Apache Parquet : tout savoir sur ce format de données
Apache Parquet est un format de fichier open-source pour le stockage de données volumineuses dans un environnement Big Data. Ce format est très apprécié des Data Engineers, car il a été conçu pour répondre aux besoins de stockage et de traitement de données massives avec une efficacité maximale en termes de performance, de compression et de flexibilité du schéma de données.

Apache Parquet est un format de fichier open-source pour le stockage de données volumineuses dans un environnement Big Data. Ce format est très apprécié des Data Engineers, car il a été conçu pour répondre aux besoins de stockage et de traitement de données massives avec une efficacité maximale en termes de performance, de compression et de flexibilité du schéma de données.
Apache Parquet est compatible avec de nombreux langages de programmation et peut être utilisé avec différents frameworks Big Data courants tels que Apache Hadoop, Apache Spark et Apache Hive. Les fichiers Parquet peuvent être stockés sur un système de fichiers distribué tel que Hadoop Distributed File System (HDFS).
Dans cet article, nous allons voir comment Apache Parquet est devenu si populaire grâce à sa structure sous forme de colonnes rendant son utilisant beaucoup plus efficace que des fichiers CSV.
Origine d'Apache Parquet
Apache Parquet a été développé à l'origine par Cloudera et Twitter en 2013, avant d'être offert à la fondation Apache en 2014 en tant que projet open-source. Les développeurs ont créé ce format de fichier pour répondre aux besoins de stockage et de traitement de données volumineuses dans un contexte de forte volumétrie de données.
Tout d'abord, ils ont constaté que les formats de fichier traditionnels comme le CSV, JSON ou même Avro avaient des limites en termes de performances et de scalabilité, notamment en ce qui concerne la compression de données et la gestion de schémas complexes. Apache Parquet fut alors conçu pour résoudre ces problèmes en utilisant une structure de fichier sous forme de colonnes et en prenant en charge une compression efficace des données et un schéma de données flexible.
Depuis lors, Parquet a été adopté par de nombreux acteurs de l'écosystème Hadoop et est devenu un format de fichier couramment utilisé dans les environnements Big Data.
Structure des fichiers Parquet
La structure de fichiers Apache Parquet est un élément clé de son architecture. Elle est conçue pour permettre une lecture et une écriture sélective efficace des données stockées dans des fichiers Parquet.
Blocs de données
Tout d'abord, dans chaque fichier Parquet, on retrouve l'en-tête de fichier (header) quit contient des informations sur la version de Parquet, le schéma de données et les métadonnées du fichier. Cela inclut notamment des informations sur la compression utilisée pour stocker les données dans le fichier.
À lire aussi : découvrez notre formation Data Engineer
Ensuite, nous retrouvons les blocs de données sont la plus petite unité de données stockée dans un fichier Parquet. Chaque bloc de données contient un ensemble de valeurs pour chaque colonne du fichier. Les blocs de données peuvent être compressés et stockés indépendamment les uns des autres, ce qui permet une lecture sélective efficace des données.
Ces blocs sont ensuite regroupés dans des pages de données pour améliorer l'efficacité de la compression de données. Une page de données peut contenir plusieurs blocs de données pour une colonne donnée. Enfin, comme évoqué plus haut dans un souci de scalabilité, les fichiers de données Parquet sont divisés en plusieurs fichiers, chacun contenant un ensemble de pages de données pour chaque colonne du fichier. Chaque fichier de données contient également un fichier de métadonnées qui lui est propre, et qui décrit le schéma de données et les métadonnées pour les pages de données stockées dans ce fichier.
Colonnes
Avec Parquet, les données sont stockées sous forme de colonnes. Cela signifie que chaque colonne de données est stockée dans un fichier séparé. Cette structure permet une lecture sélective efficace des données en ne lisant que les colonnes nécessaires pour une requête donnée.
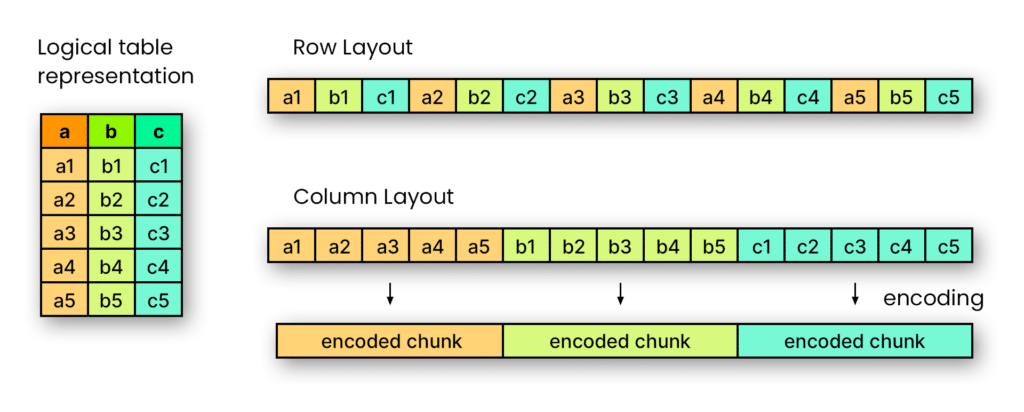
Cette structure de fichiers sous forme de colonnes permet également de supporter une compression efficace des données. Les valeurs d'une même colonne ont tendance à être similaires, ce qui rend la compression plus efficace que la compression de données basée sur les lignes. Parquet prend en charge plusieurs algorithmes de compression pour réduire la taille des données stockées, tels que Gzip, Snappy et LZO.
De plus, la structure de colonnes permet de lancer des calculs de traitement parallèle efficace des données. Les blocs de données pour chaque colonne peuvent être lus ou écrits de manière indépendante, ce qui peut améliorer les performances pour les tâches de traitement de données massives.
Schémas de données
Une des grandes forces de Parquet est aussi sa capacité à décrire un schéma de données dans les fichiers (stocké dans les métadonnées).
Le schéma de données Parquet prend en charge plusieurs types de données tels que les types primitifs (entiers, nombres, binaires), les types de données complexes (objets, tableaux), les types de données temporelles, etc.
Le schéma est validé au moment de l'écriture et de la lecture des données pour s'assurer que les données sont conformes au schéma défini. Cela permet donc d'éviter au programme d'inférer sur les types de données, comme le fait certaines librairies comme Spark ou Pandas sur des fichiers CSV. Cela aide à détecter les erreurs de données et à garantir la qualité des données tout au long de l'utilisation des fichiers.
Les schémas de données peuvent être étendus ou modifiés avec le temps sans avoir à réécrire l'ensemble des données. Cela peut s'avérer très pratique si l'on doit effectuer des conversions explicites sans avoir à modifier l'intégralité des données qui peuvent s'avérer conséquentes dans un contexte Big Data.
Avantages et inconvénients d'Apache Parquet
Apache Parquet présente de nombreux avantages en pratique.
- Ce format est particulièrement efficace pour le stockage, car la structure de fichiers sous forme de colonnes permet une compression efficace des données, car les valeurs d'une même colonne sont similaires. Cela permet en particulier de réduire la taille des données stockées et de minimiser les coûts de stockage.
- Également, Parquet apporte une efficacité de traitement grâce à une lecture sélective efficace des colonnes de données, ce qui peut améliorer considérablement les performances pour les requêtes qui ne nécessitent que certaines colonnes.
- Le schéma de données est flexible et évolutif, ce qui permet de stocker des données avec des schémas complexes. Il peut gérer des schémas de données évolutifs, tels que les structures de données imbriquées et les listes.
- La compatibilité avec de nombreux langages de programmation tels que Java, Python ou encore C++ permet aux développeurs de travailler dans différents langage de programmation en fonction des besoins de chaque projet.
- Apache Parquet dispose de nombreuses intégrations avec des outils Big Data courants comme Apache Hadoop, Apache Spark et Apache Hive.
- Enfin, il est l'avantage d'être interopérable : il est notamment compatible avec des systèmes de fichiers distribués tels que Hadoop Distributed File System (HDFS) ou Amazon S3.
Bien que Parquet dispose de nombreux avantanges, il y a tout de même certaines limites à prendre en compte, et qui peuvent s'avérer être des contraintes.
À lire aussi : découvrez notre formation Data Engineer
La première limite est liée à la structure du fichier Parquet elle-même. En effet, la représentation sous forme de colonnes peut être plus complexe que les formats de fichiers traditionnels comme CSV ou JSON. Il s'agit donc d'un format plus délicat à gérer et moins accessible que pour ces précédents formats de données.
De plus, bien que Parquet soit efficace pour la lecture sélective et le traitement parallèle des données, l'écriture de données dans des fichiers Parquet peut prendre plus de temps que dans des formats de fichiers traditionnels. Cela peut être un inconvénient pour les cas d'utilisation où la vitesse d'écriture de données est critique.
Enfin, dans certaines situations, Parquet peut nécessiter des ressources en mémoire pour la compression et la décompression de données, dépendant alors des configurations de serveur appropriées pour les environnements de traitement de données massives.
Globalement, Apache Parquet reste tout de même un format de données très apprécié et préféré par rapport aux formats traditionnels CSV ou JSON dans les infrastructures Big Data.