Tool Calling des LLM : tout savoir
Le tool calling permet à un LLM de reconnaître quand une requête utilisateur nécessite l'exécution d'une fonction externe, de déterminer quelle fonction appeler et avec quels paramètres, puis de formuler sa réponse en intégrant le résultat obtenu. Cette capacité transforme le modèle de langage d'un simple générateur de texte en un orchestrateur capable d'actions concrètes.

Les modèles de langage ont considérablement évolué ces dernières années, mais une limitation fondamentale persistait : leur incapacité à interagir avec le monde extérieur. Un LLM, aussi puissant soit-il, reste confiné à la génération de texte. Il ne peut pas consulter une base de données, interroger une API météo, effectuer un calcul précis ou envoyer un email. C'est précisément pour combler ce fossé que le tool calling (ou function calling) a été développé.
Le tool calling permet à un LLM de reconnaître quand une requête utilisateur nécessite l'exécution d'une fonction externe, de déterminer quelle fonction appeler et avec quels paramètres, puis de formuler sa réponse en intégrant le résultat obtenu. Cette capacité transforme le modèle de langage d'un simple générateur de texte en un orchestrateur capable d'actions concrètes.
Cette évolution technique constitue également le socle sur lequel reposent les architectures d'agents IA. Comprendre le tool calling est donc essentiel pour quiconque souhaite construire des applications LLM capables d'interagir avec des systèmes externes, qu'il s'agisse d'un simple chatbot enrichi ou d'un système agentique complet. Dans cet article, nous allons explorer le fonctionnement détaillé du tool calling, ses implémentations pratiques, et ce qui le distingue des approches agentiques plus avancées.
Fonctionnement du tool calling
Le tool calling repose sur un mécanisme en plusieurs étapes où le LLM joue un rôle d'interprète et de routeur plutôt que d'exécuteur direct. Le modèle ne peut pas lui-même exécuter du code ou appeler des APIs — il se contente de produire une sortie structurée indiquant quelle fonction devrait être appelée et avec quels arguments.
Le cycle requête-décision-exécution-réponse
Lorsqu'un utilisateur soumet une requête à un système équipé de tool calling, le flux d'exécution suit un cycle bien défini :
- Réception de la requête : l'utilisateur pose une question ou formule une demande ("Quel temps fait-il à Paris ?")
- Analyse par le LLM : le modèle évalue si la requête peut être traitée avec ses connaissances internes ou si elle nécessite un outil externe
- Génération de l'appel de fonction : si un outil est nécessaire, le LLM produit un objet JSON structuré spécifiant la fonction à appeler et ses paramètres
- Exécution côté application : votre code intercepte cette sortie, exécute réellement la fonction, et récupère le résultat
- Intégration du résultat : le résultat est renvoyé au LLM qui formule alors sa réponse finale à l'utilisateur
Utilisateur : "Quel temps fait-il à Paris ?"
LLM (analyse) : Cette question nécessite des données temps réel que je n'ai pas.
Je dois utiliser l'outil get_weather.
LLM (sortie) : {
"function": "get_weather",
"arguments": {"city": "Paris", "country": "France"}
}
Application : Exécute get_weather("Paris", "France") → "15°C, nuageux"
LLM (réponse finale) : "Il fait actuellement 15°C à Paris avec un temps nuageux."
plaintext
Ce mécanisme repose sur une définition préalable des outils disponibles. Avant chaque appel au LLM, vous devez décrire les fonctions que le modèle peut utiliser : leur nom, leur description, leurs paramètres attendus et leurs types. Cette description est injectée dans le contexte du modèle, lui permettant de comprendre quand et comment utiliser chaque outil.
Définition des outils et schémas
La qualité des descriptions d'outils impacte directement la capacité du LLM à les utiliser correctement. Une description vague ou ambiguë conduira à des appels incorrects ou des paramètres mal formatés. La définition d'un outil comprend généralement :
- Le nom de la fonction : identifiant unique et explicite
- La description : explication claire de ce que fait la fonction et quand l'utiliser
- Les paramètres : liste des arguments avec leur type, description, et caractère obligatoire ou optionnel
- Le format de retour (optionnel) : description de ce que la fonction renvoie
| Élément | Rôle | Exemple |
|---|---|---|
| Nom | Identifier la fonction | get_weather |
| Description | Guider le LLM sur l'usage | "Récupère la météo actuelle pour une ville donnée" |
| Paramètres | Structurer les entrées | city: string (required), units: string (optional) |
| Retour | Comprendre la sortie | "Renvoie température, conditions et humidité" |
Les principaux fournisseurs de LLM (OpenAI, Anthropic, Google) proposent des formats légèrement différents pour ces définitions, mais le principe reste identique. OpenAI utilise un schéma JSON Schema, Anthropic a son propre format, et des frameworks comme LangChain offrent une couche d'abstraction qui uniformise ces différences.
# Exemple de définition d'outil pour OpenAI
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Récupère les conditions météorologiques actuelles pour une ville. Utiliser quand l'utilisateur demande la météo, le temps qu'il fait, ou la température d'un lieu.",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "Le nom de la ville"
},
"country": {
"type": "string",
"description": "Le pays (optionnel, pour désambiguïser)"
}
},
"required": ["city"]
}
}
}
]
python
Implémentation pratique du tool calling
Passer de la théorie à l'implémentation nécessite de maîtriser plusieurs aspects techniques : la configuration des outils, la gestion du flux d'exécution, et le traitement des cas particuliers.
Mise en place avec l'API OpenAI
L'implémentation la plus directe utilise l'API OpenAI qui a popularisé le concept de function calling. Le processus implique deux appels au modèle : un premier pour obtenir la décision d'appel de fonction, puis un second pour générer la réponse finale après exécution.
import openai
import json
# Définition de la fonction réelle côté application
def get_weather(city: str, country: str = None) -> dict:
# Ici, appel à une vraie API météo
# Simulation pour l'exemple
return {"temperature": 15, "conditions": "nuageux", "humidity": 65}
# Configuration des outils pour le LLM
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Récupère la météo actuelle pour une ville donnée",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "Nom de la ville"},
"country": {"type": "string", "description": "Pays (optionnel)"}
},
"required": ["city"]
}
}
}
]
# Premier appel : le LLM décide s'il faut utiliser un outil
response = openai.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Quel temps fait-il à Lyon ?"}],
tools=tools,
tool_choice="auto"
)
# Vérification si le LLM veut appeler une fonction
message = response.choices[0].message
if message.tool_calls:
# Extraction des informations d'appel
tool_call = message.tool_calls[0]
function_name = tool_call.function.name
arguments = json.loads(tool_call.function.arguments)
# Exécution de la fonction
if function_name == "get_weather":
result = get_weather(**arguments)
# Second appel avec le résultat
final_response = openai.chat.completions.create(
model="gpt-4",
messages=[
{"role": "user", "content": "Quel temps fait-il à Lyon ?"},
message,
{"role": "tool", "tool_call_id": tool_call.id, "content": json.dumps(result)}
]
)
print(final_response.choices[0].message.content)
python
Appels parallèles et multiples outils
Les LLM modernes supportent l'appel de plusieurs fonctions simultanément lorsque la requête le justifie. Si un utilisateur demande "Compare la météo à Paris et à Londres", le modèle peut générer deux appels à get_weather en parallèle plutôt que de procéder séquentiellement.
Cette capacité est particulièrement utile pour :
- Les comparaisons : récupérer des données de plusieurs sources pour les mettre en perspective
- Les agrégations : collecter des informations complémentaires en une seule passe
- L'optimisation de latence : réduire le temps total en parallélisant les appels indépendants
La gestion de ces appels multiples nécessite une boucle de traitement qui itère sur tous les tool_calls retournés et collecte les résultats avant de les renvoyer au modèle.
Gestion des erreurs et cas limites
Un système de tool calling robuste doit anticiper plusieurs scénarios problématiques :
- Fonction inexistante : le LLM demande une fonction non définie (rare mais possible avec des modèles moins performants)
- Paramètres invalides : les arguments générés ne respectent pas le schéma attendu
- Échec d'exécution : la fonction appelée échoue (API indisponible, données manquantes)
- Boucle infinie : le LLM continue d'appeler des fonctions sans jamais produire de réponse finale
def execute_tool_call(tool_call, available_functions):
"""Exécute un appel de fonction avec gestion d'erreurs."""
function_name = tool_call.function.name
# Vérification que la fonction existe
if function_name not in available_functions:
return {"error": f"Fonction '{function_name}' non disponible"}
try:
# Parsing des arguments
arguments = json.loads(tool_call.function.arguments)
except json.JSONDecodeError:
return {"error": "Arguments mal formatés"}
try:
# Exécution avec timeout
result = available_functions[function_name](**arguments)
return result
except TypeError as e:
return {"error": f"Paramètres invalides: {str(e)}"}
except Exception as e:
return {"error": f"Erreur d'exécution: {str(e)}"}
python
La clé est de toujours renvoyer un résultat au LLM, même en cas d'erreur. Le modèle peut alors adapter sa réponse ("Je n'ai pas pu récupérer la météo, le service est temporairement indisponible") plutôt que de laisser l'utilisateur sans réponse.
À découvrir : notre formation Agentic AI
Tool calling vs approche agentique
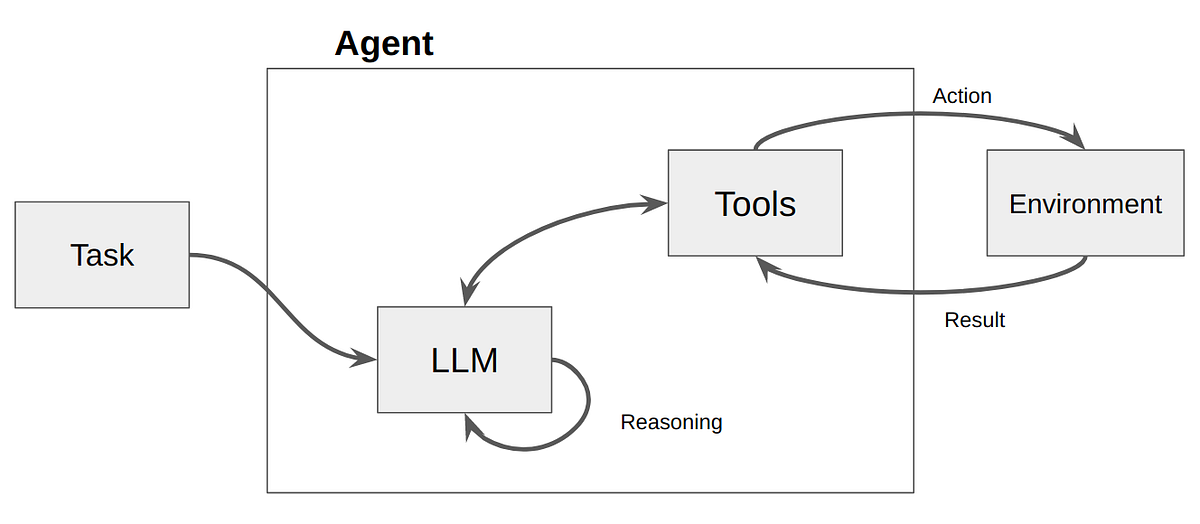
Le tool calling constitue une brique fondamentale des systèmes agentiques, mais il ne suffit pas à lui seul à créer un agent IA. Comprendre cette distinction est essentiel pour choisir l'architecture adaptée à chaque cas d'usage.
Le tool calling : une interaction unique et contrôlée
Dans sa forme pure, le tool calling s'inscrit dans un flux linéaire et prédéterminé. L'utilisateur pose une question, le LLM décide (ou non) d'appeler une fonction, le résultat est intégré, et une réponse est produite. Ce cycle peut être répété mais chaque itération reste indépendante — le système ne "planifie" pas une séquence d'actions pour atteindre un objectif.
Cette approche convient parfaitement aux cas où :
- La requête peut être satisfaite par un ou deux appels de fonction
- Le flux d'exécution est prévisible et ne nécessite pas d'adaptation dynamique
- Le contrôle strict du comportement du système est prioritaire
- Les coûts en tokens et en latence doivent rester maîtrisés
L'approche agentique : autonomie et raisonnement itératif
Un agent IA va bien au-delà du simple tool calling en introduisant une boucle de raisonnement autonome. Le pattern ReAct, par exemple, alterne entre réflexion (Thought), action (Action) et observation (Observation) jusqu'à atteindre l'objectif. L'agent peut reformuler sa stratégie en fonction des résultats intermédiaires, explorer plusieurs pistes, et s'adapter aux échecs.
| Caractéristique | Tool calling simple | Agent IA |
|---|---|---|
| Nombre d'appels de fonction | 1-2 par requête | Variable, potentiellement illimité |
| Planification | Aucune | Décomposition en sous-tâches |
| Adaptation aux échecs | Limitée | Reformulation et alternatives |
| Autonomie | Contrôlée par l'application | Élevée, guidée par l'objectif |
| Prévisibilité | Haute | Variable |
| Coût par requête | Fixe et maîtrisé | Variable selon la complexité |
Concrètement, face à une demande comme "Réserve-moi un restaurant italien pour samedi soir à Paris, pas trop cher, avec de bonnes critiques", un système avec simple tool calling pourrait appeler une fonction de recherche et retourner des résultats. Un agent, lui, pourrait :
- Rechercher des restaurants italiens à Paris
- Filtrer par disponibilité samedi soir
- Vérifier les avis et les prix
- Comparer plusieurs options
- Demander une clarification si plusieurs choix se valent
- Effectuer la réservation une fois le choix validé
Cette capacité d'enchaînement adaptatif est ce qui distingue fondamentalement l'approche agentique du tool calling brut.
Choisir la bonne approche
Le tool calling simple reste le choix optimal pour de nombreux cas d'usage :
- Enrichissement de chatbots : ajouter la capacité de consulter une base de données ou une API sans complexifier l'architecture
- Assistants spécialisés : un assistant météo, un convertisseur de devises, un calculateur
- Intégrations ponctuelles : connecter un LLM à un système existant pour des requêtes ciblées
L'approche agentique devient nécessaire lorsque :
- La tâche nécessite plusieurs étapes dont l'enchaînement dépend des résultats intermédiaires
- L'objectif est complexe ou mal défini, nécessitant une exploration
- Le système doit pouvoir s'adapter et reformuler sa stratégie
- L'autonomie prime sur la prévisibilité
Des frameworks comme LangChain et LangGraph permettent de construire des systèmes agentiques complets en s'appuyant sur le tool calling comme mécanisme d'interaction avec le monde extérieur. Le tool calling est alors un composant de l'agent, pas l'architecture complète.
À lire : découvrez notre formation Agentic AI
Conclusion
Le tool calling représente une avancée majeure dans l'évolution des LLM, leur permettant de passer du statut de générateurs de texte isolés à celui d'orchestrateurs capables d'interagir avec des systèmes externes. En comprenant quand utiliser une fonction, en générant les paramètres appropriés et en intégrant les résultats dans ses réponses, le modèle de langage devient véritablement actionnable.
Le mécanisme repose sur un cycle bien défini où le LLM analyse la requête, décide de l'outil à utiliser, produit un appel structuré que l'application exécute, puis formule sa réponse finale en intégrant le résultat. La qualité des descriptions d'outils et la robustesse de la gestion d'erreurs conditionnent directement l'efficacité du système.
Pour autant, le tool calling seul ne constitue pas un agent IA. La distinction est fondamentale : là où le tool calling offre une interaction contrôlée et prévisible, les architectures agentiques introduisent une boucle de raisonnement autonome permettant de traiter des problèmes complexes nécessitant planification et adaptation. Le tool calling est le mécanisme d'action ; l'agent est l'intelligence qui décide comment et quand agir.
Pour les équipes construisant des applications LLM, maîtriser le tool calling est un prérequis incontournable. C'est la porte d'entrée vers des systèmes plus sophistiqués, qu'il s'agisse d'enrichir un chatbot existant avec des capacités de recherche ou de construire des solutions d'Agentic AI capables d'automatiser des workflows métier complets. La compréhension fine de ce mécanisme permet de faire les bons choix architecturaux et de construire des systèmes à la fois puissants et maîtrisés.


