U-Net : le réseau de neurones populaire en Computer Vision
L'une de ces architectures dont en parle très souvent en Computer Vision est le U-Net. Ayant fait ces preuves en termes de précision et rapidité, le U-Net est maintenant le plus utilisé pour la segmentation d'images, surtout dans le domaine d'imagerie biomédicale.

Le domaine de la Computer Vision avance très rapidement au cours des dernières années. C'est un domaine qui cherche à automatiser les tâches que le système visuel humain peut accomplir, dont la compréhension complète de n'importe quelle scène visuelle. Pour ce faire, plusieurs architectures de réseaux de neurones ont été créés afin d'accomplir une tâche bien spécifique appelé la segmentation sémantique.
L'une de ces architectures dont en parle très souvent est le U-Net. Ayant fait ces preuves en termes de précision et rapidité, le U-Net est maintenant le plus utilisé pour la segmentation d'images, surtout dans le domaine d'imagerie biomédicale.
Dans cet article, nous examinerons le concept de la segmentation sémantique et nous allons détailler le fonctionnement, les avantages de l'architecture U-Net ainsi que des exemples de ses variantes.
La segmentation sémantique
Il y a différents niveaux de granularité dans lesquels les ordinateurs peuvent acquérir une compréhension des images. Pour chacun de ces niveaux, il y a un problème défini dans le domaine Computer Vision, à partir d’une compréhension grossière jusqu’à une compréhension plus fine.
À lire aussi : découvrez notre formation MLOps
On se trouve à chaque fois avec une tâche plus compliquée et pour laquelle on a recours à des types différents d'architecture de réseaux de neurones adaptés.
- Classification d'image : la classification d'image est une étape fondamentale de la vision par ordinateur, car c'est elle qui permet de décrire ce que contient une image. On s'attend à ce que l’ordinateur produise une étiquette discrète, qui est l’objet principal de l’image et on suppose qu’il n’y a qu’un seul objet (et non plusieurs) dans l’image.
- Classification plus localisation : dans cette étape, on s'attend également à ce que le modèle localise l’endroit exact où l’objet est présent dans l’image. Cette localisation est généralement mise en œuvre à l’aide d’une boîte de délimitation qui peut être identifiée par certains paramètres numériques tout en respectant la limite de l’image. Même dans ce cas, l’hypothèse est d’avoir un seul objet par image.
- Détection d'objet : dans cette étape, l’image n’est pas contrainte d’avoir un seul objet, mais peut contenir plusieurs objets. La tâche est de classer et de localiser tous les objets dans l’image. Ici encore, la localisation est faite en utilisant le concept de boîte de délimitation.
- Segmentation sémantique : la segmentation sémantique, aussi appelée classification basée sur les pixels ou bien prédiction dense, est une tâche importante dans laquelle on classe chaque pixel d’une image comme appartenant à une classe particulière. Contrairement aux tâches précédentes, les résultats attendus ici ne sont pas seulement des étiquettes et des paramètres de boîte de délimitation. La sortie elle-même est une image à haute résolution dans laquelle chaque pixel est classé dans une classe particulière.
- Segmentation d'instance : la segmentation d’instance est un pas en avant de la segmentation sémantique dans laquelle, avec la classification de niveau de pixel, on s'attend à ce que la machine classifie chaque instance d’une classe séparément. Par exemple, dans une image où il y a 3 chats, on a techniquement 3 instances de la classe « Chat ». Tous les 3 sont classés séparément dans une couleur différente. Mais la segmentation sémantique ne différencie pas les instances d’une classe particulière.

Comme on l'a déjà dit, la segmentation sémantique est tache précise de la vision par ordinateur qui vise à classer chaque pixel d’une image dans une classe particulière. Cette tache est appliquée dans plusieurs cas d'usage, par exemple :
- Les véhicules autonomes : La segmentation sémantique est utilisée dans ce cas pour fournir des informations sur l’espace libre sur les routes, ainsi que trouver les bords de la rue, détecter les panneaux de signalisation routière et les feux et ensuite assembler le tout pour fournir les informations nécessaire pour que le véhicule puisse décider ou et comment circuler sans intervention humaine.
- Segmentation des images médicales : La segmentation sémantique d’images médicales consiste à assigner chaque pixel de l'image à une étiquette bien précise, par exemple l’appartenance à un organe donnée, et donc détecter certaines malformations, des anomalies ou des tumeurs et par conséquent, aider les médecins à suggérer un diagnostic approprié.
- Cartographie pour l’imagerie satellitaire : La classification de la couverture terrestre peut être considérée comme une tâche de segmentation sémantique à classes multiples. La détection des routes et des bâtiments est également un sujet de recherche important pour la gestion de la circulation, l’urbanisme et la surveillance des routes.
Il existe plusieurs architectures de réseaux de neurones standard qui ont apporté des contributions significatives au domaine de la vision par ordinateur étant souvent utilisés comme base des systèmes de segmentation sémantique. On peut citer en guise d'exemple : AlexNet, ResNet, VGG-16 et GoogLeNet et bien évidemment le U-Net.
L'architecture U-Net
L’idée principale derrière les CNNs est d’apprendre le mappage de fonctionnalités d’une image. Cela fonctionne très bien dans les problèmes de classification lorsque l’image est convertie en un vecteur qui est utilisé après pour la classification. Mais dans la segmentation d’image, on doit non seulement la convertir en vecteur, mais aussi reconstruire une image à partir de ce vecteur. C’est une tâche gigantesque, car il est beaucoup plus difficile de convertir un vecteur en image que l’inverse. Toute l’idée d’U-Net tourne autour de ce problème.
U-Net, issu du réseau de neurones CNN traditionnel, a été conçu et appliqué pour la première fois en 2015 pour traiter les images biomédicales. Il est capable de localiser et de distinguer les frontières des éléments composant une certaine image en faisant la classification sur chaque pixel. Détaillons l'architecture de ce modèle afin de comprendre son fonctionnement et ce qui fait qu'il soit aussi précis et adapté à ces situations complexes.
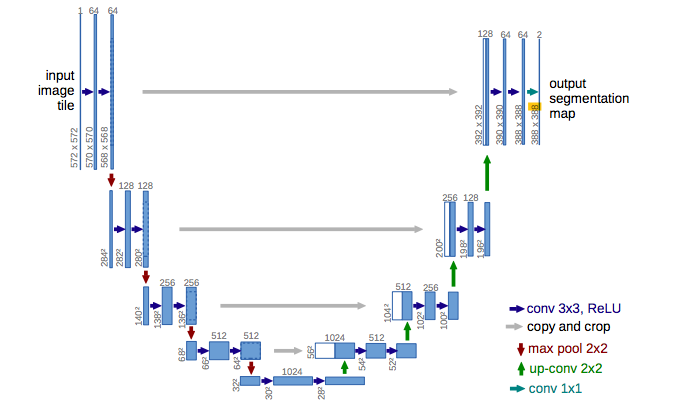
Visuellement, il a une forme en « U ». L’architecture est symétrique et se compose de trois sections : La contraction, le goulot d’étranglement et la section d’expansion.
Le premier bloc aussi appelé encodeur est utilisé pour récupérer le contexte d’une image. Ce bloc consiste en un assemblage de couches de convolution et de couches de max pooling permettant de capturer les caractéristiques d’une image et de réduire sa taille pour diminuer le nombre de paramètres du réseau. Cela consiste en l’application répétée de deux couches de convolution 3x3. Chaque couche est suivie d’une fonction d'activation ReLU et d’une normalisation par lots (batch normalization). Ensuite, une opération de max pooling 2x2 est appliquée pour réduire les dimensions spatiales.
Le pont, ou bien le goulot d’étranglement relie l’encodeur et le réseau de décodeurs et complète le flux d’informations. Il se compose de deux couches de convolutions 3x3, où chaque couche est suivie d’une fonction d’activation ReLU. Le second bloc est celui du décodeur. Il permet la localisation précise grâce à la convolution transposée et permet également de retrouver la taille initiale de l'image. Le bloc décodeur commence par un sur-échantillonnage (upsampling) de la carte des caractéristiques suivie d'une couche de convolution 2x2 transposée. Après, deux couches de convolutions 3x3 sont utilisées, où chaque convolution est suivie d’une fonction d’activation ReLU. La sortie du dernier décodeur passe par une couche de convolution 1x1 avec une fonction d'activation sigmoïde.
U-Net utilise une fonction de perte pour chaque pixel de l’image. La fonction Softmax est appliqué à chaque pixel suivi d’une fonction de perte. Ceci convertit le problème de segmentation en un problème de classification où on doit classer chaque pixel dans l’une des classes.
Les variantes du U-Net
Il existe de nombreuses applications de segmentation d’image en utilisant U-Net et il existe également plusieurs variantes de ce réseau, des versions améliorées ou bien adaptées à des cas bien précis. On prendra quelque exemples:
- Le 3D-Unet a été introduit peu après Unet pour traiter les volumes. On ne parle plus de pixels, mais plutôt de voxels. Son architecture est similaire à celle du Unet traditionnel mais les couches de convolution sont soit 3x3x3, 2x2x2 ou bien 1x1x1 (tridimensionnels). Ce modèle peut être entraîné directement sur des images en 3D, pas besoin de l’entraîner sur chaque coupe séparément.

- V-Net : ce modèle est bien similaire au 3D-Unet, Il est conçu pour de données en 3D. Les points d'innovation de ce résau sont:
- Introduire une erreur résiduelle (Dice loss fuction).
- À chaque étape, V-Net adopte la méthode de connexion par court-circuit de ResNet.
- Une couche de convolution remplace le suréchantillonnage (upsampling) et le sous-échantillonnage (downsampling).

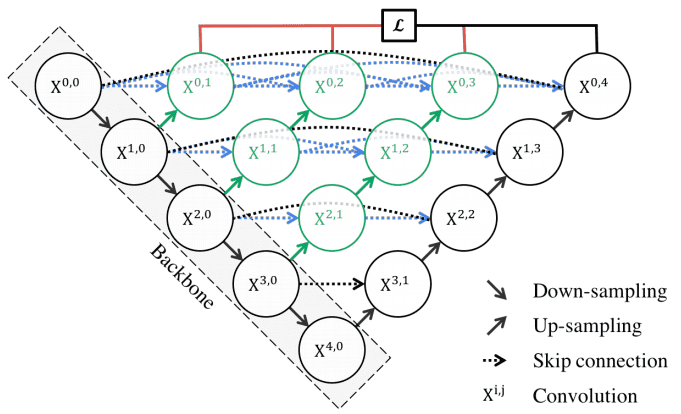
- UNet++ vise à améliorer la précision de la segmentation en incluant des couches de convolution denses directement entre l’encodeur et le décodeur. Dans l'image ci-dessous, la partie noire représente le U-net traditionnel. La partie en vert représente les couches additionnelles. Le nombre de paramètres ainsi que le temps d'entrainement du réseau est nettement plus élevé. C’est la raison principale pour laquelle il n’y a pas d’architecture similaire avec des convolutions 3D.
À lire aussi : découvrez notre formation MLOps
Il existe d'autres variantes telles le No New U-Net, Le U-Net recurrent, le U-Net dense et le U-Net residuel basé sur le ResNet.
Avantages du U-Net
Un avantage de U-Net très important est le fait qu'il est capable de faire la segmentation d’image en prédisant l’image pixel par pixel.
- Le réseau est assez fort pour faire de bonnes prédictions basées sur peu de données d'entrainement en utilisant des techniques d’augmentation de données excessives. Il offre aussi une précision supérieure aux modèles conventionnels.
- Au-delà de sa robustesse, le U-Net a une architecture simple basée sur les auto-encodeurs et des couches de convolution faciles à implémenter.
- Il existe plusieurs variantes de ce réseau adaptées à de différentes situations, certains sont très précis, d'autre sont très rapides.
Le U-Net est une architecture réseau conventionnelle pour une segmentation rapide et précise des images. Jusqu’à présent, il a surpassé toutes les méthodes précédentes surtout dans le domaine médical et la détection des anomalies et des tumeurs.


