LightGBM : mieux que XGBoost ?
Les modèles basés sur le renforcement de gradient et leurs variantes offertes par plusieurs communautés ont gagné beaucoup de traction ces dernières années. LightGBM, développé par Microsoft et publié en 2016, représente un exemple très populaire. Il est rapide, distribué et de haute performance. Basé sur des algorithmes d'arbre de décision, il est utilisé pour le classement, la classification et de nombreuses autres tâches de Machine Learning. Il représente aussi une excellente alternative à XGBoost.

Les modèles basés sur le renforcement de gradient et leurs variantes offertes par plusieurs communautés ont gagné beaucoup de traction ces dernières années. LightGBM (Light Gradient Boosting Machine), développé par Microsoft et publié en 2016, représente un exemple très populaire. Il est rapide, distribué et de haute performance. Basé sur des algorithmes d’arbre de décision, il est utilisé pour le classement, la classification et de nombreuses autres tâches de Machine Learning. Il représente aussi une excellente alternative à XGBoost (eXtreme Gradient Boosting).
Dans cet article, nous examinerons le concept de renforcement de gradient, nous allons détailler le fonctionnement de l'algorithme LightGBM, en quoi son utilisation et ses applications sont variées ainsi que les différences fondamentales entre XGBoost et LightGBM.
Qu'est-ce que le renforcement de gradient ?
Avant de détailler les algorithmes, comprenons rapidement le concept fondamental de renforcement de gradient (Gradient Boosting) qui fait partie à la fois de XGBoost et de LightGBM. Cette notion fait référence à une méthodologie de Machine Learning dans laquelle l’idée est de former plusieurs modèles utilisant le même algorithme d’apprentissage. Une combinaison de modèles individuels créant un modèle plus fort et plus puissant. Il s'agit de centaines ou de milliers d’apprenants très dépendants les uns des autres, avec un objectif commun fusionnés pour résoudre un problème. Ces modèles sont généralement des arbres de décision.
À lire aussi : découvrez notre formation MLOps
- La première étape consiste à créer un premier modèle de base. Il est entraîné sur les données.
- Ensuite, un second modèle est construit pour tenter de corriger les erreurs présentes dans le premier modèle. Les erreurs sont minimisées par l’algorithme de descente de gradient, chaque arbre ajouté va compenser les erreurs commises précédemment sans détériorer les prédictions qui ont été justes en changeant en cours de route la base d'apprentissage.
- Cette procédure se poursuit et des modèles sont ajoutés jusqu’à ce que l’ensemble complet des données de formation soit prédit correctement ou que le nombre maximal de modèles soit ajouté.
- Les prédictions du dernier modèle ajouté seront les prédictions globales fournies par les anciens modèles d’arbres.

Le renforcement de gradient est l’une des techniques les plus puissantes pour construire des modèles prédictifs. Il existe plusieurs modèles qui se basent sur cette technique dont LightGBM.
Fonctionnement de LightGBM
Light Gradient Boosted Machine, ou LightGBM pour faire court, est un modèle d'apprentissage d'ensemble séquentiel, créé par des chercheurs de Microsoft, se basant sur le renforcement de gradient et des arbres de décision (GBDT ou Gradient Boosting decision Trees).
Ces derniers sont combinés de manière à ce que chaque nouvel apprenant ajuste les résidus de l'arbre précédent afin que le modèle s'améliore. Le dernier arbre ajouté regroupe les résultats de chaque étape et un apprenant puissant est atteint.
Les arbres de décision sont construits en fractionnant les observations (c'est-à-dire les instances de données) en fonction des valeurs des variables. L'algorithme CART recherche la meilleure répartition qui se traduit par le gain d'information le plus élevé qui se calcule en utilisant des outils statistiques comme l’entropie et l’indice de Gini. Pour trouver la meilleure structure de l'arbre, celle qui apporte le plus d'information. On essaye toutes les combinaisons de points de partage possibles, on les évalue et puis on les trie, la structure avec le gain en information le plus élevé est choisie. Ce n'est certainement pas une manière optimale. Cette méthode est de plus en plus lente que la taille du jeu de données augmente est elle est utilisée dans la plupart des GBDT.
Avec LightGBM, on vise à résoudre ce problème de temps et de puissance de calcul. Donc on introduit une nouvelle méthode de recherche de la bonne structure d'arbre pour chaque apprenant ajouté. Cette technique se base deux notions clés : GOSS (Gradient-based One-Side Sampling ou échantillonnage d'un côté en dégradé) et EFB (Exclusive Feature Bundling ou Offre groupée de fonctionnalités exclusives).
GOSS (échantillonnage d’un côté en dégradé)
GOSS est une nouvelle méthode d’échantillonnage qui échantillonne les observations en se basant sur les gradients. Les gradients donnent un aperçu précieux du gain d'information.
- Petit gradient: l'algorithme a été entraîné sur cette observation et l'erreur qui lui est associée est faible.
- Grand gradient: l'erreur associée à cette observation est importante, elle fournira donc plus d'informations.
L'approche consiste à écarter les cas ayant de petits gradients en se concentrant uniquement sur les cas ayant de grands gradients, cela modifierait la distribution des données. En un mot, GOSS conserve les instances avec de grands gradients et effectue un échantillonnage aléatoire sur les instances avec des gradients plus petits.
Cela fonctionne comme suit :
- Les instances de données sont triées en fonction de la valeur absolue de leurs gradient
- Les principales instances A sont sélectionnées
- Parmi les instances restantes, un échantillon aléatoire de taille B est sélectionné
- L'échantillon aléatoire de petits gradients est multiplié par une constante égale à lorsque le gain d'information est calculé (A et B étant des pourcentages).
EFB (Offre groupée de fonctionnalités exclusives)
EBF fusionne des variables pour réduire la complexité de l'entrainement. En effet c'est une méthode de réduction de dimension.
Les ensembles de données avec un nombre élevé de caractéristiques sont susceptibles d'avoir des caractéristiques rares (c'est-à-dire beaucoup de valeurs nulles). Ces caractéristiques clairsemées sont généralement mutuellement exclusives, ce qui signifie qu'elles n'ont pas de valeurs non nulles simultanément. Dans ce cas on peut utiliser la EFB pour fusionner deux variables par exemple en une seule.
Cette technique se fait généralement en deux étapes.
1. Déterminer les caractéristiques qui pourraient être regroupées
Cette étape consiste a construire un graphique avec les mesures du conflit entre les variables du jeu de données (La mesure de conflit est la fraction des valeurs non nulles qui se chevauchent et le nombre total des valeurs ).
On va ensuite les trier et si la mesure de conflit est inferieure au seuil, on va créer une nouvelle variable .
2. Fusionnement des variables
À lire aussi : découvrez notre formation MLOps
Après avoir choisi les variables à fusionner, on en construit une nouvelle. Pour comprendre cette étape, prenons cet exemple.
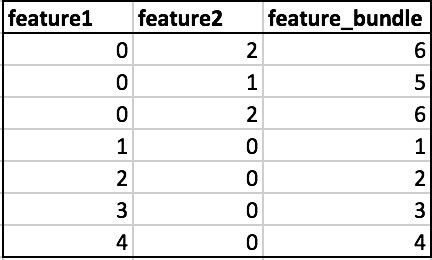
Dans l’exemple ci-dessus, on peut voir que feature1 et feature2 sont mutuellement exclusives. Afin d’obtenir des lignes non chevauchantes, on va calculer conserver les valeurs non nulles de feature1 ( dans ce cas 1,2,3,4), et puis pour feature2, on va sommer les valeurs non nulles avec la plus grande valeur de feature1 (dans ce cas 4) . Cela permet de s’assurer que les points de données non nuls de chaque variable ne sont jamais égaux , et donc confondus. Les instances 5,6 contiennent des instances de feature2 non nulles.
Ensemble, ces deux notions peuvent accélérer le temps d’entraînement de l’algorithme jusqu'à 20 fois. Donc, on peut dire tout simplement que LightGBM peut être considéré comme GBDT avec l’ajout de GOSS et EFB.
Différences entre LightGBM et XGBoost
Comme nous l'avons déjà dit, LightGBM est un modèle de Machine Learning se basant sur le renforcement de gradient et les arbres de décision. Tout comme XGBoost, les deux modèles sont très populaires et reconnus pour leur haute performance. Mais en quoi sont-ils différents alors ?
- LightGBM fait croître l'arbre verticalement grâce à l'algorithme GOSS contrairement à XGBoost qui fait pousser des arbres horizontalement, en d'autres mots LightGBM fait pousser l'arbre par feuille tandis que l'autre algorithme se développe par niveau.

- Il n y a pas de vainqueur au niveau de la performance les deux modèles sont très performants, par contre XGBoost est mieux adapté au jeux de données de petite taille, on risque d'avoir un sur-apprentissage avec de grands volumes de données tandis que LightGBM est son opposé.
- LightGBM est beaucoup plus rapide que XGBoost. Grâce à sa méthode de réduction de dimension (EFB), il est capable de gagner en matière de puissance de calcule tout en conservant la même précision de XGBoost.
Quand utiliser LightGBM ?
Il est devenu difficile pour les algorithmes traditionnels de donner des résultats rapides, car la taille des données augmente rapidement de jour en jour. LightGBM est appelé « Light » ou léger en raison de sa puissance de calcul et de ses résultats plus rapides. Il lui faut moins de mémoire pour fonctionner et est capable de traiter de grandes quantités de données.
- Contrairement au autres modèles basés sur les arbres de décision, qui représentent des risques de sur-apprentissage avec des grands volumes de données, LightGBM n’est pas conçu pour des jeux de données de tailles peu importantes. Il peut facilement être débordé en raison de sa sensibilité au sur-ajustement .
- LightGBM a une meilleure précision que n’importe quel autre algorithme GBDT : Il produit des arbres beaucoup plus complexes en suivant une approche de division foliaire plutôt qu’une approche de niveau qui est le principal facteur pour atteindre une plus grande précision. Cependant, il peut parfois conduire à un débordement qui peut être évité en réglant le paramètre
max_depth. - Il est l'algorithme le plus utilisé dans les hackathons et les compétitions de Machine Learning, ainsi que les concours de Kaggle grâce à sa capacité d’obtenir une bonne précision des résultats et aussi renforcer le GPU penchant.
LightGBM est donc une version améliorée de XGBoost. Néanmoins, ces deux modèles sont très performants. XGBoost est plus populaire chez les Data Scientist du fait de son ancienneté.


