Réseaux convolutifs (CNN) : comment ça marche ?
Les réseaux neuronaux sont un sous-ensemble de l’apprentissage automatique, et ils sont au cœur des algorithmes d’apprentissage profond. Inventés par Yann LeCun durant les années 90, les CNNs sont inspirés des réseaux neuronaux biologiques, et ils sont devenus extrêmement populaires en raison de leurs performances dans les domaines de la vision et plusieurs autres domaines.

L’intelligence artificielle a été témoin d’une croissance monumentale en comblant le fossé entre les capacités des humains et des machines à voir et comprendre des scènes visuelles. Les progrès de la vision par ordinateur avec l’apprentissage profond ont été construits et perfectionnés avec le temps, principalement au moyen d’un algorithme particulier, un réseau de neurones convolutifs.
Les réseaux neuronaux sont un sous-ensemble de l’apprentissage automatique, et ils sont au cœur des algorithmes d’apprentissage profond. Inventés par Yann LeCun durant les années 90, les CNNs sont inspirés des réseaux neuronaux biologiques, et ils sont devenus extrêmement populaires en raison de leurs performances dans les domaines de la vision et plusieurs autres domaines.
Dans cet article, nous allons introduire les réseaux convolutifs et leur architecture, les cas d'usage d'un CNN et des exemples de modèles se basant sur ce type de réseaux. Nous allons également appliquer un CNN simple pour une tache de classification d'images.
C'est quoi un CNN ?
Le réseau de neurones convolutifs, ou CNN pour faire court, est un type spécialisé de modèle de réseau de neurones conçu pour travailler avec des données d’images bidimensionnelles, bien qu’ils puissent être utilisés avec des données unidimensionnelles et tridimensionnelles. Ces réseaux sont capables d'apprendre à extraire des caractéristiques locales, c'est-à-dire des structures qui se répètent à travers l'image.
Au centre du réseau de neurones convolutifs se trouve la couche convolutionnelle qui donne son nom au réseau. Cette couche effectue une opération appelée « convolution ».
À lire aussi : découvrez notre formation MLOps
Une convolution est la simple application d’un filtre à une entrée qui entraîne une activation. L’application répétée d’un même filtre à une entrée produit une carte d’activations appelée carte de fonctionnalités (Feauture map), indiquant les emplacements d’une fonctionnalité détectée dans une entrée, telle qu’une image.

Les CNNs ont été initialement développés pour la reconnaissance d'images. Le premier CNN a été créé en 1989 par Yann LeCun. Il a été formé pour reconnaître des caractères manuscrits et des digits. Les CNNs ont été créés à partir d'un réseau de neurones formé de plusieurs couches. Chaque couche est formée de neurones qui sont connectés aux neurones de la couche suivante. Ils sont entraînés en fournissant des images et en demandant au réseau de les classer. Le réseau apprend les caractéristiques des images au fur et à mesure qu'il les voit.
Les CNNs sont entraînés sur de grandes bases de données d'images et ont montré une meilleure performance que les algorithmes de vision par ordinateur existants. Ils ont ensuite été adoptées par de nombreux domaines, notamment la reconnaissance de la parole, la vision 3D, la vision par ordinateur médicale et l'apprentissage automatique.
Architecture d'un CNN
La première couche de convolution détecte les features de l'image, comme les contours, les formes et les textures. Les couches suivantes détectent des features plus complexes à partir des features détectés par la couche précédente. La dernière couche de convolution est généralement suivie d'une couche fully connected qui combine les features détectés par les couches de convolution et les utilise pour classifier l'image.
Les couches convolutionnelles peuvent être suivies de couches convolutionnelles supplémentaires ou de couches de regroupement (pooling). Avec chaque couche, le CNN augmente dans sa complexité, en identifiant de plus grandes portions de l’image. Les couches précédentes se concentrent sur des caractéristiques simples, telles que les couleurs et les bords. Au fur et à mesure que les données d’image progressent dans les couches du CNN, il commence à reconnaître des éléments ou des formes plus précises de l’objet jusqu’à ce qu’il identifie finalement l’objet visé.
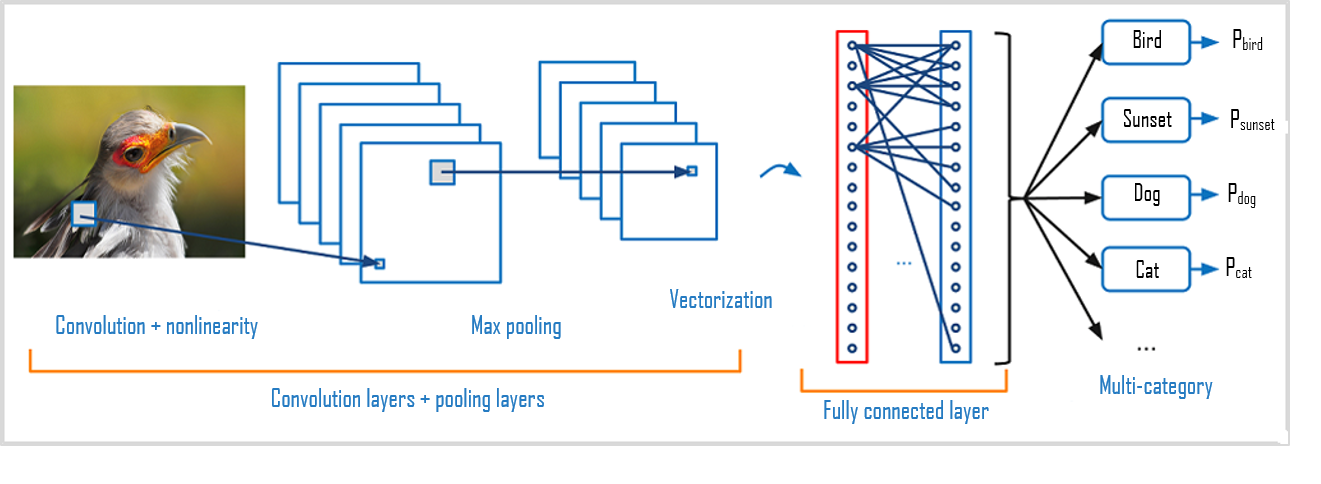
Couche de convolution
La couche de convolution est la composante clé des réseaux de neurones, convolutifs, elle constitue toujours au moins leur première couche. Les couches de convolution sont formées de ce qu'on appelle des filtres. Les filtres sont des tableaux de valeurs appelées feature maps. Chaque couche de convolution prend en entrée une image et produit une feature map. Chaque feature map est obtenue en appliquant le filtre à l'image. Par exemple, si l'image est de taille 5x5 et que le filtre est de taille 3x3, la feature map sera de taille 3x3. La couche de convolution reçoit donc en entrée plusieurs images et calcule la convolution de chacune d'entre elles avec chaque filtre. Les filtres correspondent exactement aux features que l'on souhaite retrouver dans les images.
Couche de pooling
Ce type de couche est souvent placé entre deux couches de convolution : elle reçoit en entrée plusieurs feature maps, et applique à chacune d'entre elles l'opération de pooling. Une couche de pooling, agit comme une couche de réduction. Elle divise l'image en blocs et ne garde que le maximum de chaque bloc. Cela permet de réduire la dimension de l'image tout en conservant les caractéristiques les plus importantes. On obtient en sortie le même nombre de feature maps qu'en entrée, mais celles-ci sont bien plus petites.
Couche fully-connected
Les CNNs sont généralement formés de plusieurs couches de convolution et de pooling, suivies par une couche fully-connected qui combine les features extraites par les couches précédentes pour classifier l'image, elle renvoie un vecteur de taille N, où N est le nombre de classes dans notre problème de classification d'images. Chaque élément du vecteur indique la probabilité pour l'image en entrée d'appartenir à une classe.
Par exemple, s'il s'agit bien d'un problème de classification de pommes et d'orange, le vecteur final sera de taille 2 : chaque élément donne la probabilité d'appartenir soit à la classe pomme, soit à la classe orange. Ainsi, le vecteur [ 0.8 , 0.2 ] signifie que l'image à 80% de chances de représenter une pomme.
À lire aussi : découvrez notre formation MLOps
La couche fully connected constitue toujours la dernière couche d'un réseau de neurones, convolutif ou non, elle n'est donc pas caractéristique d'un CNN. Ce type de couche reçoit un vecteur en entrée et produit un nouveau vecteur en sortie. Pour cela, elle applique une combinaison linéaire puis éventuellement une fonction d'activation aux valeurs reçues en entrée.
Mise en application du CNN
Dans ce qui suit, nous allons créer un CNN simple pour classifier des images de nous allons faire un exemple de classification d'images de chiffres manuscrits. Pour ce faire, nous utiliserons le jeu de données très connu MNIST.
Nous allons commencer par télécharger les données MNIST et diviser les données en données d'apprentissage et de test.
Chaque jeu de données est divisé en images et étiquettes. Chaque image est un tableau de pixels de 28 x 28. Les étiquettes sont des nombres de 0 à 9 correspondant aux dix chiffres manuscrits.
Les données doivent être pré-traitées avant de pouvoir être utilisées dans le réseau de neurones. Les valeurs de pixels doivent être normalisées de 0 à 1.
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
python
Les librairies TensorFlow et le module Keras permettent de construire des CNNs très facilement. Nous les utiliserons pour construire un réseau convolutif se composant de 5 couches, étape par étape.
from keras import models
from keras import layers
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Flatten
python
Nous initialisons un modèle vide, nous commençons ensuite à le construire couche par couche. Ici, nous avons une couche de convolution avec plusieurs paramètres :
- 32 filtres
- un motif de taille (3, 3), aussi appelé kernel 3×3 pixels
- un pas de (1,1), aussi appelé strides
- une fonction d’activation.
- taille des données d'entrée (28, 28, 1) une image en 3 dimensions (hauteur, largeur, couleur), un 3D-tensor.
Cette couche passe sur chaque pixel de l’image (strides = (1,1)) pour en extraire des motifs de taille 3×3 pixels (kernel = (3,3)). La couche exécute cette action 32 fois (filtres = 32) et produit 32 feature-maps chacune représente des caractéristiques différentes de l’image.
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu',kernel_initializer='he_uniform',input_shape=(28, 28, 1)))
python
La couche suivante est une couche de MaxPooling. Il existe deux principaux types de couches de regroupement :
- Max Pooling : lorsque le filtre se déplace sur l’entrée, il sélectionne le pixel avec la valeur maximale à envoyer à la matrice de sortie. Cette approche tend à être utilisée plus souvent que la mise en commun moyenne.
- Average Pooling : Lorsque le filtre se déplace sur l’entrée, il calcule la valeur moyenne dans le champ réceptif à envoyer à la matrice de sortie.
Nous allons utiliser une couche MaxPooling a un kernel de taille (2, 2) dans notre cas.
model.add(MaxPooling2D((2, 2)))
python
Puisque nous avons commencé avec une image en 3 dimensions (hauteur, largeur, couleur), un 3D-tensor, et nous finissons avec un label à une dimension, un 1D-tensor. Une couche de convolution retourne un 3D-tensor, un tenseur à 3 dimensions, ce ne peut donc pas être la couche finale. Nous utilisons alors une couche appelée Flatten qui permet d’aplatir le tenseur, de réduire sa dimension. Elle prend en entrée un 3D-tensor et retourne un 1D-tensor.
model.add(Flatten())
python
C’est une opération permet d’établir une connexion entre les couches de convolution/pooling et les couches de base du Deep Learning.
À lire aussi : découvrez notre formation MLOps
Les données sont ainsi diffusées à travers les couches en réduisant leur dimension, atteint finalement une couche de prédiction, comme la couche dense ou fully connected, qui permet d’obtenir le label détecté par le modèle.
Dans notre cas, nous ajoutons deux couches entièrement connectées, la couche finale produit en sortie un vecteur de taille 10. 10 fait référence au nombre de classes de digits (de 0 à 9).
model.add(Dense(100, activation='relu', kernel_initializer='he_uniform'))
model.add(Dense(10, activation='softmax'))
python
Le modèle est finalement compilé avec l'optimiseur et la fonction de perte. Il est ensuite entraîné en utilisant les données d'apprentissage. L'entraînement est effectué sur 5 époques
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],)
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test, verbose=2)
python

Notre modèle a atteint une précision > 99 % après 5 époques d'entrainement.
Exemples de CNNs
Diverses architectures de CNNs disponibles ont joué un rôle clé dans la création d’algorithmes qui alimentent l’IA dans son ensemble. Certains d’entre eux ont été énumérés ci-dessous :
- LeNet : est une des premières architectures de CNN développée. Il est composé de sept couches de neurones : trois couches de convolution, une couche de pooling, une couche de normalisation, une couche de sortie fully-connected et une couche de classification. LeNet a été entraîné sur de nombreuses tâches de vision par ordinateur, y compris la classification d'images, la détection d'objets et la reconnaissance de chiffres manuscrits. Il a également été utilisé pour d'autres tâches d'apprentissage automatique, telles que la classification de texte et la classification de signaux audio.
- AlexNet : est composé de 5 couches de convolution et 3 couches fully-connected. Il utilise des techniques d'apprentissage profond telles que l'utilisation de couches de pooling, de dropout et de normalisation récurrente.
- VGGNet : est une famille de modèles de réseaux de neurones convolutifs de grande profondeur (19 couches) construits par Visual Geometry Group (VGG) à l'Université d'Oxford. Ils ont été introduits dans le papier "Very Deep Convolutional Networks for Large-Scale Image Recognition" en 2014. La VGGNet est composée de 16 (VGG-16) ou 19 (VGG-19) couches de convolution et de pooling, suivies de 3 ou 4 couches de réseaux fully-connected à la fin. Les couches de pooling sont remplacées par des strided convolutions dans certaines versions.
- ResNet : ResNet est un réseau de neurones profond (152 couches) composé de plusieurs blocs de modules de raccourcissement de chemin, introduit dans le papier "Deep Residual Learning for Image Recognition" en 2015. Un module de raccourcissement de chemin (shortcut) est composé de plusieurs couches de convolution et de pooling, suivies d'une addition nulle de l'entrée de module à sa sortie. La structure des raccourcissements de chemin permet de résoudre le problème de l'apprentissage profond (vanishing / exploding gradients).
Il existe plusieurs autres modèles tels que GoogleNet et ZFNet.
Les réseaux de neurones convolutifs sont capables d’apprendre des modèles complexes dans les données et d’obtenir des performances de pointe sur une variété de tâches. Ils sont efficaces également pour capturer les caractéristiques spatiales et temporelles des vidéos. Mais ils sont des systèmes de calcul intensifs qui nécessitent des GPUs pour un entrainement efficace.


