Merging de LLM : comment ça marche ?
Le merging de LLM (ou fusion de modèles) est une technique qui suscite un intérêt croissant dans la communauté de l'IA générative. Plutôt que d'entraîner un nouveau modèle depuis zéro ou de faire du fine-tuning coûteux, cette approche consiste à combiner plusieurs modèles existants pour en créer un nouveau qui hérite des forces de chacun.

Le merging de LLM (ou fusion de modèles) est une technique qui suscite un intérêt croissant dans la communauté de l'IA générative. Plutôt que d'entraîner un nouveau modèle depuis zéro ou de faire du fine-tuning coûteux, cette approche consiste à combiner plusieurs modèles existants pour en créer un nouveau qui hérite des forces de chacun.
Cette méthode est particulièrement attractive car elle permet d'obtenir des modèles performants sur plusieurs tâches sans nécessiter de données d'entraînement supplémentaires ni de ressources computationnelles importantes. En quelques minutes, il devient possible de fusionner deux LLM spécialisés pour créer un modèle polyvalent.
Dans cet article, nous allons explorer le fonctionnement du merging de LLM, comprendre les différentes techniques disponibles, et analyser dans quels cas cette approche s'avère pertinente.
Qu'est-ce que le merging de LLM ?
Le merging de LLM consiste à fusionner les poids de plusieurs modèles pour créer un nouveau modèle unique. Concrètement, au lieu de combiner les sorties de différents modèles à l'inférence (comme dans un système d'ensemble), on opère directement sur leurs paramètres internes pour produire un seul modèle consolidé.
Cette technique repose sur une observation importante : les modèles qui partagent une architecture identique et qui ont été entraînés à partir d'un même modèle de base (comme LLaMA ou Mistral) possèdent des espaces de poids relativement similaires. Cela signifie que leurs paramètres peuvent être combinés de manière cohérente sans détruire les connaissances acquises.
Le merging est particulièrement utilisé dans les scénarios suivants :
- Combiner des spécialisations : fusionner un modèle performant en code avec un modèle excellent en raisonnement mathématique pour obtenir un assistant polyvalent.
- Améliorer les performances générales : combiner plusieurs fine-tunings différents d'un même modèle de base pour bénéficier de leurs améliorations respectives.
- Réduire les coûts : éviter de réentraîner un modèle complet lorsque deux modèles existants couvrent déjà les compétences souhaitées.
À découvrir : notre formation LLM Engineering
Un point crucial à retenir est que le merging ne fonctionne qu'entre des modèles partageant la même architecture. Il est impossible de fusionner un modèle Mistral avec un modèle GPT, car leurs structures internes sont fondamentalement différentes.
Les principales techniques de merging
Plusieurs méthodes ont été développées pour fusionner efficacement des modèles de langage. Chacune présente des caractéristiques spécifiques et s'adapte à des cas d'usage différents.
SLERP (Spherical Linear Interpolation)
La méthode SLERP est l'une des techniques les plus simples et les plus utilisées pour le merging de LLM. Elle effectue une interpolation sphérique entre les poids de deux modèles, permettant une transition progressive de l'un vers l'autre.
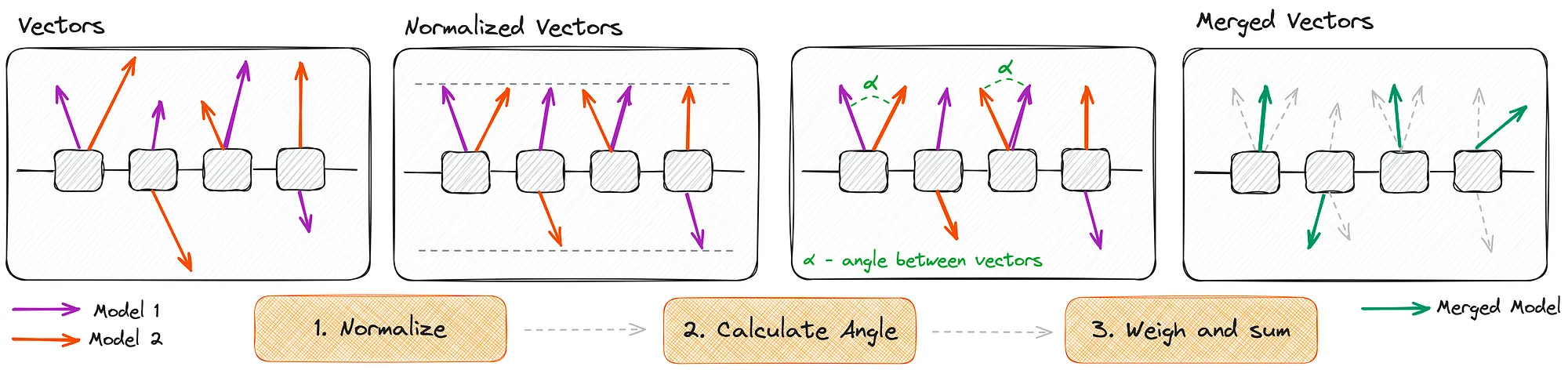
Contrairement à une interpolation linéaire classique qui pourrait réduire la magnitude des vecteurs de poids, SLERP préserve la norme des vecteurs en suivant une trajectoire sur une sphère. Cette propriété est essentielle car elle maintient les propriétés géométriques des espaces de représentation appris par les modèles.
La formule de SLERP est la suivante :
où et sont les poids des deux modèles, est le facteur d'interpolation (entre 0 et 1), et est l'angle entre les deux vecteurs de poids.
SLERP est particulièrement efficace lorsque l'on souhaite créer un modèle équilibré entre deux spécialisations. En ajustant le paramètre , on peut contrôler précisément l'influence de chaque modèle source sur le résultat final.
Task Arithmetic
La méthode Task Arithmetic adopte une approche différente en considérant les modifications apportées par le fine-tuning comme des "vecteurs de tâche" (task vectors). L'idée centrale est que la différence entre un modèle fine-tuné et son modèle de base encode la connaissance spécifique acquise lors de l'entraînement.
Le processus se déroule en plusieurs étapes :
- Calcul des vecteurs de tâche : pour chaque modèle fine-tuné, on soustrait les poids du modèle de base pour obtenir un vecteur représentant l'apprentissage spécifique à la tâche.
- Combinaison des vecteurs : les vecteurs de tâche sont additionnés, potentiellement avec des coefficients de pondération pour contrôler l'importance de chaque tâche.
- Application au modèle de base : le vecteur combiné est ajouté aux poids du modèle de base pour produire le modèle fusionné.
Cette approche permet de fusionner plus de deux modèles facilement et offre une grande flexibilité dans le contrôle de l'influence de chaque spécialisation. Elle est particulièrement adaptée lorsque l'on dispose de plusieurs fine-tunings issus d'un même modèle de base.
TIES (Trim, Elect Sign, and Merge)
La méthode TIES représente une évolution sophistiquée des techniques de merging, conçue pour résoudre les problèmes d'interférence entre les paramètres de différents modèles.
TIES repose sur trois étapes clés :
- Trim (Élagage) : les modifications de paramètres de faible magnitude sont mises à zéro. Cette étape permet de ne conserver que les changements significatifs et de réduire le bruit dans la fusion.
- Elect Sign (Élection du signe) : lorsque différents modèles modifient le même paramètre dans des directions opposées (l'un l'augmente, l'autre le diminue), un mécanisme de vote majoritaire détermine la direction finale à adopter.
- Merge (Fusion) : seuls les paramètres alignés avec le signe élu sont moyennés, les autres étant ignorés.
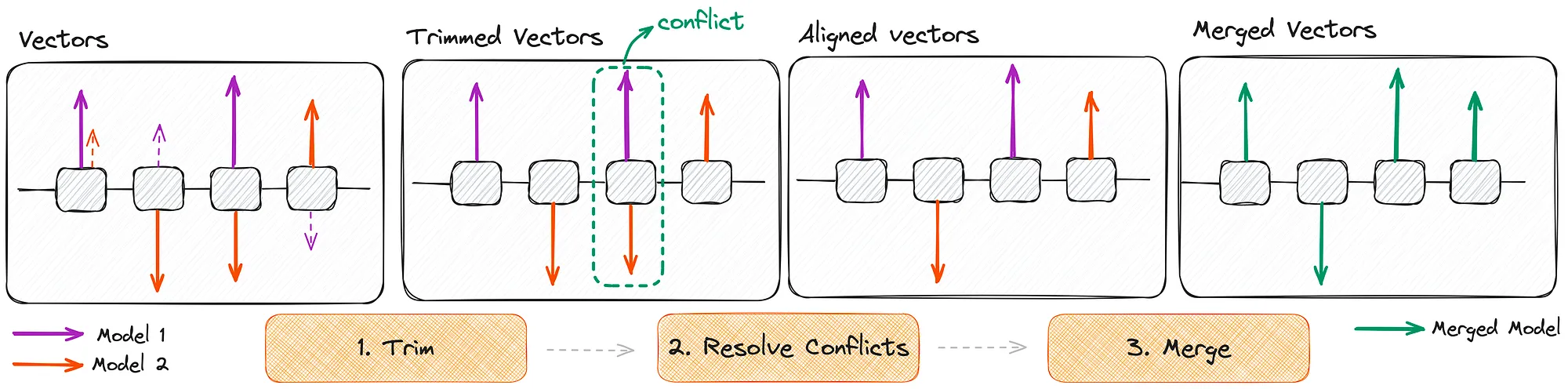
Cette approche est particulièrement efficace pour éviter les conflits entre modèles qui ont appris des comportements contradictoires. Elle produit généralement des résultats plus stables que les méthodes plus simples, notamment lorsque l'on fusionne plusieurs modèles simultanément.
Mise en pratique avec mergekit
La librairie mergekit est devenue l'outil de référence pour effectuer du merging de LLM en pratique. Elle supporte toutes les techniques mentionnées et s'intègre facilement dans un workflow de développement.
Voici un exemple de configuration pour fusionner deux modèles avec la méthode SLERP :
slices:
- sources:
- model: mistralai/Mistral-7B-Instruct-v0.2
layer_range: [0, 32]
- model: codellama/CodeLlama-7b-Instruct-hf
layer_range: [0, 32]
merge_method: slerp
base_model: mistralai/Mistral-7B-Instruct-v0.2
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
yaml
Cette configuration permet de contrôler finement l'interpolation pour différentes parties du modèle (couches d'attention, MLP, etc.), offrant ainsi une granularité importante dans le processus de fusion.
L'exécution se fait ensuite simplement en ligne de commande :
mergekit-yaml config.yaml ./merged_model --cuda
bash
Avantages et inconvénients du merging
Le merging de LLM présente plusieurs avantages significatifs qui expliquent sa popularité croissante :
- Aucune donnée d'entraînement requise : contrairement au fine-tuning, le merging opère uniquement sur les poids des modèles existants. Cela permet de créer rapidement de nouveaux modèles sans collecter ni annoter de données.
- Coût computationnel minimal : la fusion de modèles ne nécessite que quelques minutes de calcul, même sur du matériel modeste. C'est une fraction du temps et des ressources nécessaires pour un entraînement complet.
- Combinaison de compétences : il devient possible de créer des modèles polyvalents en combinant des spécialisations complémentaires, par exemple un modèle expert en code avec un autre performant en raisonnement.
- Expérimentation rapide : la rapidité d'exécution permet de tester de nombreuses combinaisons et configurations pour trouver le meilleur compromis.
Cependant, cette technique comporte également des limites importantes à considérer :
- Contrainte d'architecture : seuls les modèles partageant exactement la même architecture peuvent être fusionnés. Cette limitation réduit considérablement les combinaisons possibles.
- Résultats imprévisibles : contrairement au fine-tuning où l'on optimise explicitement une métrique, le merging peut produire des résultats incertains. Un modèle fusionné peut perdre des capacités que possédaient les modèles sources.
- Pas de nouvelles connaissances : le merging redistribue les connaissances existantes mais n'en crée pas de nouvelles. Si aucun des modèles sources ne maîtrise une compétence, le modèle fusionné ne l'aura pas non plus.
- Interférences potentielles : lorsque les modèles sources ont appris des comportements contradictoires, la fusion peut produire un modèle instable ou aux performances dégradées.
Conclusion
Le merging de LLM représente une approche pragmatique et économique pour créer des modèles personnalisés. En combinant intelligemment des modèles existants, il devient possible d'obtenir des résultats satisfaisants sans investir dans des entraînements coûteux.
Les différentes techniques disponibles (SLERP, Task Arithmetic, TIES) offrent une palette d'outils adaptés à différents scénarios. Le choix de la méthode dépendra principalement du nombre de modèles à fusionner et de la nature des compétences que l'on souhaite combiner.
Néanmoins, il est important de garder à l'esprit que le merging n'est pas une solution miracle. Une évaluation rigoureuse du modèle fusionné reste indispensable avant tout déploiement en production, car les performances ne sont pas toujours prévisibles. Pour des besoins très spécifiques ou des niveaux de performance élevés, le fine-tuning traditionnel ou l'entraînement complet restent souvent nécessaires.


