Introduction à pandas sous Python
L'une des bibliothèques utiliser pour le prétraitement des données est Pandas. Si vous avez travaillé avec des données tabulaires avant, vous l'avez certainement utilisé. C'est une bibliothèque du langage de programmation Python utilisée pour la manipulation et l’analyse des données.

Le traitement des données est une étape fondamentale dans le cycle de vie d'un projet Data Science. Certains domaines, tels que le traitement de langage naturel, demandent une grande quantité de traitement de données avant de pouvoir faire intervenir des modèles de Machine et Deep Learning.
L'une des bibliothèques utiliser pour le prétraitement des données est Pandas. Si vous avez travaillé avec des données tabulaires avant, vous l'avez certainement utilisé. C'est une bibliothèque du langage de programmation Python utilisée pour la manipulation et l’analyse des données. Si vous envisagez la science des données comme une carrière, alors il est impératif que l’une des premières choses que vous faites est d’apprendre à utiliser Pandas.
Dans cet article, nous allons détailler la notion des DataFrames et nous allons voir comment utiliser la bibliothèque Pandas pour manipuler des données tabulaires.
Les DataFrames, qu'est-ce que c'est ?
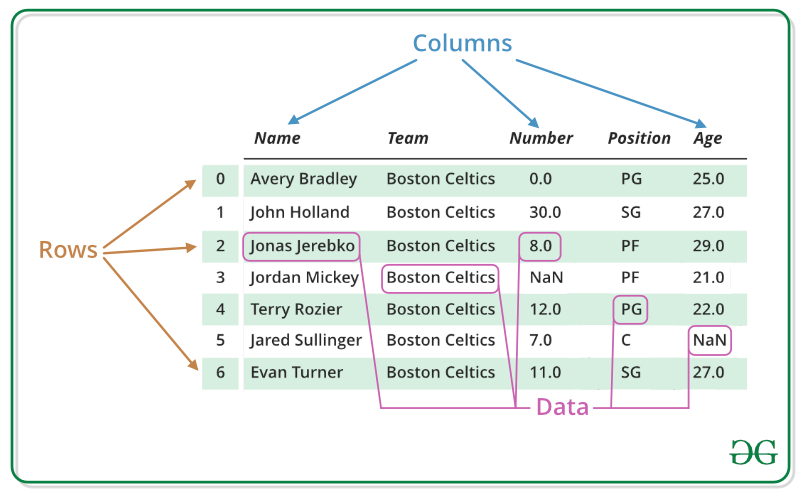
Avant de commencer à parler de Pandas, regardant d'abord ce que sont les DataFrames. Les DataFrames, ou trames de données en français, sont un moyen de stocker des données dans des grilles rectangulaires qui peuvent facilement être survolées. Chaque ligne de ces grilles correspond aux mesures ou valeurs d’une instance, tandis que chaque colonne est un vecteur contenant des données pour une variable spécifique.
À lire aussi : découvrez notre formation MLOps
Ils sont définis comme des structures de données étiquetées en deux dimensions avec des colonnes de types potentiellement différents. Les lignes d’une DataFrame peuvent contenir des données numériques, des chaines de caractères, des objets logiques, et ils peuvent même être vides.
En général, on pourrait dire que le Pandas DataFrame se compose de trois composantes principales : les données, l’index et les colonnes. On peut spécifier les index et les noms de colonnes pour un DataFrame. L’index, d’une part, indique la différence dans les lignes, tandis que les noms des colonnes indiquent la différence dans les colonnes. Ces deux composants seront utiles lorsqu'on va manipuler des données.
Un DataFrame peut aussi contenir d'autres types d'objets :
- Une série Pandas : un tableau étiqueté unidimensionnel capable de contenir tout type de données avec des étiquettes d’axe ou d’index. Un exemple d’objet Série est une colonne d’un DataFrame.
- Un tableau : NumPy
ndarray, unidimensionnel ou bidimensionnel. - Un dictionnaire : peut contenir des ndarray unidimensionnel, listes, dictionnaires ou séries.
Il existe plusieurs moyens et plusieurs librairies sous Python pour manipuler des trames de données. L'un des moyens les plus populaires est Pandas.
Principales caractéristiques de Pandas
Pandas est une librairie de gestion de données, extrêmement populaire et incontournable dans le monde de la Data Science. Elle est une surcouche à NumPy, et donc hérite de toutes les fonctions (moyenne, tri, statistiques, ...) déjà présentes dans NumPy.
Pandas prend des données, comme une base de données CSV ou SQL, et en crée un DataFrame. Il fournit des outils de manipulation de données de haut niveau, notamment des outils pour :
- Lire et écrire des données de différents formats (CSV, Excel, JSON, ...)
- Effectuer des requêtes SQL sur des données.
- Manipuler des tables de données (ajouter, supprimer, modifier des lignes et des colonnes ...)
- effectuer des calculs sur les données (agrégation, filtrage, ...)
Pandas est simple à apprendre et à utiliser. Les données traitées avec Pandas sont souvent utilisées pour alimenter des analyses statistiques avec SciPy, les fonctions de traçage de Matplotlib et les algorithmes d’apprentissage automatique dans Scikit-learn. Cela rend cette bibliothèque indispensable surtout pour les missions Machine Learning.
Pandas fournit de nombreux avantages :
- C'est une bibliothèque open source et gratuite, ce qui la rend accessible à tous. - Elle permet de manipuler facilement des données de toutes sortes, notamment des tableaux et des matrices.
- Elle est très performante et peut gérer de très gros volumes de données. Elle offre une multitude d'outils pour analyser ces données.
- Elle fournit aussi des outils pour importer et exporter des données.Les données provenant de différents objets de fichiers peuvent être chargées.
Traitement des données avec Pandas
Avant de traiter les données, la première chose à effectuer consiste à créer un DataFrame.
Chargement des données
Pour ce faire, il existe plusieurs méthodes possibles en fonction du type de fichier :
- Pour les fichiers CSV, la fonction
read_csvest efficace, car elle permet également de gérer les fichiers de taille importante en segmentant la lecture bloc par bloc. - Pour les fichiers JSON, la fonction
read_jsonfonctionne sur le même principe. - Pour les connaisseurs de SQL, il existe
read_sqlet bien d'autres.
Par exemple, pour charger des données provenant d'un fichier CSV, il suffit d'exécuter la commande suivante:
data = pd.read_csv("data.csv")
python
Dans ce qui suit, nous allons travailler sur un ensemble de données provenant du jeu de données très connu titanic, qui contient des informations à propos d’un sous-ensemble des passagers du navire Titanic.
Nous allons commencer par importer le jeu de données :
import numpy as np
import pandas as pd
import seaborn as sns
titanic = sns.load_dataset('titanic')
python
Une fonction pratique pour afficher les cinq premières lignes du DataFrame est la fonction head, très pratique lorsque l'on travaille avec plusieurs DataFrames et que l'on souhaite, en un coup d'oeil, se remémorer de la structure d'un DataFrame.
titanic.head()
python

Une propriété qui peut être utile, est le shape (forme) des DataFrame, qui indique le nombre de lignes et de colonnes.
titanic.shape
python
(891, 15)
console
Accès
Pour accéder à une colonne du DataFrame, c'est de la même façon que pour les listes, mais plutôt que d'utiliser la position de la colonne, il suffit de donner son étiquette.
titanic['survived']
python
0 0
1 1
2 1
3 1
4 0
..
886 0
887 1
888 0
889 1
890 0
Name: survived, Length: 891, dtype: int64
console
La librairie pandas dispose des deux types d'indexation : par positionnement et par label. La fonction d'indexation loc effectue une indexation par label et la fonction d'indexation iloc, par positionnement.
# mélanger l’ordre des lignes du DataFrame
import sklearn
titanic=sklearn.utils.shuffle(titanic)
python
# Ligne dont l'indice est le label 87
titanic.loc[87]
python
survived 0
pclass 3
sex male
age 22.0
sibsp 1
parch 0
fare 7.25
embarked S
class Third
who man
adult_male True
deck NaN
embark_town Southampton
alive no
alone False
Name: 0, dtype: object
console
# Ligne dont la position est 87 (88ème ligne)
titanic.iloc[87]
python
survived 0
pclass 3
sex female
age NaN
sibsp 0
parch 0
fare 7.6292
embarked Q
class Third
who woman
adult_male False
deck NaN
embark_town Queenstown
alive no
alone True
Name: 502, dtype: object
console
Filtrage
Nous allons maintenant filtrer pour récupérer uniquement ce qui nous intéresse.
# récupérer que les informations à propos des femmes
titanic[titanic['sex']=='female']
python

Groupement
Le groupement consiste à regrouper les données selon une ou plusieurs variables et d'en agréger certaines afin de pouvoir résumer une information. Nous allons chercher la moyenne d'âge des femmes et des hommes sur le navire :
titanic[["age","sex"]].groupby(by='sex').mean()
python

Modification
La fonction drop permet de supprimer des axes (colonnes ou lignes) d'un DataFrame. Son utilisation est plutôt simple.
Pour supprimer la ligne dont l'index est égal à 0 nous exécutons la ligne suivante :
titanic=titanic.drop(0)
python
Pour supprimer la colonne age nous exécutons la ligne suivante :
titanic=titanic.drop(columns=["age"])
python
Pour ajouter une où plusieurs lignes a un DataFrame, il existe deux méthodes, soit on utilise la fonction loc, dans ce cas, nous pouvons ajouter cette ligne qu'à la fin du DataFrame en specifiant le label de cette ligne :
titanic.loc[0] = [0,3,'female',24.0,0,0,7.5,'First','woman',False,'B','Cherbourg','yes',True ]
titanic.loc[0]
python
survived 0
pclass 3
sex female
sibsp 24
parch 0
fare 0.0
embarked 7.5
class First
who woman
adult_male False
deck B
embark_town Cherbourg
alive yes
alone True
Name: 0, dtype: object
console
La fonction iloc peut être utilisé de la même manière, elle permet de spécifier l'emplacement de la ligne à ajouter.
Exportation de données en format CSV
Après avoir modifié nos données, nous désirons les enregistrer en local en format CSV, il suffit d'exécuter la commande suivante :
titanic_modified.to_csv('<File Path>\titanic_modified.csv')
python
Les meilleurs alternatives à Pandas :
Même si Pandas est la bibliothèque la plus utilisée par les Data Scientists, et malgré sa performance et sa flexibilité, il existe plusieurs autres choix plus convenables dans des situations bien spécifiques, nous prendrons en guise d'exemple :
- Polars est une bibliothèque conçue pour traiter les données avec un temps d’éclairage rapide en implémentant le langage Rust et en utilisant Arrow comme base. Polars donne aux utilisateurs une expérience plus rapide par rapport à Pandas. La situation idéale pour utiliser Polars est lorsque nous avons des données trop volumineuses pour Pandas, mais trop petites pour utiliser Spark.
- Dask offre la possibilité de traiter des données tabulaires sous forme de DataFrames comme Pandas, mais avec Dask les données sont traitées en parallèle pour accélérer le temps d’exécution. Dask offre aussi un planificateur de tâches.
- Vaex est une bibliothèque Python utilisé pour le traitement et l’exploration de grands ensembles de données tabulaires avec des interfaces similaires à Pandas. L'utilisation de Vaex est proche de celle de Pandas.
À lire aussi : découvrez notre formation MLOps
Explorer, nettoyer, transformer et visualiser des données avec des pandas en Python est une compétence essentielle pour un Data Scientist. Maîtriser cet outil permettra non seulement d’avoir plus de contrôle sur les données d’entrée, mais aussi donnera plus de flexibilité et de puissance lors de l’exploration de données.


