Falco : détection d'intrusions runtime
Falco s'est imposé comme l'outil de référence pour la détection d'intrusions runtime dans les environnements cloud-native. Développé initialement par Sysdig puis donné à la Cloud Native Computing Foundation (CNCF), ce projet open source surveille en temps réel le comportement des applications et des conteneurs pour identifier les activités suspectes au moment même où elles se produisent.

Falco s'est imposé comme l'outil de référence pour la détection d'intrusions runtime dans les environnements cloud-native. Développé initialement par Sysdig puis donné à la Cloud Native Computing Foundation (CNCF), ce projet open source surveille en temps réel le comportement des applications et des conteneurs pour identifier les activités suspectes au moment même où elles se produisent.
Dans un contexte où les architectures Kubernetes et les microservices dominent, les approches traditionnelles de sécurité périmétrique ne suffisent plus. Les menaces peuvent émerger de l'intérieur : un conteneur compromis, une application exploitée, un processus malveillant qui s'exécute là où il ne devrait pas. C'est précisément ce que Falco permet de détecter. Que vous soyez ingénieur sécurité cherchant à renforcer la protection de vos clusters, DevOps soucieux de la sécurité de vos déploiements ou simplement curieux de comprendre comment fonctionne la détection d'intrusions moderne, cet article vous présente Falco, son fonctionnement et ses avantages.
Comprendre la détection runtime
Avant de plonger dans Falco, il est essentiel de comprendre ce que signifie la détection runtime et pourquoi elle est devenue indispensable dans les environnements modernes.
La sécurité traditionnelle se concentre souvent sur deux moments : avant le déploiement (scan d'images, analyse de code) et au niveau réseau (pare-feu, WAF). Mais que se passe-t-il une fois que l'application tourne ? Un conteneur peut passer tous les contrôles de sécurité à la compilation et être compromis en production via une vulnérabilité zero-day ou une mauvaise configuration. C'est là qu'intervient la détection runtime : elle observe ce qui se passe pendant l'exécution des workloads.
Concrètement, la détection runtime surveille les comportements anormaux :
- Un shell qui s'ouvre dans un conteneur censé uniquement servir des pages web
- Une connexion réseau sortante inattendue vers une adresse suspecte
- Un fichier sensible lu ou modifié comme
/etc/shadowou des credentials - Un processus qui s'exécute alors qu'il ne fait pas partie de l'image d'origine
- Une élévation de privilèges ou un changement de namespace
Ces signaux, pris individuellement ou corrélés, révèlent souvent une compromission en cours. L'objectif n'est plus seulement d'empêcher les attaques, mais de les détecter rapidement pour limiter leur impact. Dans un monde où le temps moyen de détection d'une intrusion se compte encore en semaines voire en mois, la détection runtime change la donne.
Comment fonctionne Falco
Falco repose sur une architecture élégante qui lui permet d'observer le système avec un minimum d'overhead tout en offrant une grande flexibilité dans la définition des règles de détection.
L'observation au niveau kernel
La puissance de Falco réside dans sa capacité à intercepter les appels système (syscalls) directement au niveau du noyau Linux. Chaque action significative sur un système Unix passe par un syscall : ouvrir un fichier, établir une connexion réseau, créer un processus, modifier des permissions. En observant ce flux, Falco obtient une vision exhaustive de ce qui se passe réellement sur la machine.
Pour capturer ces événements, Falco propose plusieurs drivers :
- Le module kernel : approche traditionnelle, très performante mais nécessitant un module chargé dans le noyau
- eBPF (extended Berkeley Packet Filter) : technologie moderne permettant d'exécuter du code sandboxé dans le kernel sans charger de module, plus sûr et souvent privilégié en production
- Le plugin moderne : Falco peut également ingérer des événements depuis d'autres sources comme les logs d'audit Kubernetes ou les trails CloudTrail AWS
Cette capture bas niveau garantit que rien n'échappe à Falco : même si un attaquant tente de masquer ses actions au niveau applicatif, les syscalls trahissent son activité.
Le moteur de règles
Une fois les événements capturés, Falco les analyse à travers son moteur de règles. Chaque règle définit une condition à surveiller et l'alerte à déclencher si cette condition est remplie. La syntaxe est déclarative et lisible :
- rule: Terminal shell in container
desc: A shell was spawned in a container
condition: >
spawned_process and container and shell_procs
output: >
Shell spawned in container (user=%user.name container=%container.name
shell=%proc.name parent=%proc.pname cmdline=%proc.cmdline)
priority: WARNING
tags: [container, shell, mitre_execution]
yaml
Cette règle détecte l'ouverture d'un shell interactif dans un conteneur, comportement souvent révélateur d'une intrusion ou d'une mauvaise pratique. Falco est livré avec un ensemble de règles par défaut couvrant les menaces les plus courantes, mais sa vraie force est la possibilité de créer des règles personnalisées adaptées à votre contexte.
Les règles peuvent exploiter de nombreux champs : nom du processus, utilisateur, conteneur, image, namespace Kubernetes, fichiers accédés, connexions réseau... Cette richesse permet de définir des politiques de sécurité très précises, du type "aucun processus autre que nginx ne doit écouter sur le port 80 dans les pods du namespace production".
Déployer et utiliser Falco
L'intégration de Falco dans un environnement existant est relativement straightforward, particulièrement dans un contexte Kubernetes où il s'intègre naturellement.
Installation sur Kubernetes
La méthode recommandée pour déployer Falco sur Kubernetes passe par Helm :
helm repo add falcosecurity https://falcosecurity.github.io/charts
helm install falco falcosecurity/falco --namespace falco --create-namespace
bash
Falco se déploie alors comme un DaemonSet, c'est-à-dire qu'une instance tourne sur chaque nœud du cluster. Cette architecture garantit une couverture complète : chaque syscall émis par n'importe quel pod est capturé par l'instance Falco locale.
À découvrir : notre formation DevOps Engineer
Pour les environnements de production, plusieurs options de configuration méritent attention :
- Le choix du driver (eBPF généralement préféré pour sa stabilité)
- L'activation de Falco Sidekick pour router les alertes vers vos systèmes de monitoring
- Le tuning des règles pour réduire les faux positifs spécifiques à votre environnement
Intégration avec l'écosystème
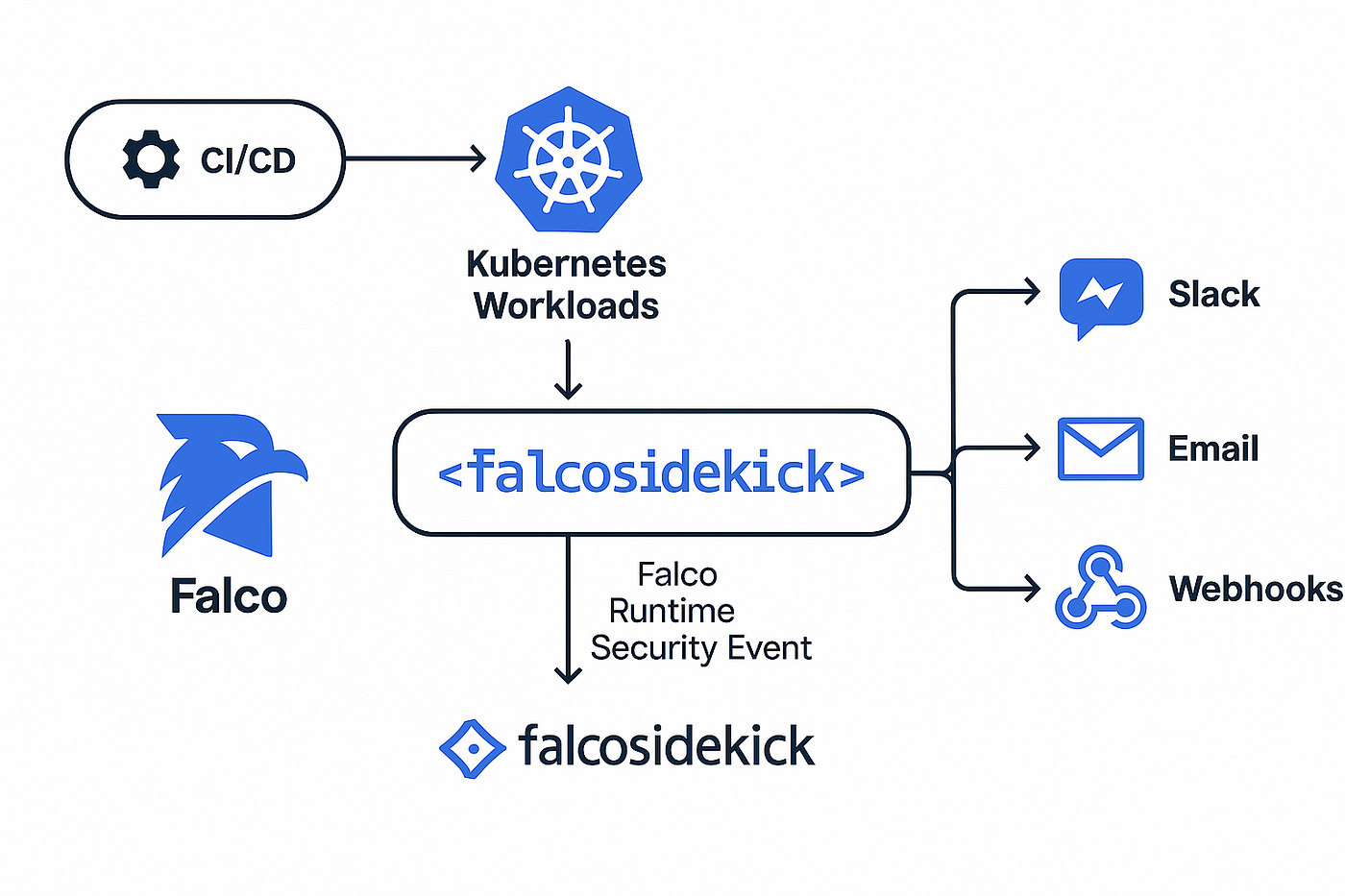
Détecter une menace n'a de valeur que si l'alerte atteint les bonnes personnes au bon moment. Falco Sidekick est le compagnon indispensable qui permet de router les alertes vers pratiquement n'importe quelle destination :
- SIEM : Splunk, Elasticsearch, Sumo Logic
- Messagerie : Slack, Microsoft Teams, Discord
- Incident management : PagerDuty, Opsgenie
- Stockage : S3, GCS pour l'archivage
- Serverless : AWS Lambda, Cloud Functions pour des réponses automatisées
Cette flexibilité permet d'intégrer Falco dans votre workflow de sécurité existant. Les alertes peuvent alimenter un dashboard Grafana, créer automatiquement des tickets, ou même déclencher des actions de remédiation comme l'isolation d'un pod compromis.
Avantages par rapport aux approches traditionnelles
Falco se distingue des outils de sécurité traditionnels par plusieurs caractéristiques qui le rendent particulièrement adapté aux environnements cloud-native.
Visibilité profonde sans agent applicatif. Contrairement aux solutions qui nécessitent d'instrumenter chaque application, Falco observe depuis le kernel. Cela signifie une couverture immédiate de tous les workloads, y compris les conteneurs tiers ou legacy, sans modification du code ou des images. Cette approche agentless (au niveau applicatif) simplifie considérablement le déploiement.
Détection comportementale vs signatures. Les antivirus traditionnels reposent sur des signatures de malwares connus. Falco adopte une approche comportementale : il détecte des actions suspectes indépendamment du malware utilisé. Un cryptominer jamais vu déclenchera quand même une alerte s'il ouvre des connexions vers des mining pools ou consomme anormalement du CPU.
Adaptation native à Kubernetes. Falco comprend les concepts Kubernetes : il enrichit chaque événement avec le contexte (pod, namespace, deployment, labels). Cette conscience du contexte permet des règles précises et des alertes exploitables. Comparez "le processus 12345 a ouvert /etc/passwd" avec "le pod payment-service dans le namespace production a tenté de lire /etc/passwd" : l'information contextuelle change tout pour l'investigation.
Open source et extensible. Porté par la CNCF (au niveau graduated, le plus haut niveau de maturité), Falco bénéficie d'une communauté active et d'une roadmap transparente. Les règles de la communauté couvrent de nombreux scénarios, et l'architecture de plugins permet d'étendre Falco à de nouvelles sources de données comme les logs cloud.
Performance optimisée. Grâce à eBPF et à un filtrage efficace au niveau kernel, Falco ajoute un overhead minimal (généralement moins de 1% de CPU). Cette légèreté permet un déploiement en production sans crainte d'impact sur les performances des applications.
Bonnes pratiques pour une utilisation efficace
Déployer Falco est une première étape, mais en tirer toute la valeur demande quelques ajustements et une approche méthodique.
Commencez en mode observation. Avant d'activer des réponses automatiques, laissez Falco tourner quelques semaines pour comprendre le comportement normal de vos workloads. Cette phase permet d'identifier les faux positifs et d'ajuster les règles. Un shell légitime dans un conteneur de debugging ne doit pas déclencher la même réponse qu'un shell dans un conteneur de production.
Personnalisez les règles par namespace ou workload. Les règles par défaut sont un excellent point de départ, mais chaque environnement a ses spécificités. Utilisez les exceptions et les listes pour affiner la détection. Un conteneur de CI/CD aura des comportements très différents d'un pod applicatif stateless.
Intégrez Falco dans votre chaîne d'incident response. Une alerte qui n'est pas traitée ne sert à rien. Définissez des playbooks clairs : qui est notifié, quel est le processus d'investigation, quelles actions de containment sont possibles. Falco Sidekick peut automatiser les premières étapes, comme isoler un pod suspect du réseau.
Surveillez Falco lui-même. Comme tout composant de sécurité, Falco peut être ciblé par des attaquants. Assurez-vous que ses logs et métriques sont collectés, et créez des alertes si Falco cesse de fonctionner sur un nœud.
Conclusion
Falco représente une évolution majeure dans la manière d'aborder la sécurité des environnements containerisés. En observant le comportement réel des workloads au niveau le plus bas du système, il comble un angle mort critique que les approches traditionnelles (scan d'images, firewalls réseau) ne peuvent pas couvrir.
Dans un paysage où les attaques deviennent plus sophistiquées et où le temps de réponse est crucial, disposer d'une détection runtime efficace n'est plus optionnel. Falco, avec son intégration native Kubernetes, sa flexibilité de règles et son écosystème mature, s'impose comme la solution de référence pour les organisations adoptant le cloud-native. Que vous gériez quelques conteneurs ou des milliers de pods répartis sur plusieurs clusters, Falco offre la visibilité nécessaire pour détecter les menaces avant qu'elles ne causent des dommages. L'essayer, c'est comprendre qu'on ne peut plus s'en passer.


