Context Engineering : le futur du Prompt Engineering
Le Context Engineering est une approche qui déplace l'attention de la formulation des instructions vers l'orchestration de toutes les informations pertinentes pour une tâche donnée. System prompts, historique de conversation, données utilisateur, documents de référence, résultats d'outils externes. L'enjeu est désormais de composer ce contexte de manière optimale pour que le LLM dispose de tout ce dont il a besoin pour répondre avec justesse.

L'ère du prompt parfait touche à sa fin. Pendant des mois, les équipes ont peaufiné leurs instructions, ajusté chaque virgule, testé des dizaines de formulations pour extraire le meilleur des modèles de langage. Cette discipline du Prompt Engineering a produit des résultats impressionnants, mais elle repose sur une prémisse qui devient obsolète : l'idée que les LLM sont des créatures capricieuses qu'il faut manipuler avec précision.
Les modèles de 2025 ont changé la donne. GPT-4o, Claude 3.5 Sonnet, Gemini Pro — ces LLM sont devenus remarquablement robustes face aux variations de formulation. Ils comprennent l'intention derrière une requête même maladroite, tolèrent les ambiguïtés, et produisent des réponses cohérentes sans nécessiter des instructions chirurgicales. Le goulot d'étranglement n'est plus la qualité du prompt, mais la richesse du contexte fourni au modèle.
C'est ce constat qui donne naissance au Context Engineering : une approche qui déplace l'attention de la formulation des instructions vers l'orchestration de toutes les informations pertinentes pour une tâche donnée. System prompts, historique de conversation, données utilisateur, documents de référence, résultats d'outils externes. L'enjeu est désormais de composer ce contexte de manière optimale pour que le LLM dispose de tout ce dont il a besoin pour répondre avec justesse.
Dans cet article, nous allons explorer ce changement de paradigme, comprendre ce que recouvre concrètement le Context Engineering, et découvrir les techniques et architectures qui permettent de l'implémenter dans vos applications d'IA générative.
Du Prompt Engineering au Context Engineering
Le Prompt Engineering a émergé comme discipline lorsque les premiers LLM performants ont révélé une sensibilité surprenante à la formulation des requêtes. Un changement de mot pouvait transformer une réponse excellente en résultat médiocre. Les praticiens ont développé un arsenal de techniques : few-shot prompting, chain-of-thought, rôles explicites, délimiteurs structurants. Ces approches restent utiles, mais leur importance relative a diminué.
La différence fondamentale entre les deux approches tient à leur objet d'optimisation :
- Le Prompt Engineering optimise comment vous formulez votre demande
- Le Context Engineering optimise quelles informations vous fournissez au modèle
| Aspect | Prompt Engineering | Context Engineering |
|---|---|---|
| Focus principal | Formulation des instructions | Orchestration des informations |
| Hypothèse clé | Le modèle est sensible à la formulation | Le modèle est limité par son contexte |
| Effort principal | Rédaction et itération du prompt | Architecture et flux de données |
| Scalabilité | Limitée (artisanal) | Élevée (systématique) |
| Dépendance au modèle | Forte (prompts spécifiques) | Faible (contexte transférable) |
Cette évolution reflète la maturation des LLM. Les modèles actuels intègrent nativement les bonnes pratiques de prompting dans leur entraînement. Ils sont exposés à des millions d'exemples de requêtes bien et mal formulées, et apprennent à extraire l'intention sous-jacente. Demander à un modèle moderne de "répondre étape par étape" reste utile, mais le gain marginal est bien moindre qu'avec les modèles d'il y a deux ans.
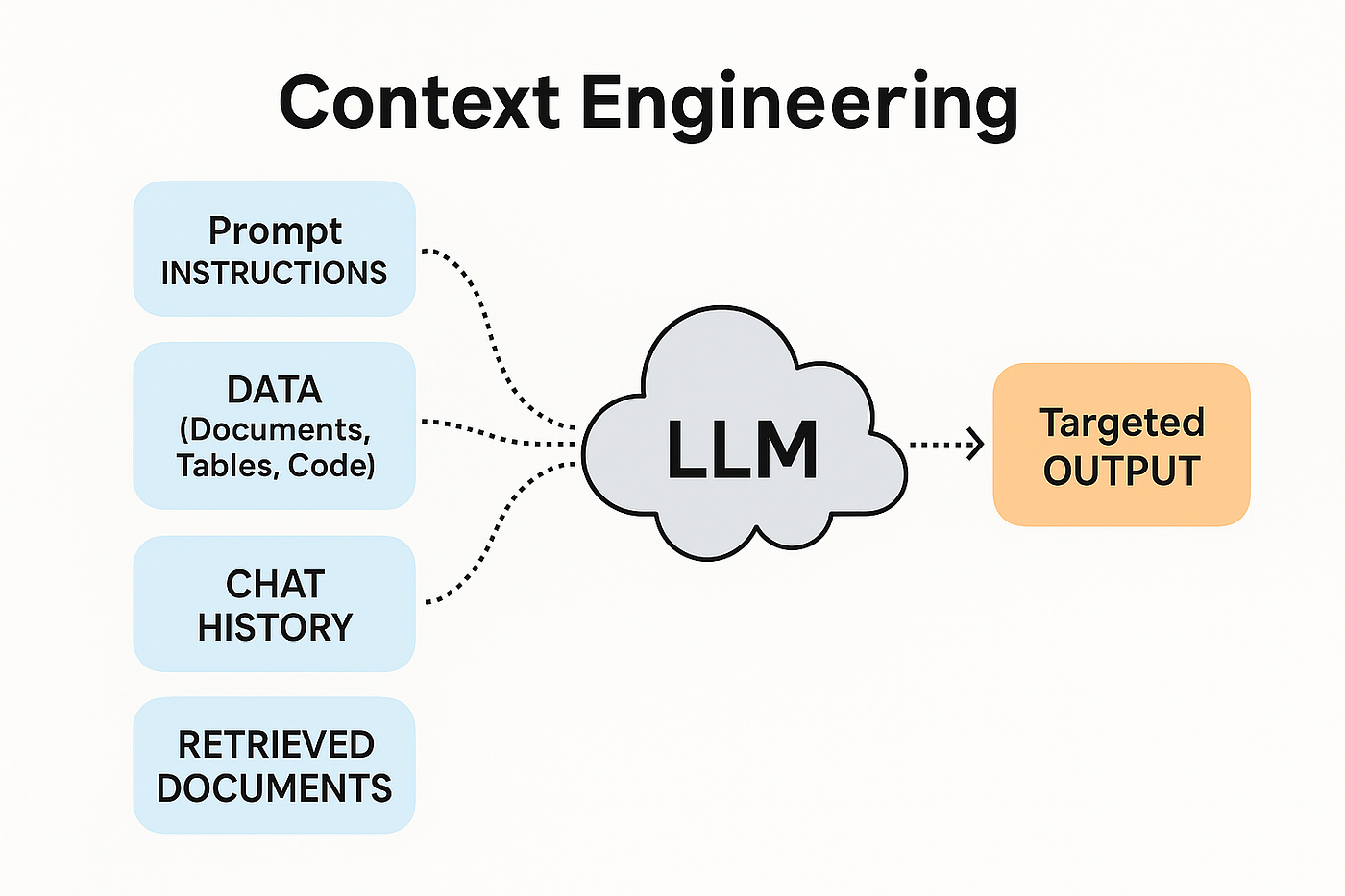
Le Context Engineering reconnaît une vérité simple : un LLM ne peut pas deviner ce qu'il ne sait pas. Aussi performant soit-il, si vous lui demandez d'analyser la situation financière d'un client sans lui fournir les données pertinentes, il ne pourra que halluciner ou répondre de manière générique. L'enjeu n'est plus de formuler la question parfaite, mais de s'assurer que toute l'information nécessaire est présente dans la fenêtre de contexte.
Les composants du contexte
Le contexte fourni à un LLM se compose de plusieurs couches qui s'empilent pour former l'entrée complète du modèle. Maîtriser le Context Engineering implique de comprendre chacune de ces couches et leur contribution à la qualité des réponses.
Le system prompt définit le comportement global du modèle : son rôle, son ton, ses contraintes, ses capacités. Contrairement à ce qu'on pourrait penser, l'enjeu ici n'est pas tant la formulation que l'exhaustivité. Un system prompt efficace en Context Engineering inclut :
- Le rôle et l'expertise attendus
- Les règles métier à respecter
- Les formats de sortie souhaités
- Les comportements à éviter
- Les informations sur l'utilisateur ou le contexte d'usage
L'historique de conversation constitue une source de contexte souvent sous-exploitée. Au-delà du simple empilage des messages précédents, des techniques comme le résumé dynamique ou la sélection des échanges pertinents permettent de maximiser l'information utile tout en respectant les limites de la fenêtre de contexte.
Les données dynamiques — informations récupérées au moment de la requête — représentent le cœur du Context Engineering avancé. Cela inclut :
- Les documents pertinents récupérés via un système RAG
- Les données utilisateur (profil, préférences, historique)
- Les résultats d'appels à des outils ou APIs externes
- L'état actuel d'un système ou d'un processus
- Les métadonnées temporelles (date, heure, fuseau horaire)
# Exemple de construction de contexte dynamique
def build_context(user_query, user_id):
# Récupération des informations utilisateur
user_profile = get_user_profile(user_id)
user_history = get_recent_interactions(user_id, limit=5)
# Récupération des documents pertinents (RAG)
relevant_docs = retriever.retrieve(user_query, top_k=3)
# Données temps réel si nécessaire
current_time = datetime.now().isoformat()
# Assemblage du contexte
context = f"""
## Profil utilisateur
{format_profile(user_profile)}
## Historique récent
{format_history(user_history)}
## Documents de référence
{format_documents(relevant_docs)}
## Métadonnées
Date et heure actuelles : {current_time}
"""
return context
python
L'output d'outils et d'agents ajoute une dimension supplémentaire. Dans une architecture agentique, le modèle peut appeler des outils (recherche web, exécution de code, appels API) dont les résultats enrichissent le contexte pour les étapes suivantes. Cette boucle dynamique permet au contexte d'évoluer au fil de la tâche.
À découvrir : notre formation LLM Engineering
Architectures et patterns du Context Engineering
Implémenter un Context Engineering efficace nécessite des architectures pensées pour orchestrer l'information de manière fluide. Plusieurs patterns ont émergé comme standards de l'industrie.
Le templating dynamique
Le templating constitue la brique de base du Context Engineering. Plutôt que des prompts statiques, on définit des templates avec des zones variables qui sont remplies au moment de la requête. Des outils comme Jinja2 ou les primitives de LangChain permettent de construire ces templates de manière maintenable :
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", """Tu es un assistant spécialisé en {domain}.
Règles à respecter :
{business_rules}
Informations sur l'utilisateur :
- Niveau d'expertise : {user_expertise}
- Langue préférée : {user_language}
"""),
("human", "{user_query}")
])
# Le contexte est injecté dynamiquement
prompt = template.format_messages(
domain="finance personnelle",
business_rules=load_rules(),
user_expertise="intermédiaire",
user_language="français",
user_query=query
)
python
L'architecture RAG comme pilier
Le RAG (Retrieval Augmented Generation) incarne parfaitement la philosophie du Context Engineering : plutôt que d'espérer que le modèle "sache" quelque chose, on lui fournit explicitement l'information pertinente. Les frameworks comme LlamaIndex et LangChain facilitent la construction de ces pipelines.
L'évolution du RAG vers des approches plus sophistiquées — recherche hybride, reranking, chunking sémantique — reflète cette attention croissante portée à la qualité du contexte plutôt qu'à la formulation de la requête.
Les systèmes agentiques
Les agents IA représentent l'aboutissement du Context Engineering. Un agent peut enrichir son propre contexte en appelant des outils, en effectuant des recherches, en exécutant du code. Chaque action produit de l'information qui alimente les étapes suivantes :
- L'agent reçoit une requête avec un contexte initial
- Il décide d'appeler un outil (recherche web, base de données, API)
- Le résultat de l'outil enrichit le contexte
- Avec ce contexte augmenté, l'agent peut répondre ou itérer
Cette boucle d'enrichissement contextuel permet de traiter des tâches complexes qui nécessitent des informations non disponibles initialement. Le protocole MCP (Model Context Protocol) émerge comme standard pour exposer des sources de contexte de manière interopérable entre différents systèmes.
La gestion de la fenêtre de contexte
Avec des fenêtres de contexte atteignant 128K tokens ou plus, la contrainte de taille s'est assouplie mais n'a pas disparu. Les stratégies de gestion incluent :
- Le résumé progressif : condenser l'historique ancien pour préserver l'espace
- La sélection intelligente : ne garder que les éléments pertinents pour la requête courante
- Le chunking adaptatif : ajuster la granularité des documents selon l'espace disponible
- La priorisation : placer les informations critiques en début et fin de contexte (là où l'attention du modèle est maximale)
Les avantages du Context Engineering
L'adoption du Context Engineering apporte des bénéfices tangibles qui justifient le changement de paradigme.
La robustesse des applications s'améliore considérablement. En réduisant la dépendance à des formulations précises, les systèmes deviennent moins fragiles face aux variations d'usage. Un utilisateur peut formuler sa requête de multiples façons ; tant que le contexte pertinent est présent, la réponse sera de qualité.
La portabilité entre modèles se trouve facilitée. Un contexte bien structuré fonctionne avec GPT-4, Claude, Gemini ou des modèles open source, avec des ajustements minimes. Les prompts hyper-optimisés pour un modèle spécifique, en revanche, perdent souvent leur efficacité lors d'une migration.
La maintenabilité du code s'améliore. Les templates de contexte sont plus lisibles et modulaires que des prompts monolithiques. Les différentes sources d'information sont clairement identifiées, facilitant le debugging et l'évolution du système.
L'évaluation devient plus systématique. On peut mesurer la qualité du contexte indépendamment de la génération : les bons documents ont-ils été récupérés ? Les informations utilisateur sont-elles à jour ? Ces métriques intermédiaires permettent un diagnostic fin des problèmes.
| Bénéfice | Explication |
|---|---|
| Robustesse | Moins sensible aux variations de formulation |
| Portabilité | Contexte transférable entre modèles |
| Maintenabilité | Code modulaire et lisible |
| Évaluabilité | Métriques intermédiaires possibles |
| Scalabilité | Patterns réutilisables et automatisables |
Conclusion
Le Context Engineering marque une évolution naturelle dans notre manière de construire des applications d'IA générative. Là où le Prompt Engineering traitait le LLM comme une boîte noire capricieuse qu'il fallait apprivoiser avec les bons mots, le Context Engineering le considère comme un raisonneur capable qui a simplement besoin des bonnes informations pour produire des résultats pertinents.
Cette transition reflète la maturation de la technologie. Les modèles de langage actuels sont suffisamment robustes pour comprendre l'intention derrière des requêtes imparfaites. Le facteur limitant n'est plus leur sensibilité à la formulation, mais l'exhaustivité et la pertinence du contexte qu'on leur fournit. Un prompt parfait avec un contexte pauvre produira toujours un résultat médiocre ; un prompt basique avec un contexte riche donnera généralement une excellente réponse.
Pour les équipes qui développent des applications LLM, ce changement de perspective a des implications concrètes. L'effort d'ingénierie se déplace vers la conception de pipelines de données qui alimentent les modèles en information pertinente : systèmes RAG sophistiqués, intégrations avec les sources de données métier, agents capables d'enrichir dynamiquement leur contexte. Les compétences requises évoluent également, avec une importance croissante accordée à l'architecture de données et à l'orchestration.
Le Prompt Engineering ne disparaît pas — formuler clairement ses attentes reste utile — mais il devient une composante parmi d'autres plutôt que le centre de gravité des efforts. L'avenir appartient aux systèmes qui savent orchestrer intelligemment le contexte, en fournissant au bon moment les bonnes informations pour que le LLM puisse raisonner avec toutes les cartes en main.


