Auto-encodeurs en Deep Learning : tout savoir
Un auto-encodeur est une structure de réseaux neuronaux profonds qui s'entraîne pour réduire la quantité de données nécessaires pour représenter une donnée d'entrée. Ils sont couramment utilisés en apprentissage automatique pour effectuer des tâches de compression de données, d'apprentissage de représentations et de détection de motifs.

Les données bruitées sont encore l’un des problèmes d’apprentissage automatique les plus courants des Data Scientists. Heureusement, nous avons maintenant accès à un large éventail de technologies et de techniques qui permettent de résoudre plus efficacement les problèmes de compression des données : un auto-encodeur est l’un d’entre eux.
Un auto-encodeur est une structure de réseaux neuronaux profonds qui s'entraîne pour réduire la quantité de données nécessaires pour représenter une donnée d'entrée. Ils sont couramment utilisés en apprentissage automatique pour effectuer des tâches de compression de données, d'apprentissage de représentations et de détection de motifs.
Dans cet article, nous allons introduire les auto-encodeurs et leur architecture, les cas d'usage et les types. Nous allons également appliquer un auto-encodeur simple pour une tache d'encodage de données de type image.
Qu'est-ce qu'un auto-encodeur ?
Les auto-encodeurs sont des réseaux de neurones un peu particuliers, qui possèdent exactement le même nombre de neurones sur leur couche d’entrée et leur couche de sortie. Le but d'un auto-encodeur est d’avoir une sortie la plus proche possible de l’entrée. L’apprentissage est donc auto-supervisé car la perte à minimiser est le coût de reconstruction entre la sortie et l’entrée. Les données n’ont ainsi pas à être labellisées, parce qu'elles sont leurs propres labels, ce qui fait alors de ce modèle un modèle non supervisé.
Supposons que nous avons une image 100 x 100 avec laquelle nous voulons alimenter un encodeur pour réduire ses dimensions de manière appropriée. Sur l’espace de dimension de 10000 pixels, disons seulement 1000 de ces composants sont des données contenant les informations les plus utiles et décisives, en d’autres termes, des données représentatives de cette image. L’espace dimensionnel latent de l’encodeur automatique sera constitué de cet espace de dimensions inférieures avec les informations les plus utiles pour la reconstruction.
À lire aussi : découvrez notre formation MLOps
La tâche du décodeur dans l’auto-encodeur est de reconstruire ces nouvelles données à partir de l’espace de dimension latente existant. Par conséquent, les données régénérées sont une reconstruction efficace de l’échantillon original, malgré la perte de certaines informations dans le processus. Contrairement aux réseaux antagonistes génératifs (GANs), qui génèrent des données complètement nouvelles, les auto-encodeurs n'ont pas la même fonction.
Dans la plupart des cas, nous nous préoccupons principalement de tirer parti de l’encodeur et de l’espace dimensionnel latent pour une variété d’applications. Il s’agit notamment de la dénotation d’une image, de la détection d’anomalies et d’autres tâches similaires. Le décodeur est généralement une voie pour nous de visualiser la qualité des sorties reconstruites. Les auto-encodeurs peuvent être considérés comme une version plus intelligente des techniques de réduction de la dimensionnalité, telles que l’analyse des composants principaux (PCA).
Architecture d'un auto-encodeur
Un auto-encoder a une architecture très spécifique, car les couches cachées sont plus petites que les couches d’entrée. On appelle ce type d’architecture une architecture « bottleneck ». On peut décomposer un auto-encodeur en trois parties :
- Encodeur : L’encodeur transforme l’entrée en une représentation dans un espace de dimension plus faible appelé espace latent. L’encodeur compresse donc l’entrée dans une représentation moins coûteuse.
- Goulot d’étranglement (ou bottleneck) : Cette partie du réseau contient la représentation compressée de l’entrée qui est sera introduite dans le décodeur.
- Décodeur : cette partie doit construire l'output à l’aide de la représentation latente de l’entrée.
L’architecture dans son ensemble ressemble à ceci :
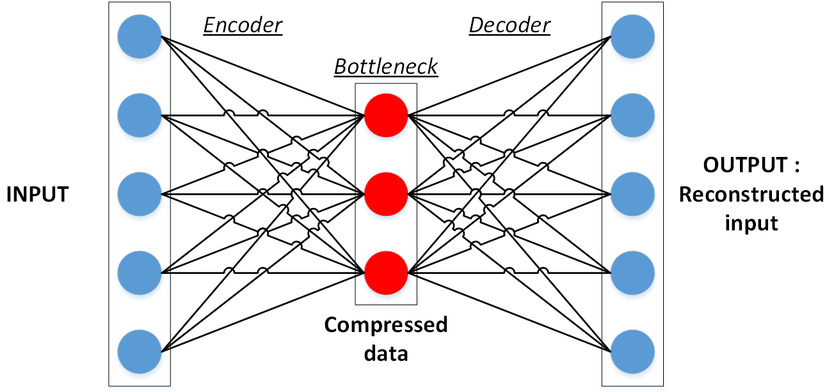
Tout d’abord, l’entrée passe par l’encodeur où elle est compressée et stockée dans le goulot d’étranglement, puis le décodeur décompresse ces données afin de retrouver l’entrée originale du réseau.
L’objectif principal de l’auto-encodeur est d’obtenir une sortie identique à l’entrée. L’architecture du décodeur est l’image miroir de l’encodeur. Ce n’est pas une exigence, mais c’est généralement le cas. La seule exigence est la dimensionnalité de l’entrée et de la sortie doivent être les mêmes.
En pratique, nous utilisons souvent des couches convolutives pour l'encodeur et des couches déconvolutives pour le décodeur.
Implémentation d'un auto-encodeur simple
Dans cet exemple, nous allons essayer d'implémenter un auto-encodeur simple que nous allons entraîner avec le jeu de données très connues MNIST.
Nous allons commencer par importer les modules nécessaires.
import keras
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from keras.datasets import mnist
from keras.models import Model
from keras.layers import Input, add
from keras.layers import Layer, Dense, Dropout, Activation, Flatten, Reshape
from keras import regularizers
from keras.regularizers import l2
from keras.layers.convolutional import Conv2D, MaxPooling2D, UpSampling2D, ZeroPadding2D
from keras.utils import np_utils
python
Nous allons ensuite, téléchargez les données MNIST. Les données sont divisées en données d'apprentissage et de test.
Chaque jeu de données est divisé en images et étiquettes. Chaque image est un tableau de pixels de 28 x 28. Les étiquettes sont des nombres de 0 à 9 correspondant aux dix chiffres manuscrits. Mais puisque les auto-encodeurs sont des réseaux à apprentissage non supervisé, nous n'aurons pas besoins des labels.
(X_train, _), (X_test, _) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1)
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1)
python
Les données doivent être pré-traitées avant de pouvoir être utilisées dans le réseau de neurones. Les valeurs de pixels doivent être normalisées de 0 à 1.
X_train = X_train.astype("float32")/255.
X_test = X_test.astype("float32")/255.
print('X_train shape:', X_train.shape)
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
python
Nous allons ensuite aplatir les matrices des images, afin de réduire leur dimension. Nous allons passer d'une matrice 2D à un vecteur 1D. Cette opération nous permettra d'alimenter les couche du réseau avec ces images.
X_train = X_train.reshape((len(X_train), np.prod(X_train.shape[1:])))
X_test = X_test.reshape((len(X_test), np.prod(X_test.shape[1:])))
python
Nous créons ensuite notre auto-encodeur, le réseau est très simple, il se compose uniquement de 3 couches. Une couche "input" permettant d'alimenter le modèle avec les données d'entrée, une couche encodeur et une couche décodeur.
À lire aussi : découvrez notre formation MLOps
input_size = 784
hidden_size = 64
output_size = 784
x = Input(shape=(input_size,))
h = Dense(hidden_size, activation='relu')(x)
r = Dense(output_size, activation='sigmoid')(h)
autoencoder = Model(inputs=x, outputs=r)
autoencoder.compile(optimizer='adam', loss='mse')```
python
Nous entraînons maintenant le réseaux sur 5 époques et a chaque fois sur un lot de 128 images.
epochs = 5
batch_size = 128
history = autoencoder.fit(X_train, X_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(X_test, X_test))
python

Voici une représentation d'une image du dataset MNIST dans l'espace latent. C'est-à-dire une représentation de l'image encodée.
#creer un modele uniquement encodeur
conv_encoder = Model(x, h)
# afficher les images encodees avec l'encodeur
encoded_imgs = conv_encoder.predict(X_test)
n = 10
plt.figure(figsize=(20, 8))
for i in range(n):
ax = plt.subplot(1, n, i+1)
plt.imshow(encoded_imgs[i].reshape(4, 16).T)
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
python

Une fois notre auto-encodeur est entraîné nous allons afficher les résultats reconstruit par le décodeur et les comparer avec les données originaux.
# Prediction du test_set
decoded_imgs = autoencoder.predict(X_test)
n = 10
plt.figure(figsize=(20, 6))
for i in range(n):
# Afficher les originaux
ax = plt.subplot(3, n, i+1)
plt.imshow(X_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# Afficher la reconstruction
ax = plt.subplot(3, n, i+n+1)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
python

Nous voyons bien ici que notre auto-encodeur a suffi pour reconstruire les digits, nos résultats sont très proches de la réalité.
Exemples d'auto-encodeurs
Il existe de nombreuses applications d'encodage de données en utilisant des auto-encodeurs et il existe également plusieurs variantes de ce réseau, des versions améliorées ou bien adaptées à des cas bien précis. On prendra quelque exemples :
-
Auto-encodeurs variationnels (VAEs) : Un VAE est un type d'auto-encodeur probabiliste. Cela signifie que, contrairement à un auto-encodeur traditionnel, un VAE ne se contente pas de mapper des données à une représentation compressée, mais tente également de modéliser la distribution des données. Il peut être utilisé pour générer de nouvelles données en décodant une distribution gaussienne aléatoire. Cela permet de générer des données plus variées que les auto-encodeurs traditionnels, car les auto-encodeurs traditionnels ne peuvent générer que des données qui se trouvent déjà dans leur jeu de données d'entraînement. Ce type est utilisé pour générer tous types de données tout comme les GANs.
-
Les auto-encodeurs de débruitage : Ce type ajoute du bruit à l’image d’entrée et apprend à le supprimer. Éviter ainsi de copier l’entrée vers la sortie sans en apprendre davantage sur les données. Ces auto-encodeurs prennent une entrée partiellement corrompue pendant la formation pour récupérer l’entrée originale non faussée. Le modèle apprend un champ vectoriel pour mapper les données d’entrée vers un collecteur de dimensions inférieures qui décrit les données naturelles pour annuler le bruit ajouté. De cette façon, l’encodeur extraira les caractéristiques les plus importantes et apprendra une représentation plus robuste des données. Ce type est utilisé pour améliorer la qualité des données bruitées ou pour restaurer des images dégradées.
-
Auto-encodeurs profonds : Un auto-encodeur profond est composé de deux réseaux symétriques de croyance profonde (deep belief network). Un des réseaux représente l’encodeur du réseau et le second réseau représente le décodeur. Les couches sont des machines Boltzmann restreintes, les éléments de base des réseaux de croyances profondes. Ils ont plus de couches qu’un simple auto-encodeur et sont donc en mesure d’apprendre des fonctionnalités plus complexes.
Il existe plusieurs autres modèles auto-encodeur tels que les auto-encodeurs contractifs et les auto-encodeurs eparses.
À lire aussi : découvrez notre formation MLOps
En bref, un auto-encodeur est une architecture de réseau neuronal capable de découvrir la structure dans les données afin de développer une représentation compressée de l’entrée. Le but est de s’assurer que la représentation compressée représente des attributs significatifs de l’entrée de données d’origine. Ce type de réseaux constitue l'élément de base de plusieurs réseaux neuronaux plus complexes, tels les GANs et les modèles Deep Learning de segmentation d'images tels que le U-Net.


