Feature Engineering : définition et exemples
L’ingénierie des fonctionnalités ou en anglais, Feature Engineering est le processus de sélectionner et transformer les variables les plus pertinentes à partir de données brutes, dans l'objectif d’obtenir les meilleurs performances pour les modèles de Machine Learning. Cette notion est une partie indispensable du prétraitement des données et elle est reconnue pour être la clé du succès dans le domaine du Machine Learning.

Lorsque votre objectif est d’obtenir les meilleurs résultats possibles à partir d’un modèle prédictif, vous devez tirer le maximum de ce que vous avez comme données d'entrainement. L’ingénierie des fonctionnalités ou en anglais, Feature Engineering est le processus de sélectionner et transformer les variables les plus pertinentes à partir de données brutes, dans l'objectif d’obtenir les meilleurs performances pour les modèles de Machine Learning. Cette notion est une partie indispensable du prétraitement des données et elle est reconnue pour être la clé du succès dans le domaine du Machine Learning.
Mais comment procède-t-on au Feature Engineering en pratique ? Quelles sont ses techniques ? Comment et quand faut-il utiliser chacune de ces techniques ? C'est ce que nous allons détailler dans cet article.
Qu’est-ce que le Feature Engineering ?
En Machine Learning, tous les algorithmes d’apprentissage automatique utilisent des données d’entrée pour créer des sorties. Ces données d’entrée comprennent des caractéristiques (ou features), qui sont généralement sous forme de colonnes structurées. Les algorithmes nécessitent des fonctionnalités avec certaines caractéristiques spécifiques pour fonctionner correctement.
À lire aussi : découvrez notre formation MLOps
Ici, le besoin d’ingénierie des fonctionnalités se pose. Il s’agit de transformer les données en formes adaptées à la modélisation et qui ont plus de pertinence. L’ingénierie des fonctionnalités a principalement deux objectifs :
- Préparer l’ensemble de données d’entrée approprié, compatible avec les exigences de l’algorithme d’apprentissage automatique.
- Améliorer les performances des modèles.
Prenons comme exemple les données suivantes appartenant à un restaurant pour mieux comprendre.

La première colonne représente des commandes faites dans un restaurant, ces commandes sont référées à l’aide d'un identifiant unique. La deuxième colonne représente l'heure de passage de chaque commande.
Supposons que l'on souhaite utiliser ces données pour avoir une idée sur la rentabilité du restaurant et à quel point il est occupé.
Le problème ici, c'est que ces données dans leur forme actuelle ne donne aucune information pertinente. Il faut donc les traiter et changer la façon dans laquelle elles sont présentées pour les rendre plus adaptées à la situation.
Une méthode de Feature Engineering possible dans ce cas, est d'agréger le nombre de commandes sur une période de temps spécifique (une demi-heure dans ce cas).

On remarque qu'on a obtenu une sorte de fréquence de commandes, ce qui nous permettra de tirer beaucoup plus d'information de ces données, par exemple, durant quelle partie de la journée le restaurant en question est le plus occupé.
Il existe plusieurs autres techniques de Feature Engineering, chacune est adaptée à des situations bien précises. On peut citer, par exemple, la sélection des données, la normalisation ou la numérisation.
Quelles sont les techniques de Feature Engineering en Machine Learning ?
En fonction des données et du problème à résoudre, on utilise les différentes méthodes de Feature Engineering. Il est indispensable tout d'abord prendre du temps pour comprendre ses données et pour choisir laquelle des approches est à adopter. Ensuite, il faut comprendre les techniques de Feature Engineering, le rôle de chacune et comment l'appliquer.
Traitement des valeurs manquantes
Les valeurs manquantes sont l’un des problèmes les plus courants qu'on peut rencontrer lorsqu'on essaye de préparer ses données. La raison de ces derniers pourrait être des erreurs humaines, des interruptions dans le flux de données ou bien des préoccupations en matière de confidentialité,
La plupart des algorithmes n’acceptent pas les ensembles de données avec des valeurs manquantes et retournent un message d'erreur. Pour remédier à ce problème, il existe deux méthodes :
Imputation catégorique : lorsque les valeurs de la colonne en questions sont catégoriques, les cases manquantes sont généralement remplies par la valeur la plus courante dans d’autres enregistrements.
data['column_name'].fillna(data['column_name'].value_counts().idxmax(), inplace=True)
python
Imputation numérique : dans le cas ou les valeurs de la colonne en question sont numériques et non pas catégoriques, on remplace les données manquantes par la moyenne ou la médiane de la valeur correspondante dans d’autres enregistrements.
data = data.fillna(data.median())
data = data.fillna(data.mean())
python
Traitement des valeurs aberrantes
La manipulation des valeurs aberrantes est une technique permettant de supprimer les valeurs aberrantes d’un ensemble de données. Généralement, ce type de valeurs est détecté par visualisation de l'ensemble de données. Le traitement de ces valeurs sert à produire une représentation plus précise des données.
Pour ce faire, il existe trois méthodes.
- La suppression : les entrées contenant des valeurs aberrantes sont supprimées de la distribution. Cependant, s’il y a des valeurs aberrantes dans de nombreuses variables, cette stratégie peut faire en sorte qu’une grande partie de la feuille de données soit manquée.
- Remplacement des valeurs : autrement, les valeurs aberrantes pourraient être traitées comme des valeurs manquantes et remplacées par une imputation appropriée.
- Discrétisation : la discrétisation est le processus qui consiste à diviser les valeurs possibles de la variable en N groupes, où chaque groupe porte le même nombre d'observations. Ceci est particulièrement utile pour les variables asymétriques, car il répartit les observations de manière égale sur les différents groupes. On trouve ensuite les limites des intervalles en déterminant les quantiles pour remplacer les valeurs maximum et minimum.
À lire aussi : découvrez notre formation MLOps
Cela peut s’appliquer aux valeurs numériques ainsi qu’aux valeurs catégoriques et pourrait aider à éviter le débordement des données, mais au prix de la perte de granularité des données.
# Réaliser une discrétisation avec 3 groupes.
data['new_bin'] = pd.qcut(data['points'], q=3)
python
points new_bin
0 4 (3.999, 10.667]
1 4 (3.999, 10.667]
2 8 (3.999, 10.667]
3 12 (10.667, 19.333]
4 13 (10.667, 19.333]
5 15 (10.667, 19.333]
6 23 (19.333, 25.0]
7 25 (19.333, 25.0]
console
Normalisation
Après une opération de normalisation ou mise à l’échelle, les caractéristiques continues deviennent similaires en termes de portée et appartiennent par conséquence à un intervalle spécifique. Bien que cette étape ne soit pas nécessaire pour de nombreux algorithmes, c’est tout de même une bonne idée de le faire. Les algorithmes basés sur la distance comme k-NN et k-means, d’autre part, nécessitent des fonctionnalités continues à l’échelle comme entrée de modèle. Il existe deux façons courantes pour le faire.
Min Max Scaling
Ce processus implique le redimensionnement de toutes les valeurs d’une caractéristique dans la plage 0 à 1. En d’autres termes, la valeur minimale dans la plage d’origine prendra la valeur 0, la valeur maximale prendra 1 et le reste des valeurs entre les deux extrêmes sera correctement mis à l’échelle.
from sklearn.preprocessing import MinMaxScaler
data['column_name']=MinMaxScaler().fit_transform(data['column_name'])
python
Standardisation
C'est le processus consistant à mettre à l’échelle les valeurs de données de manière à ce qu’elles acquièrent les propriétés de la distribution normale standard. Cela signifie que les données sont rééchelonnées de telle sorte que la moyenne devient zéro et que les données ont un écart-type unitaire.
data['column_name'] = (data['column_name']-data['column_name'].mean())/data['column_name'].std()
python
Transformation logarithmique
Cette méthode n'est applicable que lorsqu'on est sûr que toutes les valeurs de la caractéristique sont positives. Elle est principalement utilisée pour transformer une distribution asymétrique en une distribution normale ou moins asymétrique.
import numpy as np
data['column_name'] = np.log(data['column_name'])
python
L’extraction des caractéristiques
La création de fonctionnalités implique de tirer de nouvelles fonctionnalités de celles existantes. Cela peut être fait par fusionnement de certaines colonnes en utilisant de simples opérations mathématiques telles que des agrégations pour obtenir la moyenne, la médiane, le mode, la somme ou la différence et même le produit de deux valeurs. On peut parfois aussi répandre une colonne en deux autres ou plus.
Le choix des colonnes a traité et le traitement à effectuer dépend de la problématique à résoudre et de la variable à prédire à la fin, et donc cela nécessite une bonne compréhension de ses données et du domaine.
Encodage de variables
Les ensembles de données peuvent contenir différents types de données (chaines de caractères, objets...). En Machine Learning, la plupart des modèles n'acceptent que des données de types numériques. C'est le besoin d'un encodage de données non numériques en données numérique qui se pose. Pour ce faire, deux méthodes peuvent être utilisées.
Encodage des étiquettes
Cette approche est très simple. On convertit chaque valeur d’une colonne en un nombre de sortes que chaque étiquette ait un nombre unique propre à elle. Cette méthode est la plus utiliser pour encoder une colonne.
from sklearn.preprocessing import LabelEncoder
labelencoder = LabelEncoder()
data['column_name']= labelencoder.fit_transform(data['column_name'])
python
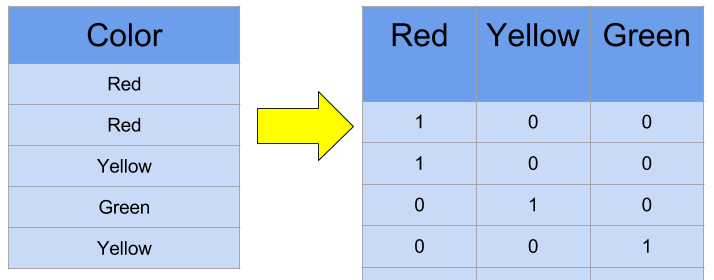
Encodage One-Hot
Cette méthode consiste à créer une colonne pour chaque étiquette. Les valeurs catégoriques sont converties en simples valeurs numériques 1 et 0 sans perte d’information. Ce type d'encodage présente ses propres inconvénients et doit être utilisée avec parcimonie. Elle pourrait en résulter une augmentation spectaculaire du nombre de caractéristiques et la création de caractéristiques fortement corrélées.
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(handle_unknown='ignore')
data['column_name']= enc.fit_transform(data['column_name'])
python
La sélection de caractéristiques
La sélection des variables (ou Feature Selection en anglais), est le processus de sélection des variables les plus importantes à utiliser dans les algorithmes Machine Learning.
Des techniques de sélection des variables sont utilisées pour réduire le nombre de variables d’entrée en éliminant les fonctionnalités redondantes ou non pertinentes pour le modèle. Parmi ces techniques, on peut citer :
-
Les méthodes d’encapsulation calculent les modèles avec un certain sous-ensemble de caractéristiques et évaluent l’importance de chaque caractéristique. Puis ils itèrent et essaient un sous-ensemble différent de fonctionnalités jusqu’à ce que le sous-ensemble optimal soit atteint.
-
Les méthodes de filtrage consistent à effectuer un ou plusieurs tests statistiques pour sélectionner les caractéristiques qui ont la relation la plus forte avec la variable de sortie comme le coefficient de corrélation, la MAD (moyenne absolue des différences), ou le ratio de dispersion.
-
Les méthodes intégrées dans des algorithmes combinent les qualités des méthodes de filtrage et d’encapsulation. Ce sont des méthodes de sélection de variable intégrées dans les modèles de Machine Learning. Un des exemples les plus populaires de ces méthodes est la régression pénalisée (par exemple la régularisation de type L1/Lasso et L2/Ridge). C'est un type de régularisation qui force le modèle à atteindre un équilibre entre performance et nombre de dimensions retenues. Ils permettent d’effectuer la sélection de variable selon les résultats d'une fonction de pénalité qui attribue un poids à chaque variable.
Pourquoi le Feature Engineering est si important ?
Sans données compréhensibles et adaptées a la modélisation, les meilleurs algorithmes de Machine Learning ne donneraient que peu de résultats. Pour donner à ces derniers leur pouvoir, un travail de Feature Engineering doit être réalisé.
À lire aussi : découvrez notre formation MLOps
Mais pourquoi l'ingénierie des caractéristiques est si importante ?
- En réalité, les données brutes peuvent être très chaotiques et mal organisées. Sachant que la plupart des modèles Machine Learning et Deep Learning exigent un format spécifique de données, le Feature Engineering se charge de créer ce lien entre le modèle et les données en rendant ces derniers adaptées pour alimenter un modèle.
- Une bonne ingénierie de caractéristique permettra d'éliminer les variables non pertinentes et conserver seulement celles qui apportent le plus d'information et donc améliorer la performance du modèle et éviter le sur-apprentissage.
- Certains modèles sont très sensibles aux valeurs aberrantes. Toute valeur trop éloignée du reste peut avoir un effet négatif sur leur rendement. Parmi ces modèles, on a le SVM, la régression linéaire et logistique, le k-means et le KNN. Il est alors nécessaire de traiter ces valeurs-là avec du Feature Engineering lorsqu'on choisit de travailler avec l'un de ces modèles.
L’inconvénient le plus important de l’utilisation de l’ingénierie des fonctionnalités est que les risques majeurs viennent avec elle. Pour être précis, si on n’a pas une connaissance considérable du domaine avec lequel on travaille, on risque de brouiller ses données. Il faut alors prendre son temps pour comprendre et préciser la problématique en question, le domaine et la signification de chaque variable de ses données.


