TensorFlow : Deep Learning sous Python
Depuis quelques années, les librairies et boîtes à outils informatiques destinées à l’intelligence artificielle se multiplient. En effet, de nombreuses entreprises ont décidé de se doter d’un service d’intelligence artificielle pour traiter leurs données et élaborer des modèles prédictifs.

Depuis quelques années, les librairies et boîtes à outils informatiques destinées à l’intelligence artificielle se multiplient. En effet, de nombreuses entreprises ont décidé de se doter d’un service d’intelligence artificielle pour traiter leurs données et élaborer des modèles prédictifs. Toutefois, ces outils ne sont pas toujours faciles à maîtriser et il est parfois difficile de les manipuler. Cependant, grâce aux différents frameworks de Machine Learning et de Deep Learning, ces tâches se sont beaucoup simplifiés au fil des années.
Parmi ces frameworks, on compte notamment TensorFlow. Ce dernier est devenu en un temps record l’un des frameworks de référence pour le Deep Learning. C'est le premier cadre d’apprentissage profond, open-source, développé et maintenu par Google, ayant pour but d'effectuer diverses tâches axées sur la formation et l’inférence des réseaux de neurones profonds.
Dans cet article, nous allons introduire TensorFlow, son mode de fonctionnement et ses cas d'utilisation. Nous allons également voir comment l'utiliser pour effectuer des calculs simples et des tâches de Deep Learning.
TensorFlow : qu’est-ce que c’est ?
TensorFlow est une bibliothèque open source utilisée par de nombreux développeurs et chercheurs pour créer des modèles de Deep Learning et pour effectuer des tâches d'apprentissage automatique complexes. Il s’agit d’une boîte à outils permettant de résoudre des problèmes mathématiques extrêmement complexes avec aisance et simplicité.
Créé par l’équipe Google Brain en 2011, sous la forme d’un système dédiées aux réseaux de neurones et à l'apprentissage profond. À l'origine, TensorFlow s’appelait DistBelief. Par la suite, le code source de DistBelief a été modifié et cet outil est devenu une bibliothèque basée application. Il a été rendu open-source en 2015.
À lire aussi : découvrez notre formation MLOps
TensorFlow fournit une interface de programmation Python et C++ pour développer des modèles d’apprentissage automatique. Il se distingue de ses concurrents par une communauté très active, une documentation complète et une architecture moderne.
En plus de ça, TensorFlow présente de nombreux avantages, parmi lesquels on peut citer :
- Il est open source. Vous pouvez donc le modifier, l'améliorer ou le redistribuer comme bon vous semble.
- TensorFlow est compatible avec de nombreux langages de programmation, tels que Python, Java, Go, Haskell et R.
- C'est une bibliothèque riche en fonctionnalités qui permet de créer des modèles de machine learning complexes.
- Elle fournit un environnement de développement intégré (EDI) appelé TensorFlow Playground, qui permet aux développeurs de tester et d'expérimenter leurs modèles de machine learning.
- TensorFlow est utilisé par de nombreuses entreprises et organisations, notamment Google, Uber, Airbnb, Twitter, IBM, Qualcomm, Intel, Lenovo, eBay, Dropbox et NASA.
Comment fonctionne TensorFlow ?
TensorFlow permet aux développeurs de créer des graphiques de flux de données ou des structures qui décrivent comment les données se déplacent dans un graphique ou une série de nœuds de traitement. Chaque nœud dans le graphique représente une opération mathématique, et chaque connexion ou bord entre les nœuds est un tableau de données multidimensionnel, ou tenseur.
Un tenseur est un vecteur ou une matrice de n-dimensions qui représente tous les types de données. Toutes les valeurs d’un tenseur possèdent un type de données identique avec une forme connue (ou partiellement connue). La taille des données est équivalente la dimensionnalité de la matrice ou du tableau.

Un exemple typique de tenseur est un batch d’images. Un batch d’images est représenté par un Tensor à 4 dimensions : taille du batch (nombre d’images dans le batch), hauteur, largeur et nombre de canaux de représentation (3 pour une image en couleurs représentée en RGB).
Un tenseur peut provenir des données d’entrée ou du résultat d’un calcul. Dans TensorFlow, toutes les opérations sont effectuées à l’intérieur d’un graphique.
Les graphiques sont des structures qui décrivent la façon dont les données se déplacent dans une série de nœuds de traitement. Lorsqu'on travaille avec TensorFlow, chaque ligne de code qu'on écrit doit passer par un graphique de calcul.
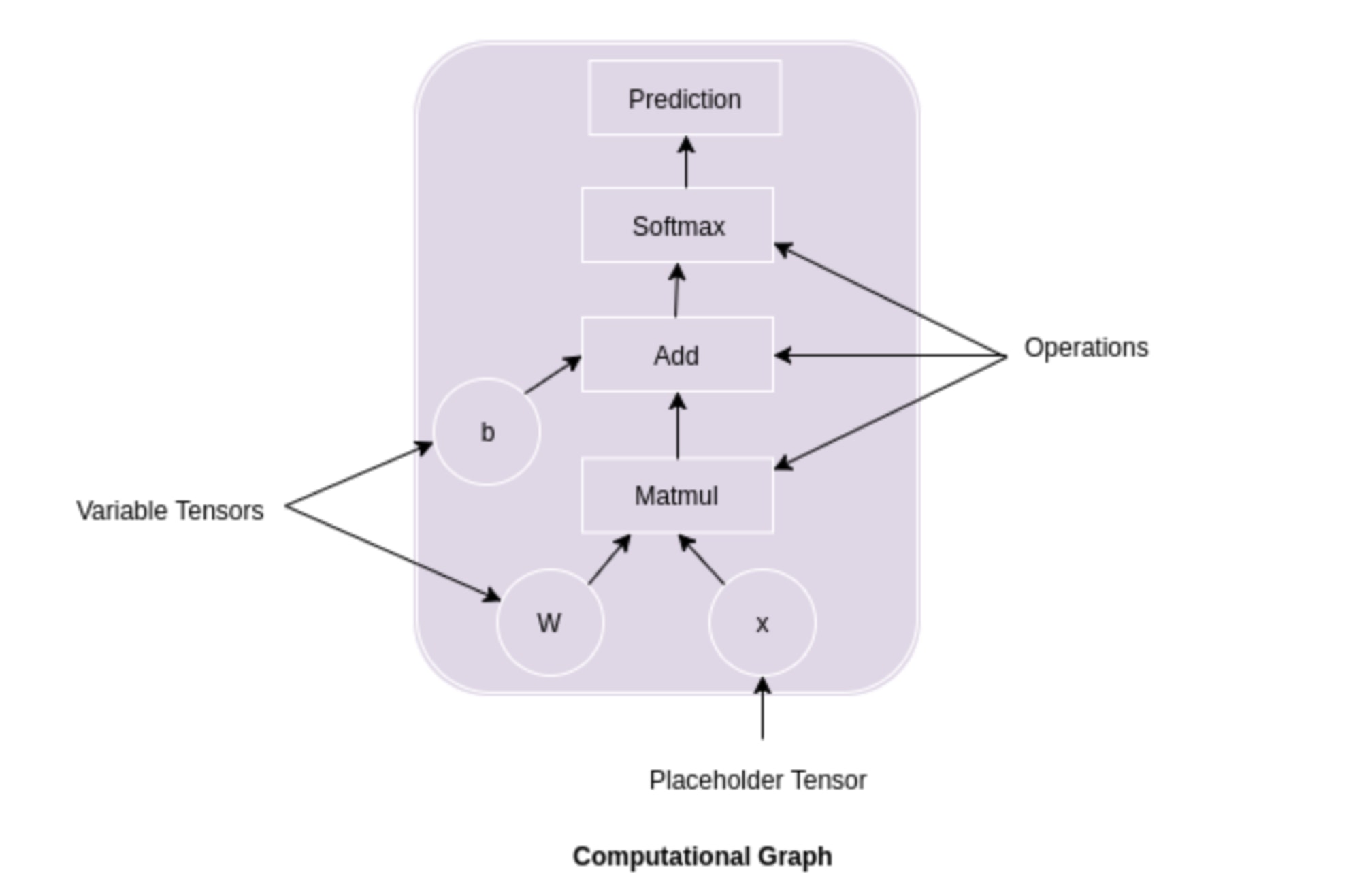
Comme dans la figure ci-dessous, on peut voir que les premiers tenseurs et sont multipliés. Vient ensuite , qui est ajouté à la sortie de la multiplication de et .
Après avoir additionné la sortie de la multiplication de et avec , une fonction Softmax est appliquée et la sortie finale est générée.
Comment utiliser TensorFlow ?
Pour commencer à utiliser TensorFlow, nous allons prendre tout d'abord un exemple simple de multiplication de deux entiers.
Nous multiplierons et ensemble. Tensorflow créera un nœud pour connecter l’opération à ces deux nombres. Lorsque le graphique est déterminé, les moteurs de calcul Tensorflow effectueront la multiplication.
Pour ce faire, nous commencerons par créer deux variables. Sous TensorFlow, on les appelle Placeholders ou espaces réservés. La définition d’un nœud en tant qu’espace réservé garantit que le nœud recevra une valeur ultérieurement ou pendant l’exécution.
import numpy as np
import tensorflow as tf
X = tf.placeholder(tf.float32, name = "X")
Y = tf.placeholder(tf.float32, name = "Y")
python
Ensuite, nous pouvons définir le nœud qui fait l’opération de multiplication. Nous pouvons le faire en utilisant tf.multiply.
Nous passerons les nœuds et au nœud de multiplication. TensorFlow va relier ces nœuds dans le graphique de calcul, donc nous lui demandons de tirer les valeurs de et et de les multiplier pour trouver le résultat.
multiply = tf.multiply(X, Y, name = "multiply")
python
Pour exécuter des opérations dans le graphique, nous devons créer une session. Dans Tensorflow, c’est fait par tf.Session().
with tf.Session() as session:
result = session.run(multiply, feed_dict={X:[1,2,3], Y:[4,5,6]})
print(result)
python
Maintenant que nous avons une session, nous pouvons demander à la session d’exécuter les opérations sur notre graphique de calcul en appelant session. Pour exécuter le calcul, nous devons utiliser run.
[ 4. 10. 18.]
console
Classifier des images avec TensorFlow
Pour commencer à utiliser TensorFlow pour des taches de Deep Learning, nous allons faire un exemple de classification d'images de chiffres manuscrits. Pour ce faire, nous utiliserons le jeu de données très connu MNIST.

Nous allons également utiliser l'API Keras de TensorFlow pour créer un réseau de neurone basique.
Nous allons commencer par importer TensorFlow.
import tensorflow as tf
python
Nous allons ensuite téléchargez les données MNIST à l'aide de la fonction load_data de Keras. Les données sont divisées en données d'apprentissage et de test.
Chaque jeu de données est divisé en images et étiquettes. Chaque image est un tableau de pixels de 28 x 28. Les étiquettes sont des nombres de 0 à 9 correspondant aux dix chiffres manuscrits.
À lire aussi : découvrez notre formation MLOps
Les données doivent être pré-traitées avant de pouvoir être utilisées dans le réseau de neurones. Les valeurs de pixels doivent être normalisées de 0 à 1.
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
python
Nous définissons le modèle de réseau de neurones en utilisant la fonction Sequential. Notre modèle comprend trois couches, une couche Flatten et deux couches denses. La première couche remodèle le tenseur pour le rendre à une seule dimension égale au nombre d’éléments contenus dans le tenseur.
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
python
Le modèle est compilé avec l'optimiseur et la fonction de perte.
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
python
Le modèle est entraîné en utilisant les données d'apprentissage. L'entraînement est effectué sur 10 époques.
La fonction evaluate permet d'évaluer le modèle en cours d'entrainement et afficher les scores de performance tels que la perte et la précision.
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test, verbose=2)
python

Nous remarquons que notre modèle a atteint une précision > 92 % après une seule époque. À la suite de 5 époques, le score final est 98.5 %.
TensorFlow peut être utilisé pour des taches beaucoup plus complexes, telles que le traitement de langage, naturel, la segmentation d'images et la génération d'images.
Les alternatives à TensorFlow
TensorFlow rivalise avec une foule d’autres frameworks d’apprentissage automatique. PyTorch, CNTK et MXNet sont trois outils principaux qui répondent à bon nombre des mêmes besoins.
- PyTorch : PyTorch et TensorFlow sont les deux principaux frameworks de deep learning. PyTorch est un framework de deep learning assez récent, open source et basé sur Python. Il a été développé par Facebook et a été publié en octobre 2016.
TensorFlow est un framework plus mature. Il existe depuis plus longtemps et possède ainsi plus de fonctionnalités. PyTorch est un nouveau framework et est encore en développement actif. Il n’est pas aussi riche en fonctionnalités que TensorFlow, mais il est plus facile à utiliser et dispose d’une API plus intuitive.
- CNTK : est une boîte à outils open-source pour l’apprentissage profond développée par Microsoft. Il est basé sur le concept de graphes acycliques dirigés (DAGs) et est efficace pour manipuler de très grands ensembles de données. Le CNTK prend également en charge un large éventail d’architectures de réseaux neuronaux, y compris les réseaux de neurones convolutionnels (CNNs), les réseaux de neurones récurrents (RNNs) et les réseaux de mémoire à court terme (LSTM).
TensorFlow est une bibliothèque de deep learning multiplateforme et plus facile à utiliser que CNTK. CNTK est plus rapide que TensorFlow.
- MXNet : MXNet est un framework Deel Learning qui est développé et maintenu par Apache Software Foundation. Il s’agit d’un framework open source largement utilisé pour développer et entrainer des modèles d’apprentissage profond.
MXNet est un framework plus flexible que TensorFlow. Il permet aux développeurs de définir des couches et des modèles personnalisés. TensorFlow, d’autre part, est un framework plus rigide.
MXNet est plus rapide et évolutif que TensorFlow. Il peut entraîner les modèles plus rapidement et peut également gérer de grands ensembles de données. MXNet est aussi plus portable que TensorFlow. Il peut être utilisé sur une variété d’appareils tels que les CPUs, GPUs, et FPGAs. TensorFlow, d’autre part, n’est pas aussi portable. Il ne peut être utilisé que sur les CPUs et GPUs.
TensorFlow est un Framework largement privilégié pour les applications Machine Learning et Deep Learning. Il est largement utilisé par de nombreuses grandes entreprises dans le monde entier. Par conséquent, apprendre TensorFlow peut vous aider à démontrer vos compétences dans ce domaine ou acquérir des connaissances supplémentaires.


