Optimisation bayésienne : pourquoi l'utiliser en MLOps ?
L'optimisation bayésienne est devenue une technique incontournable pour les Data Scientists et Machine Learning Engineers qui cherchent à maximiser les performances de leurs modèles tout en minimisant le temps de calcul. Contrairement aux méthodes traditionnelles comme la recherche par grille ou aléatoire, cette approche intelligente apprend des expérimentations passées pour guider efficacement la recherche des meilleurs hyper-paramètres.

L'optimisation bayésienne est devenue une technique incontournable pour les Data Scientists et Machine Learning Engineers qui cherchent à maximiser les performances de leurs modèles tout en minimisant le temps de calcul. Contrairement aux méthodes traditionnelles comme la recherche par grille ou aléatoire, cette approche intelligente apprend des expérimentations passées pour guider efficacement la recherche des meilleurs hyper-paramètres.
Dans un contexte MLOps où l'automatisation et l'efficacité sont primordiales, comprendre et maîtriser l'optimisation bayésienne représente un avantage considérable. Elle permet non seulement de réduire drastiquement le nombre d'itérations nécessaires, mais aussi d'explorer de manière plus pertinente des espaces de recherche complexes.
Le problème de l'optimisation des hyper-paramètres
Avant de plonger dans l'optimisation bayésienne, rappelons pourquoi l'optimisation des hyper-paramètres est si cruciale. Un modèle de Machine Learning possède deux types de paramètres :
- Les paramètres du modèle, appris automatiquement lors de l'entraînement (poids d'un réseau de neurones, coefficients d'une régression).
- Les hyper-paramètres, définis avant l'entraînement et qui contrôlent le comportement de l'algorithme (taux d'apprentissage, profondeur d'un arbre, nombre de neurones).
Le choix des hyper-paramètres influence directement les performances du modèle. Un mauvais paramétrage peut conduire à du sous-apprentissage (modèle trop simple) ou du sur-apprentissage (modèle trop complexe). Le défi est donc de trouver la combinaison optimale parmi un espace de recherche potentiellement immense.
Les approches classiques présentent des limitations importantes. La recherche par grille (Grid Search) teste exhaustivement toutes les combinaisons possibles, ce qui devient rapidement impraticable lorsque le nombre d'hyper-paramètres augmente. La recherche aléatoire (Random Search) échantillonne aléatoirement l'espace de recherche, offrant de meilleurs résultats en pratique mais sans garantie de convergence vers l'optimum.
À lire aussi : découvrez notre formation MLOps
C'est ici que l'optimisation bayésienne entre en jeu, en proposant une approche séquentielle et informée qui exploite les résultats des évaluations précédentes.
Principes de l'optimisation bayésienne
L'optimisation bayésienne repose sur une idée élégante : construire un modèle probabiliste (appelé modèle de substitution ou surrogate model) de la fonction objectif que l'on cherche à optimiser. Ce modèle capture notre connaissance sur la relation entre les hyper-paramètres et la performance du modèle.
Le processus fonctionne de manière itérative :
- Initialisation : évaluer quelques configurations d'hyper-paramètres choisies aléatoirement.
- Construction du modèle de substitution : ajuster un modèle probabiliste sur les observations collectées.
- Sélection du prochain point : utiliser une fonction d'acquisition pour déterminer la prochaine configuration à évaluer.
- Évaluation : entraîner le modèle avec cette configuration et mesurer sa performance.
- Mise à jour : intégrer cette nouvelle observation et répéter depuis l'étape 2.
La fonction d'acquisition joue un rôle central car elle équilibre l'exploration (tester des zones peu connues de l'espace) et l'exploitation (approfondir les zones prometteuses). Les fonctions les plus utilisées sont l'Expected Improvement (EI), la Probability of Improvement (PI) et l'Upper Confidence Bound (UCB).
SMBO par processus gaussien
La méthode Sequential Model-Based Optimization (SMBO) utilisant des processus gaussiens (GP) est l'approche classique de l'optimisation bayésienne. Un processus gaussien définit une distribution de probabilité sur les fonctions, ce qui permet d'obtenir non seulement une prédiction de la performance pour chaque configuration, mais aussi une mesure d'incertitude.
from skopt import gp_minimize
from skopt.space import Real, Integer
# Définition de l'espace de recherche
space = [
Real(1e-6, 1e-1, name='learning_rate', prior='log-uniform'),
Integer(50, 500, name='n_estimators'),
Integer(3, 15, name='max_depth')
]
# Fonction objectif à minimiser
def objective(params):
lr, n_est, depth = params
model = GradientBoostingClassifier(
learning_rate=lr,
n_estimators=n_est,
max_depth=depth
)
return -cross_val_score(model, X, y, cv=5).mean()
# Optimisation bayésienne
result = gp_minimize(objective, space, n_calls=50, random_state=42)
python
Les processus gaussiens présentent l'avantage d'être bien calibrés en termes d'incertitude, ce qui permet une exploration efficace. Cependant, leur complexité computationnelle en O(n³) les rend moins adaptés lorsque le nombre d'évaluations devient important ou que l'espace de recherche est de grande dimension.
TPE (Tree of Parzen Estimators)
L'approche TPE propose une alternative plus scalable, particulièrement populaire grâce à la librairie Optuna. Au lieu de modéliser directement (la performance en fonction des hyper-paramètres), TPE modélise séparément :
- l(x) : la distribution des hyper-paramètres ayant conduit à de bonnes performances.
- g(x) : la distribution des hyper-paramètres ayant conduit à de mauvaises performances.
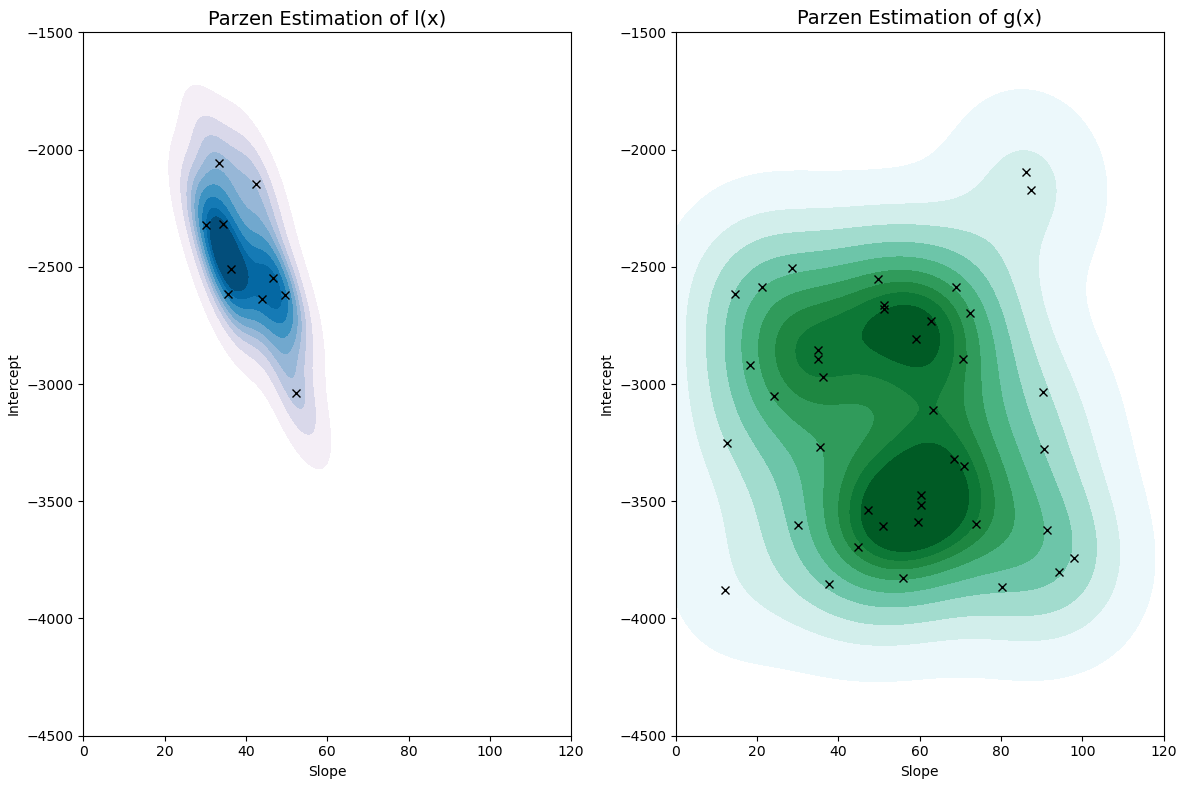
La fonction d'acquisition devient alors le ratio , et l'algorithme cherche les configurations où ce ratio est élevé (forte probabilité d'être bon, faible probabilité d'être mauvais).
import optuna
def objective(trial):
# Suggestion d'hyper-paramètres
lr = trial.suggest_float('learning_rate', 1e-6, 1e-1, log=True)
n_estimators = trial.suggest_int('n_estimators', 50, 500)
max_depth = trial.suggest_int('max_depth', 3, 15)
model = XGBClassifier(
learning_rate=lr,
n_estimators=n_estimators,
max_depth=max_depth,
use_label_encoder=False,
eval_metric='logloss'
)
return cross_val_score(model, X, y, cv=5).mean()
# Création et exécution de l'étude
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
print(f"Meilleurs paramètres : {study.best_params}")
print(f"Meilleur score : {study.best_value}")
python
TPE présente plusieurs avantages pratiques : une meilleure scalabilité pour les espaces de grande dimension, une gestion native des hyper-paramètres conditionnels, et une implémentation efficace dans des librairies comme Optuna ou Hyperopt.
Intégration dans un pipeline MLOps
L'optimisation bayésienne prend tout son sens lorsqu'elle est intégrée dans une démarche MLOps structurée. Plusieurs cas d'usage démontrent son efficacité opérationnelle.
Optimisation automatisée dans les pipelines CI/CD : lors du ré-entraînement périodique des modèles, l'optimisation bayésienne permet de trouver automatiquement les meilleurs hyper-paramètres sans intervention humaine. Couplée à MLflow, chaque essai peut être tracké avec ses paramètres et métriques associés.
import mlflow
import optuna
def objective(trial):
with mlflow.start_run(nested=True):
params = {
'learning_rate': trial.suggest_float('lr', 1e-5, 1e-1, log=True),
'max_depth': trial.suggest_int('max_depth', 3, 12),
'min_child_weight': trial.suggest_int('min_child_weight', 1, 10)
}
mlflow.log_params(params)
model = XGBClassifier(**params)
score = cross_val_score(model, X, y, cv=5).mean()
mlflow.log_metric('cv_score', score)
return score
python
Optimisation sous contraintes de ressources : dans un contexte où le temps de calcul est limité (budget GPU, fenêtre de maintenance), l'optimisation bayésienne maximise l'utilisation des ressources en convergeant plus rapidement vers de bonnes solutions.
Recherche d'architecture neuronale : pour les réseaux de neurones profonds, où chaque évaluation peut prendre plusieurs heures, réduire le nombre d'essais nécessaires représente un gain considérable. L'optimisation bayésienne permet d'explorer efficacement des espaces incluant le nombre de couches, de neurones, les fonctions d'activation et les stratégies de régularisation.
À lire aussi : découvrez notre formation MLOps
Comparaison des approches : voici un récapitulatif des différentes méthodes d'optimisation :
| Méthode | Nombre d'évaluations | Parallélisation | Espaces complexes |
|---|---|---|---|
| Grid Search | Très élevé | Facile | Limitée |
| Random Search | Élevé | Facile | Bonne |
| GP-based BO | Faible | Difficile | Moyenne |
| TPE | Faible | Possible | Excellente |
Conclusion
L'optimisation bayésienne représente une évolution majeure dans la manière d'aborder l'optimisation des hyper-paramètres. En adoptant une approche séquentielle et informée, elle permet de réduire significativement le nombre d'évaluations nécessaires tout en atteignant des performances souvent supérieures aux méthodes traditionnelles.
Dans un contexte MLOps, son intégration avec des outils comme Optuna, MLflow ou Kubeflow facilite l'automatisation des pipelines d'entraînement. Que ce soit via les processus gaussiens pour des problèmes de petite dimension ou TPE pour des espaces plus complexes, ces techniques sont désormais accessibles et prêtes à être déployées en production.
Pour les Data Scientists et Machine Learning Engineers souhaitant améliorer leur efficacité opérationnelle, maîtriser l'optimisation bayésienne est devenu une compétence essentielle. Elle incarne parfaitement la philosophie MLOps : automatiser intelligemment pour se concentrer sur les tâches à forte valeur ajoutée.


