Random Forest : comment ça fonctionne ?
Le Random Forest est un algorithme de Machine Learning très populaire auprès des Data Scientists en raison de sa précision, de sa simplicité et de sa flexibilité. Cet algorithme peut être utilisé pour résoudre les problèmes de régression et de classification. Il est fréquemment adopté dans de nombreux domaines tels que les banques et le commerce en ligne pour prédire des comportements et des résultats futurs.

Le Random Forest (pour forêt aléatoire) est un algorithme de Machine Learning très populaire auprès des Data Scientists en raison de sa précision, de sa simplicité et de sa flexibilité. Cet algorithme peut être utilisé pour résoudre les problèmes de régression et de classification. Il est fréquemment adopté dans de nombreux domaines tels que les banques et le commerce en ligne pour prédire des comportements et des résultats futurs.
Nous allons détailler ensemble le principe de fonctionnement de cet algorithme, déterminer en quoi est-il avantageux par rapport aux autres modèles de Machine Learning, et surtout, dans quelles situations il est préférable de l’utiliser.
Principe de fonctionnement du Random Forest
Le Random Forest (qui signifie forêt aléatoire) est un ensemble d'arbres de décision utilisés pour prédire une quantité ou une probabilité. Passons rapidement en revue les arbres de décision, car ce sont les éléments de base du modèle de forêt aléatoire.
À lire aussi : découvrez notre formation MLOps
Arbre de décision binaire
Un arbre de décision (binaire) est une structure descendante qui possède des nœuds et des branches. À chaque nœud, une condition va nous permettre de nous diriger dans l'arbre, jusqu'à arriver à la fin (nœud terminal). Pour mieux comprendre, prenons cet exemple d'arbre de décision, qui permet de décider d'accepter ou rejeter une demande de prêt bancaire.

Ce genre de situation convient très bien aux arbres de décisions, car il s'agit naturellement d'une succession de conditions à vérifier. Ici, notre arbre répondra à la question : « faut-il prêter au candidat de l'argent ? » en se basant sur les variables explicatives/caractéristiques de la personne.
- Si le candidat ne possède pas un emploi, le modèle va directement décider de ne pas lui prêter.
- Si le candidat possède un emploi, on va passer à la question suivante « possède-t-il une maison ? ». Si la réponse est oui, alors le modèle va décider de lui octroyer un prêt.
- Si le candidat possède un emploi stable mais pas une maison, le modèle a besoin d'informations supplémentaires.
En effet, chaque question représente une caractéristique de notre ensemble de données. Avec ce processus, les données sont organisées sous forme d'arborescence.
Concrètement, à chaque fois que l'on se pose une question, une nouvelle branche est ajoutée. Et en fonction de la réponse (oui ou non), soit le modèle est capable de fournir une prédiction (target, variable cible), soit construire de nouvelles branches, qui vont apporter des informations supplémentaires au modèle.
Mais alors, comment peut-on savoir ce que devrait être le nœud suivant à chaque fois ? Quelle est la prédiction finale ? Et surtout, comment décider à quel moment s'arrêter ? C'est justement l'algorithme CART qui va construire cet arbre à notre place, en utilisant des outils statistiques comme l’entropie et l’indice de Gini.
Random Forest
Par définition, un Random Forest a besoin de trois hyper-paramètres principaux (paramètres fixes), qui doivent être définis avant l’entraînement. Il s’agit notamment de la taille des arbres (le nombre de nœuds maximal), du nombre d’arbres à utiliser et le nombre de caractéristiques échantillonnées (nombre de variables aléatoires choisies à chaque mélange depuis les variables explicatives). À partir de là, le modèle peut être utilisé pour résoudre les problèmes de régression ou de classification.
1 - La première étape consiste à appliquer le principe du bagging, c'est-à-dire créer de nombreux sous-échantillons aléatoires de notre ensemble de données avec possibilité de sélectionner la même valeur plusieurs fois.
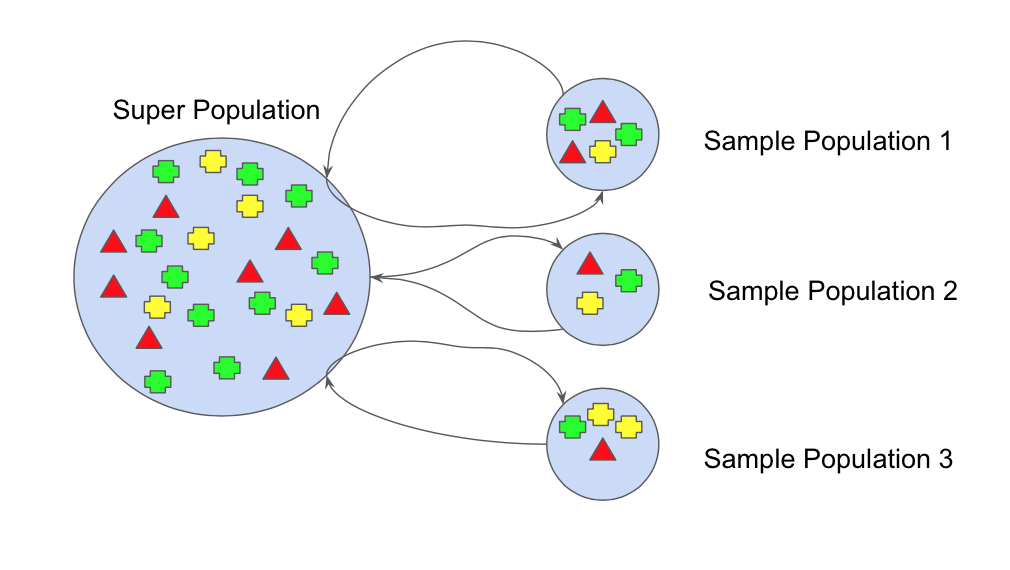
2 - Des arbres de décision individuels sont ensuite construits pour chaque échantillon. Chaque arbre est entraîné sur une portion aléatoire afin de recréer une prédiction. Notons bien que ces modèles-là sont très peu corrélés, et chaque arbre de décision fonctionne individuellement et indépendamment des autres.
Pourquoi ceci est important ? C’est parce que c'est la combinaison de tous ces modèles indépendants qui permettent de réduire la variance du modèle d'ensemble (plus stable, moins chaotique). En d’autres termes, de corriger l’instabilité des arbres de décision ( le fait que des modifications dans l'ensemble d'apprentissage peuvent engendrer des arbres très différents).
3 - Enfin, chaque arbre va prédire un résultat (target). Le résultat avec le plus de votes ( le plus fréquent) devient le résultat final de notre modèle. Dans le cas de régression, on prendra la moyenne des votes de tous les arbres.
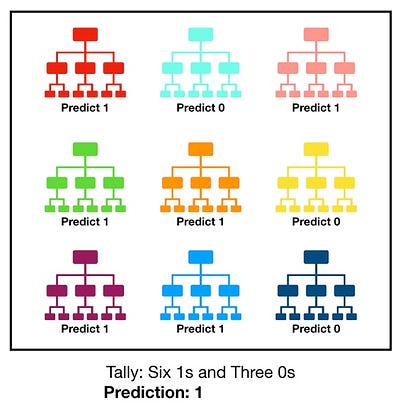
Et voilà comment on obtient un Random Forest : on entraîne plein d'arbres de décisions sur des sous-ensembles mélangés du jeu de données initial, et on calcule la classe la plus fréquente (classification) ou la moyenne (régression) de chaque arbre.
À noter qu'en pratique, on fait également intervenir des méthodes et fonctions évaluations du modèle comme le Out-of-bag (OOB), les scores F1 (pour mesurer les taux de faux-positifs et faux-négatifs) ou l'analyse des décisions avec des méthodes d'interprétabilité.
Quand utiliser le Random Forest ?
Cet algorithme est excellent à utiliser avec des données tabulaires, Il est plus rapide à entraîner que les arbres de décision et d’une grande précision parce qu'il combine les résultats de plusieurs sous-modèles non corrélés.
À lire aussi : découvrez notre formation MLOps
- Lorsque les données sont éparses ou lorsqu'il y a plusieurs valeurs manquantes dans le jeu de données, l’algorithme produira un système invariant qui mènera à des répartitions de nœuds non productives et donc, par la suite, à de mauvais résultats.
- La régression avec cet algorithme n’est pas optimale pour l’extrapolation des données. Contrairement à la régression linéaire qui utilise des observations existantes pour estimer des valeurs au-delà de la plage d’observation, le Random Forest est incapable de prédire des valeurs/situations qui n’existent pas dans le jeu de données. Il est donc plus adapté pour les problèmes de classification.
Cet algorithme résout le problème du sur-apprentissage des jeux de données. C’est un outil très ingénieux pour faire des prédictions précises nécessaires à la prise de décisions stratégiques dans les organisations.
Il existe de nombreux domaines où le Random Forest peut être utilisée, car les données tabulaires se retrouvent partout. On peut notamment citer quelques exemples populaires, comme les calculs de score d'attrition dans les équipes marketing, ou pour faire du scoring utilisateur.
En bref, le Random Forest est l’un des classifieurs les plus efficaces et les plus utilisés de nos jours. C’est un algorithme non seulement précis et fiable mais aussi facile à implémenter, que tout bon Data Scientist doit connaître et maîtriser.
Se former à la Data Science chez Blent
Le Random Forest fait partie des algorithmes les plus populaires et les plus utilisés en Data Science. De nombreuses entreprises utilisent les Random Forest pour construire des modèles prédictifs sur des sujets variés, aussi bien pour les services financiers, de marketing que d'assurance.
La formation Data Scientist de Blent met l'accent sur la maîtrise des algorithmes de Machine Learning, avec notamment tout un module sur les arbres de décision et l'utilisation des Random Forest pour des modèles de pricing immobilier.
Cette formation détaille également d'autres algorithmes populaires, comme le modèle linéaire ou XGBoost. De plus, les méthodes numériques d'optimisation et d'interprétabilité sont abordées, afin d'assurer une livraison d'un modèle pour un environnement de production, qui doit satisfaire des contraintes et exigences techniques.


