est évidemment très long à faire : c'est là qu'interviennent les providers.
Un provider fournit une interface de communication entre nos fichiers de configuration Terraform et le Cloud sur lequel on souhaite provisionner des ressources. Ainsi, nous n'avons pas besoin d'utiliser nous-même l'API du Cloud, car le provider va faire cette connexion à notre place.
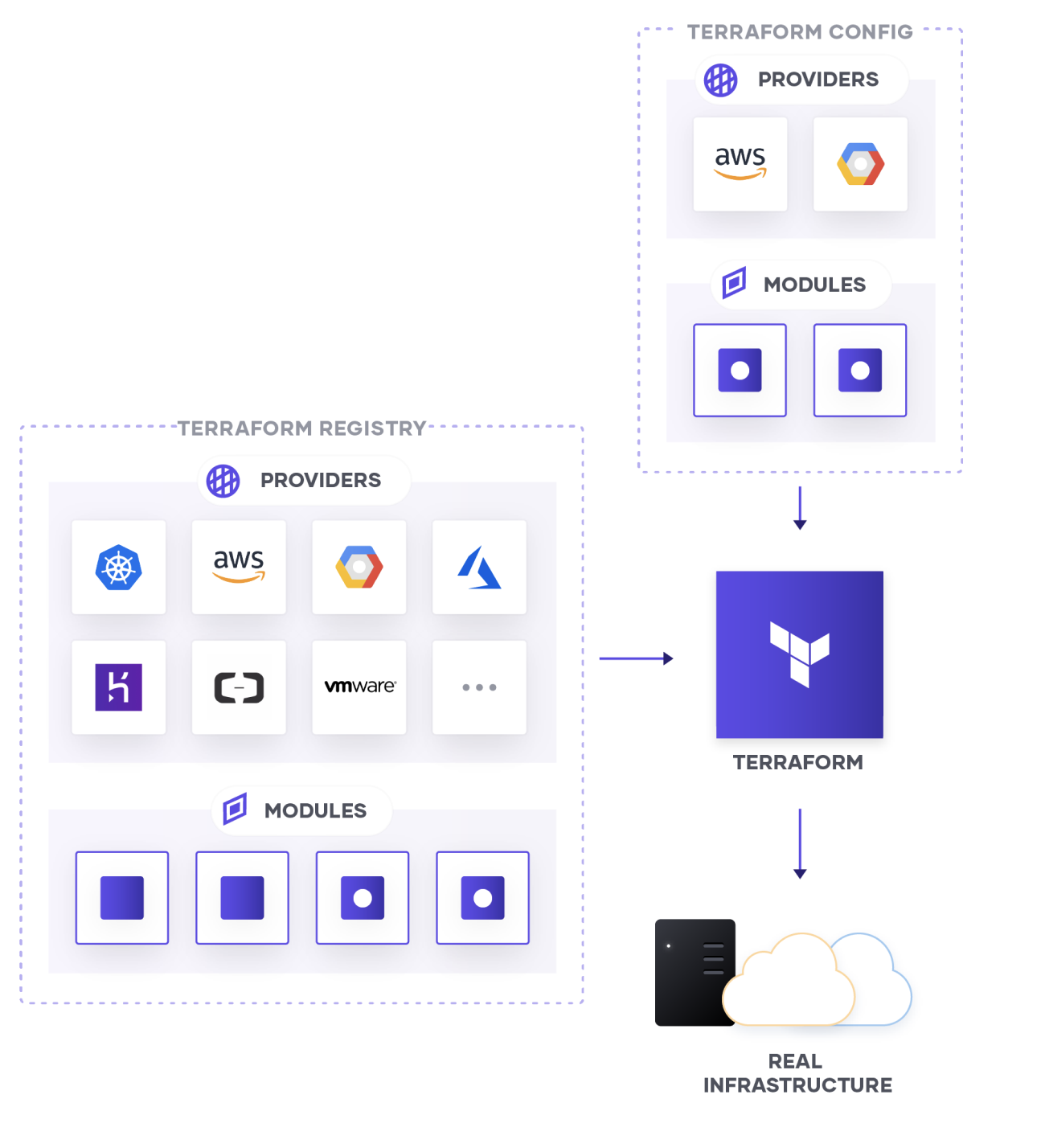
Parmi les providers les plus populaires, on retrouve bien sûr les fournisseurs Cloud comme Amazon Web Services, Google Cloud Platform ou Microsoft Azure. Mais d'autres providers pour VMware, Kubernetes et bien d'autres sont également disponibles.
Installer un provider
Tout d'abord, pour installer un provider, nous pouvons ajouter un nouveau bloc provider en spécifiant le nom associé. Ici, puisque nous allons utiliser Google Cloud Platform, nous allons utiliser le provider google.
provider "google" {
region = "us-central1"
project = "<PROJECT_GCP>"
credentials = "${file("credentials.json")}"
}
json
Pour chaque provider, il est important de pouvoir s'authentifier. Dans le cas de Google, cela s'effectue avec le paramètre credentials qui indique le chemin d'accès à une clé de compte de service, mais chaque provider aura son propre mécanisme d'authentification.
Une fois effectué, il suffit d'exécuter la commande terraform init qui va initialiser l'environnement local et télécharger le ou les providers renseignés.
Nous pouvons voir apparaître un nouveau fichier : terraform.tfstate . Ce fichier, comme son nom l'indique, contient l'état actuel de l'infrastructure provisionnée avec Terraform. Ainsi, ce fichier sert de référence à Terraform pour savoir quelles sont les ressources en cours d'exécution et quel est l'historique.
Déploiement d'une infrastructure
Lorsque l'on souhaite appliquer les modifications apportées dans les fichiers de configuration sur l'infrastructure cible, on utilise la commande terraform apply. En appelant cette commande, Terraform ne vas pas directement déployer les ressources : il va toujours nous afficher quelles vont être les modifications (nouvelles ressources, modifications de paramètres ou suppressions).
Pour appliquer directement, on peut utiliser également l'argument -auto-approve, qui ne va pas nous demander de confirmation et déployer directement.
À l'inverse, la commande terraform destroy va supprimer toutes les ressources connues de Terraform. Dans certaines situations, on ne souhaite supprimer qu'une partie des ressources : avec la commande -target type_resource.nom, nous pouvons spécifier une ressource particulière à supprimer.
Gestion de l'infrastructure existante
Comme nous venons de le voir, Terraform conserve l'état de l'infrastructure actuel dans un fichier. Deux questions surviennent alors.
- Terraform peut-il importer des ressources existantes ?
- Comment Terraform peut-il détecter une modification est apportée sur l'infrastructure existante, en dehors de Terraform ?
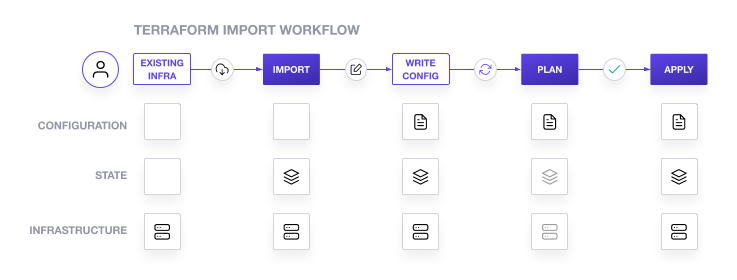
Importation de ressources
Terraform dispose d'une fonctionnalité très puissante qui permet d'importer des ressources déjà existantes depuis l'infrastructure. Il va alors cartographier l'infrastructure existante et tenter d'importer l'ensemble des
À l'heure actuelle, Terraform n'est pas encore capable d'écrire les fichiers de configuration associés à l'infrastructure importée. L'importation va seulement permettre de relier et d'associer une ressource déjà définie dans Terraform, avec une ressource existante dans le Cloud.
Grâce à la commande terraform import, ce dernier va tenter de relier les ressources existantes. Il est possible de spécifier spécifiquement une ressource en utilisant l'option -target.
terraform import -target google_compute_instance.default <NOM_RESSOURCE>
bash
Drift d'infrastructure
Lorsque l'on modifie la configuration Terraform de son infrastructure, ce dernier va automatiquement détecter les différences entre ce qui est demandé et ce qui est réellement exécuté. En réalité, Terraform utilise un système qui vise à identifier l'état actuel de l'infrastructure, et cherche à obtenir un état désiré.
L'intérêt pour lui est de comprendre quelles sont les actions à mettre en oeuvre pour obtenir le nouvel état désiré : faut-il juste modifier des paramètres d'une ressource, ou faut-il la détruire complètement pour en recréer une nouvelle ? Toutes ces opérations sont directement gérées par Terraform, ce qui nous évite de devoir nous même penser aux actions à déployer pour obtenir l'état désiré de notre infrastructure.
Cette notion d'état désiré est très importante, car Terraform considère que l'état qu'il a en connaissance est l'état actuel de l'infrastructure. Ainsi, deux cas de figure peuvent se produire.
- Une ressource, déjà ciblée par Terraform, a été modifiée indépendamment par un utilisateur. Dans ce cas, en déployant à nouveau, Terraform écrasera les modifications apportées en dehors de ce dont il a connaissance. Par exemple, si l'on a modifié les ressources d'un serveur à la main, alors au prochain déploiement, les anciennes ressources du serveur seront appliquées à nouveau.
- Une ressource a été créée en dehors de Terraform. Dans cette situation, la seule possibilité pour prendre en compte cette ressource dans l'état consiste à l'importer, car les actions de déploiement n'affecterait pas cette ressource.
Dans les deux situations, on appelle cela un drift, c'est-à-dire un décalage entre ce que Terraform connait, et ce qu'il y a réellement dans l'infrastructure. Ce drift peut être détecté et même corrigé si nécessaire.
Pour cette raison, lorsque l'on souhaite terraformer une partie de l'infrastructure, on essaie au maximum de tout centraliser sous forme de fichiers pour éviter de « rater certaines ressources ».
Quand utiliser Terraform ?
De manière générale, Terraform est un bon choix dès lors que l'on souhaite adopter les bonnes pratiques en termes d'architecture Cloud.
- Lorsqu'il faut automatiser la création de ressources, comme la création de clusters ou le provisionnement de tout un écosystème d'une application (serveur, base de données, autorisations IAM). Terraform va permettre de réaliser toutes ces actions en simultané, ce qui sera beaucoup plus rapide à effectuer.
- Pour mettre en place un système de versions d'infrastructure, l'association avec Git permet de gérer plusieurs versions en utilisant les commits et branches de Git.
- En phase de développement et de tests, Terraform associé avec un outil d'administration à distance comme Ansible ou Chef, permettrait de construire un environnement de test et de le supprimer à tout moment. L'objectif serait de provisionner un environnement pendant le développement, tout en optimisant au maximum les coûts, car il pourrait être supprimé lorsque les développeurs ou architectes Cloud ne travaillent plus dessus (week-end par exemple).
- Pour des raisons d'audit, si tout est limité à l'utilisation de Terraform, on peut facilement construire des audits sur les actions qui ont été entreprises via l'outil, ce qui pourrait être plus difficile via les consoles Web.
Pour toutes ces raisons évoquées, Terraform est un allié indispensable pour mettre en place une vraie stratégie d'Infrastructure-as-Code. Bien entendu, à lui seul, il ne permettrait pas de toute faire, car il va seulement provisionner l'infrastructure : certaines configurations, comme les installations sur les serveurs, doivent être réalisées via d'autres outils. Néanmoins, Terraform est une excellente base et un premier pas vers l'automatisation d'architectures Cloud.


