Déploiement Canary : déployer progressivement en production
Dans les environnements de production modernes, le déploiement de nouvelles versions d'une application reste un moment critique. Comment s'assurer qu'une mise à jour ne provoquera pas d'incident majeur affectant l'ensemble des utilisateurs ? Comment valider le comportement d'une nouvelle fonctionnalité en conditions réelles avant de l'exposer à grande échelle ? Comment limiter l'impact d'un bug qui aurait échappé aux tests ? Ces questions, familières à toute équipe responsable d'applications à fort trafic, trouvent une réponse élégante dans une stratégie de déploiement inspirée d'une pratique minière ancestrale : le déploiement Canary.

Dans les environnements de production modernes, le déploiement de nouvelles versions d'une application reste un moment critique. Comment s'assurer qu'une mise à jour ne provoquera pas d'incident majeur affectant l'ensemble des utilisateurs ? Comment valider le comportement d'une nouvelle fonctionnalité en conditions réelles avant de l'exposer à grande échelle ? Comment limiter l'impact d'un bug qui aurait échappé aux tests ? Ces questions, familières à toute équipe responsable d'applications à fort trafic, trouvent une réponse élégante dans une stratégie de déploiement inspirée d'une pratique minière ancestrale : le déploiement Canary.
Véritable filet de sécurité pour les mises en production, le déploiement Canary consiste à exposer une nouvelle version d'une application à un sous-ensemble restreint d'utilisateurs avant de l'étendre progressivement à l'ensemble du trafic. Cette approche, adoptée par des géants comme Google, Netflix, Facebook ou encore LinkedIn, permet de détecter les problèmes en production avec un impact minimal, transformant chaque déploiement en une expérience contrôlée plutôt qu'en un pari risqué. Contrairement au déploiement Blue/Green qui bascule l'intégralité du trafic d'un coup, le Canary offre une granularité fine et une capacité de rollback quasi instantanée, en faisant une stratégie de choix pour les organisations pratiquant le déploiement continu.
Le principe du Canary : une approche progressive
Le terme "Canary" fait référence aux canaris que les mineurs emportaient autrefois dans les mines de charbon. Ces oiseaux, particulièrement sensibles aux gaz toxiques, servaient de système d'alerte précoce : si le canari montrait des signes de malaise, les mineurs savaient qu'il fallait évacuer avant que le danger ne les atteigne. Le déploiement Canary applique exactement ce principe au monde du logiciel.
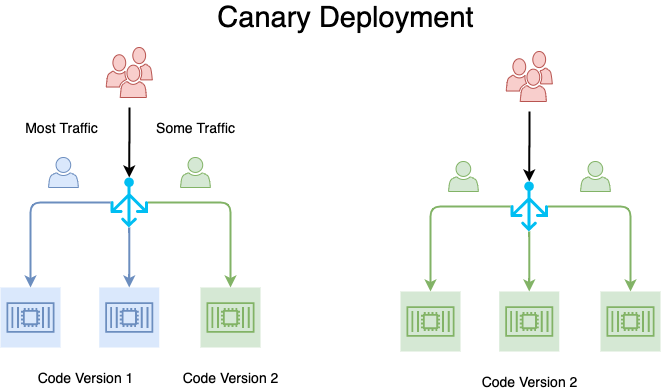
Concrètement, lors d'un déploiement Canary, la nouvelle version de l'application est déployée sur un nombre limité d'instances (souvent une seule au départ), qui ne reçoivent qu'une fraction du trafic total. Cette fraction peut être aussi faible que 1% ou 5% des requêtes. Pendant cette phase, l'équipe surveille attentivement les métriques clés : taux d'erreur, latence, utilisation des ressources, mais aussi indicateurs métier comme le taux de conversion ou le nombre de transactions réussies.
Si les métriques restent satisfaisantes, le pourcentage de trafic dirigé vers la nouvelle version est progressivement augmenté : 5%, puis 10%, 25%, 50%, jusqu'à atteindre 100%. À chaque palier, une période d'observation permet de valider la stabilité avant de poursuivre. En revanche, si des anomalies sont détectées à n'importe quelle étape, le trafic peut être instantanément redirigé vers l'ancienne version, limitant l'impact à la seule fraction d'utilisateurs exposée.
Cette progression graduelle offre plusieurs avantages fondamentaux :
- Détection précoce des problèmes : les bugs ou régressions de performance sont identifiés alors qu'ils n'affectent qu'une minorité d'utilisateurs.
- Validation en conditions réelles : contrairement aux environnements de staging, le Canary expose la nouvelle version au trafic réel avec toute sa diversité (devices, réseaux, comportements utilisateurs).
- Rollback instantané : en cas de problème, revenir à l'ancienne version se fait en quelques secondes en redirigeant simplement le trafic.
- Confiance accrue : les équipes déploient plus sereinement et plus fréquemment, sachant que le risque est maîtrisé.
Mise en œuvre technique
L'implémentation d'un déploiement Canary repose sur la capacité à contrôler finement la distribution du trafic entre les différentes versions de l'application. Plusieurs approches techniques permettent d'atteindre cet objectif, chacune avec ses spécificités.
Routage au niveau du load balancer ou reverse proxy
La méthode la plus directe consiste à configurer le load balancer ou le reverse proxy pour distribuer le trafic selon des pourcentages définis. Avec Nginx, par exemple, le module split_clients permet de répartir les requêtes :
split_clients "${remote_addr}" $variant {
5% canary;
* stable;
}
upstream stable {
server app-v1:8080;
}
upstream canary {
server app-v2:8080;
}
server {
location / {
proxy_pass http://$variant;
}
}
nginx
Traefik, particulièrement adapté aux environnements conteneurisés, offre une fonctionnalité native de weighted round-robin permettant de définir des poids différents pour chaque backend.
Canary dans Kubernetes
Dans un environnement Kubernetes, plusieurs stratégies permettent d'implémenter le déploiement Canary. L'approche native consiste à créer deux Deployments distincts (stable et canary) avec des labels identiques, puis à ajuster le nombre de réplicas pour contrôler la proportion de trafic. Si le Deployment stable a 9 réplicas et le canary 1, environ 10% du trafic atteindra la nouvelle version.
Pour un contrôle plus fin, des outils spécialisés comme Flagger ou Argo Rollouts automatisent le processus de Canary en s'intégrant avec les service meshes (Istio, Linkerd) ou les ingress controllers. Ces outils permettent de définir des stratégies de progression sophistiquées :
apiVersion: flagger.app/v1beta1
kind: Canary
metadata:
name: mon-application
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: mon-application
progressDeadlineSeconds: 60
service:
port: 80
analysis:
interval: 30s
threshold: 5
maxWeight: 50
stepWeight: 10
metrics:
- name: request-success-rate
thresholdRange:
min: 99
- name: request-duration
thresholdRange:
max: 500
yaml
Cette configuration automatise la progression du Canary par paliers de 10% toutes les 30 secondes, à condition que le taux de succès reste supérieur à 99% et la latence inférieure à 500ms. En cas de violation de ces seuils, le rollback est automatique.
Critères de routage avancés
Au-delà du simple pourcentage de trafic, le déploiement Canary peut s'appuyer sur des critères plus sophistiqués pour cibler les utilisateurs exposés à la nouvelle version :
| Critère | Description | Cas d'usage |
|---|---|---|
| Pourcentage aléatoire | X% du trafic vers le canary | Approche standard |
| Headers HTTP | Routing basé sur un header spécifique | Tests internes, beta testers |
| Cookies | Utilisateurs identifiés par cookie | Cohérence de session |
| Géolocalisation | Région ou pays de l'utilisateur | Déploiement régional progressif |
| Caractéristiques utilisateur | Segment, plan d'abonnement | Feature flags avancés |
Cette flexibilité permet par exemple de déployer d'abord vers les utilisateurs internes, puis vers un groupe de beta testers volontaires, avant d'ouvrir progressivement au trafic général.
Canary vs Blue/Green : choisir la bonne stratégie
Le déploiement Canary est souvent comparé au déploiement Blue/Green, une autre stratégie populaire de mise en production à faible risque. Bien que partageant l'objectif de minimiser l'impact des déploiements, ces deux approches diffèrent fondamentalement dans leur philosophie.
Le déploiement Blue/Green maintient deux environnements de production identiques : le "Blue" (version actuelle) et le "Green" (nouvelle version). Une fois le Green prêt et validé, l'intégralité du trafic bascule d'un coup. Le rollback, si nécessaire, consiste simplement à rebasculer vers le Blue. Cette approche est simple à comprendre et à implémenter, mais expose 100% des utilisateurs dès la bascule.
Le déploiement Canary, en revanche, ne bascule jamais l'intégralité du trafic d'un coup. La progression est graduelle, permettant de détecter des problèmes qui n'apparaîtraient qu'en conditions de charge réelle ou avec certains patterns de trafic spécifiques. Cette granularité a un coût : la mise en œuvre est plus complexe et nécessite une infrastructure capable de router le trafic de manière différenciée.
| Aspect | Blue/Green | Canary |
|---|---|---|
| Exposition au risque | 100% des users immédiatement | Progression graduelle (1%, 5%, 10%...) |
| Complexité de mise en œuvre | Modérée | Plus élevée |
| Infrastructure requise | 2x la capacité pendant le déploiement | Capacité incrémentale |
| Détection des problèmes | Après bascule complète | Pendant la progression |
| Rollback | Instantané (rebascule) | Instantané (redirection trafic) |
| Validation en conditions réelles | Limitée (environnement Green isolé) | Native (trafic réel progressif) |
Le choix entre ces stratégies dépend du contexte. Le Blue/Green convient bien aux applications avec des déploiements moins fréquents ou lorsque la validation pré-production est suffisamment robuste. Le Canary s'impose lorsque :
- L'application reçoit un trafic important où même un incident bref affecterait de nombreux utilisateurs.
- Les tests automatisés ne peuvent pas simuler toute la diversité du trafic réel.
- L'équipe pratique le déploiement continu avec des releases fréquentes.
- Les métriques de production sont matures et permettent de détecter rapidement les anomalies.
Dans la pratique, de nombreuses organisations combinent les deux approches : Blue/Green pour les changements d'infrastructure majeurs, Canary pour les évolutions applicatives régulières.
Défis et bonnes pratiques
Malgré ses avantages, le déploiement Canary présente des défis qu'il convient d'anticiper pour en tirer pleinement parti.
L'observabilité comme prérequis
Un déploiement Canary n'a de valeur que si l'équipe peut distinguer le comportement des deux versions et détecter rapidement les anomalies. Cela implique une instrumentation robuste avec des métriques segmentées par version, un système d'alerting réactif, et idéalement du tracing distribué pour investiguer les problèmes. Sans cette observabilité, le Canary devient un exercice aveugle où les problèmes ne sont découverts que par les plaintes utilisateurs.
Les métriques essentielles à surveiller incluent :
- Taux d'erreur (HTTP 5xx, exceptions) comparé entre versions
- Latence (p50, p95, p99) pour détecter les régressions de performance
- Saturation des ressources (CPU, mémoire, connexions)
- Métriques métier (conversions, transactions, engagement) pour les régressions fonctionnelles
Gestion de la compatibilité
Lorsque deux versions coexistent en production, la compatibilité des données devient critique. Si la nouvelle version modifie le schéma de base de données ou le format des messages dans une file, l'ancienne version doit pouvoir continuer à fonctionner. Cette contrainte impose souvent des migrations en plusieurs étapes et une discipline de rétrocompatibilité dans les APIs et les structures de données.
Durée et critères de progression
Définir la durée de chaque palier et les critères de progression demande un équilibre entre prudence et vélocité. Des paliers trop courts risquent de ne pas capturer les problèmes intermittents ; des paliers trop longs ralentissent inutilement les déploiements. L'automatisation de la progression basée sur des métriques objectives (comme avec Flagger) permet de trouver cet équilibre en s'adaptant dynamiquement aux signaux observés.
À découvrir : notre formation DevOps Engineer
Conclusion
Le déploiement Canary s'est imposé comme une stratégie incontournable pour les organisations pratiquant le déploiement continu sur des applications à fort enjeu. En exposant progressivement les nouvelles versions à une fraction croissante du trafic, il transforme chaque mise en production en une expérience contrôlée où les risques sont identifiés et contenus avant d'affecter l'ensemble des utilisateurs.
Au-delà de la réduction des risques, le Canary instaure une culture de confiance dans le déploiement. Les équipes n'hésitent plus à déployer fréquemment, sachant que le filet de sécurité du Canary leur permet de détecter et corriger rapidement les problèmes. Cette vélocité accrue, combinée à la validation en conditions réelles, accélère le cycle de feedback et améliore in fine la qualité du produit. Pour les organisations qui investissent dans l'observabilité et l'automatisation, le déploiement Canary représente un levier majeur de maturité DevOps, réconciliant l'agilité des releases fréquentes avec la stabilité qu'exigent les environnements de production critiques.


