Word Embedding & NLP : définition, exemples
Pour qu'une machine soit autonome, un principe clé est de pouvoir communiquer via l'un des langages naturels des humains. Le NLP (Natural Language Processing) ou TALN en français (Traitement Automatique du Langage Naturel) est un domaine ancien de l'intelligence artificielle qui existe depuis plus de 50 ans

Pour qu'une machine soit autonome, un principe clé est de pouvoir communiquer via l'un des langages naturels des humains. Le NLP (Natural Language Processing) ou TALN en français (Traitement Automatique du Langage Naturel) est un domaine ancien de l'intelligence artificielle qui existe depuis plus de 50 ans. Il vise à réduire l’écart de communication entre la machine et l'homme tout en la rendant capable de comprendre le texte ou les données vocales et y réagir par leur propre texte ou leur propre parole, un peu près de la même façon que les humains.
Dans cet article, nous allons répondre à des questions très souvent posées : c'est quoi le NLP ? Quels sont les procédés pour nettoyer et transformer le texte ? C'est quoi le Word Embedding et quand et comment l'utiliser ?
C'est quoi le NLP ?
Le NLP combine la modélisation fondée sur des règles du langage humain avec des modèles statistiques du Machine Learning et du Deep Learning. Cette combinaison de technologies permet aux ordinateurs non seulement de traiter le langage humain écrit ou parlé mais aussi de comprendre son sens.
D’importants progrès ont été effectués dans ce domaine au fil des dernières années. En effet, plusieurs applications que nous utilisant au quotidien reposent sur le traitement naturel du langage.
Par exemple on peut citer les services de traduction en temps réel, de correction de texte et de l’aide à la rédaction. Il y on a aussi les chatbots, les détecteurs de spam de messagerie, les moteurs de recherche comme Google et Bing, etc.
À lire aussi : découvrez notre formation MLOps
Un autre cas d’usage de nos jours du NLP concerne les assistants intelligents implémentés dans nos mobiles, ordinateurs et même nos voitures et nos montres telles que Siri de Apple, Cortana de Microsoft et Google Assistant.
Ces derniers interagissent par vois avec les humains, ils répondent aux questions, effectuent des tâches, et racontent des blagues. Cette interaction est rendue possible grâce un réel travail de prétraitement de texte et d'algorithmes de Deep Learning. Elle se déroule généralement de la façon suivante :
- Un humain parle, il donne une consigne à la machine, elle détecte la voie et la convertie en texte. On appelle cela la reconnaissance vocale (Speech To Text).
- La machine transforme les données textuelles sous une forme numérique qu'elle peut comprendre, pour cela elle utilise les techniques du NLP pour analyser le texte et le comprendre. On appelle cela traitement automatique du langage naturel (TALN).
- Les données sont traités en interne à l'aide des modèles Deep Learning spécifiques composées des réseaux de neurones. On peut prédire le sens et même les intentions de l'humain.
- Une fois la machine a compris la consigne, d'autres traitements ont lieu pour y répondre. En premier, les données prétraitées sont comparées à celles contenues dans des bases de données situées dans le Cloud. Ensuite on essaye en fonction du contexte de trouver les mots les plus adéquats pour répondre.
- Une fois la réponse est trouvée, elle est transmise à l’utilisateur sous une forme sonore. On appelle cela la synthèse vocale (Text To Speech)

Pour comprendre et générer du texte, les systèmes alimentés par le NLP doivent être capables de reconnaître les mots, la grammaire et toute une série de nuances linguistiques. Pour les ordinateurs, c’est plus facile à dire qu’à faire parce qu’ils ne peuvent comprendre que des chiffres. Cela est résolut à travers des procédés de traitement de données spécifiques au NLP
Pré-traitement de données pour le NLP
Une des premières idées pour transformer un corpus en une représentation numérique était de construire un dictionnaire : pour chaque mot, nous allions lui attribuer un indice unique.
Cette méthode d'encodage est simple mais elle pose plusieurs problèmes. Même si le nombre de mots d'un langage peut être fini, le nombre de phrases qui peuvent être construites à partir de ces mots est infini, le sens peut complètement changer à cause d'un seul mot. Il faut en théorie, avoir un jeu de données qui dispose de toutes les combinaisons de mots dans une phrase cela implique une grande dimension qui ne permet plus aux modèles de modéliser efficacement le phénomène.
Il y a donc plusieurs étapes de prétraitement de texte qui doivent être prises en compte, spécialement adapté pour le texte mais également pour la langue d'étude.
Nettoyage des données
Dans un premier temps, une étape de nettoyage des données est réalisée. Dans les données que l'on manipule, il y a souvent du brut (de l'information non pertinente) comme des URL, des émojis ou certains ponctuations.
Les majuscules et les stopwords aussi sont à éliminer, ce sont les mots qui n'ajoutent pas beaucoup de sens à la phrase (articles, prépositions, pronoms, conjonctions, etc.) Le nettoyage va permettre de retirer ces éléments afin de limiter la taille du vocabulaire qui sera construit par la suite.
Il existe plusieurs bibliothèques populaires de Python spécialisés dans la préparation des données textuelles, comme spaCy ,Gensim et NLTK (Natural Language Tookit). Ces derniers fournissent toutes les fonctionnalités nécessaires pour nettoyer et normaliser les textes en plusieurs langages.
Normalisation des données
C'est ici notamment que l'on réalise l'opération qui consiste à attribuer la racine d'un mot à chacune de ses formes dérivées.
- La tokenization effectue un découpage du texte en plusieurs fragments, appelés tokens. Généralement, le découpage se fait selon les espaces dans une phrase, et selon les points dans un paragraphe.
- Le stemming (ou racinisation) cherche à conserver uniquement la racine d'un mot. Il est plus direct car il ne s'intéresse qu'au mot étudié : il n'y a donc pas d'évaluation avec les interactions des autres mots. Ainsi, le mot
portéedeviendraportcarportest la racine. - La lemmatization ressemble au stemming mais permet d'isoler la forme canonique : elle est plus complexe mais plus efficace car la lemmatization utilise l'information complète de la phrase pour chercher à comprendre si un mot
portéeest un verbe (elle fut portée), un adjectif (la banderole portée) ou un nom (la portée du signal). C'est le cas notamment lorsqu'il y a un accord en nombre ou en genre que l'on a énoncé plus haut, qui permet d'en déduire le lemme associé.
Encodage des mots
La dernière étape du prétraitement des données est l'encodage des mots, dans cette étape, on arrive finalement à transformer ses mots, maintenant sous forme de tokens, en chiffres. Il existe plusieurs méthodes d'encodage, et chaque méthode à un principe diffèrent.
- Par exemple, la méthode d'encodage Term-Frequency consiste à encoder chaque mot par son nombre d'occurrences dans tous les documents où il est présent. Si par exemple, le mot
porteest présent 2 fois dans le premier document, alors TF=2. Cela forme une matrice d'encodage TF qui possède n lignes (nombre de documents) et m colonnes (taille du vocabulaire). - La méthode Bag of Words où Bow consiste à utiliser l’ensemble du corpus de données pour encoder les phrases. Comme on sait que son corpus de données ne changera jamais, on l’utilisera comme base de référence pour créer des encodages pour les phrases. L’idée est de compter le nombre de fois que chaque mot du corpus apparaît dans chacun des documents. Dans l'exemple qui suit, chaque colonne représente un mot du corpus, et chaque ligne représente une phrase des données.
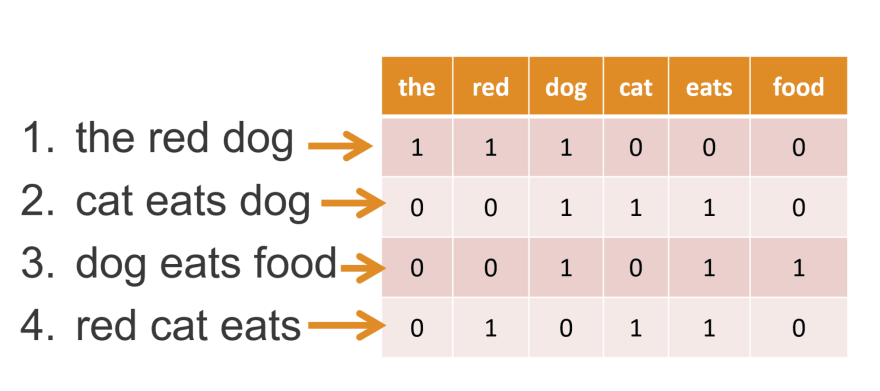
Dans ce cas la phrase numéro 1 est encodée de cette manière ["the", "red", "dog"] -> [1,1,1,0,0,0]
Word Embedding
Le Word Embedding (ou plongement lexical en français) est une méthode d'encodage qui vise à représenter les mots ou les phrases d’un texte par des vecteurs de nombres réels, décrit dans un modèle vectoriel (ou Vector Space Model).
D'une manière plus simple, chaque mot du vocabulaire V étudié sera représenté par un vecteurs de taille m. Le principe du Word Embedding est de projeter chacun de ces mots dans un espace vectoriel d'une taille fixe N (N étant différent de m). C'est-à-dire quelle que soit la taille du vocabulaire, on devra être capable de projeter un mot dans son espace.
Pour cela on aura besoin d'un système pour changer la taille de notre vecteur. Mais alors, comment déterminer ce système ?
À lire aussi : découvrez notre formation MLOps
Un réseau de neurones spécial et populaire intervient ici, c'est ce qu'on appelle un auto-encoder. Un auto-encodeur se compose de 3 couches.
- Une couche d'entrée (l'encodeur).
- Une couche de sortie (le décodeur ) ayant pratiquement la même taille de celle de l'entrée, elle permet la reconstruction des données initiales.
- Une couche dense au milieu (de taille bien inférieure à la couche d'entrée ou la couche de sortie) : c'est cette couche qui nous permet de faire l'encodage.
Dans ce cas de figure, on pourra définir une fonction h responsable de la compression et la projection du vecteur du mot x. h est simplement une multiplication matricielle des poids de la couche d'entrée W par le vecteur one-hot X du mot.

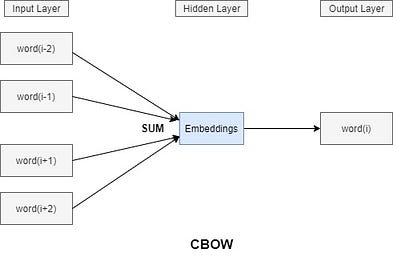
Il existe une famille d'architectures de modèles et d'optimisations qui peuvent être utilisées pour pour déterminer les incorporations d'un groupes de mots à partir de grands ensembles de données. On l'appelle Word2Vec. Deux architectures très populaires appartenant a cette famille sont le Continuous Bag-of-Words et le skip-gram.
Modèle Continuous Bag-of-Words (CBOW)
Avec le modèle CBOW (sac de mots continu), on commence par choisir un mot (le i-eme mot) et par suite on sélectionne un certain nombre de voisins (à gauche et à droite), et on cherche à entraîner le modèle de sorte qu'il soit capable de prédire le mot numéro "i" si on lui fournissait uniquement ses voisins.
En effet, ces mots voisins représentent le contexte, cela signifie que pour prédire n'importe quel mot ,ses voisins sont pris en considération, donc la projection conserve les informations et le contexte du mot.
Par exemple, les mots ordinateur et clavier sont très différents sémantiquement. Mais puisque leur signification est proche, ils seront donc, dans l'espace d'embedding, proches l'un de l'autre.
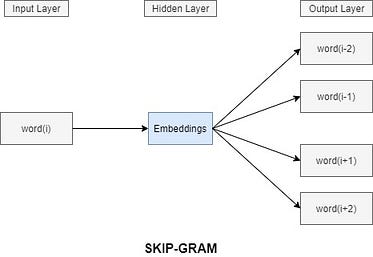
Modèle skip-gram (SG)
Le modèle skip-gram est bien similaire, mais cette fois c'est l'inverse : à partir d'un mot "i", le modèle cherche à déterminer le contexte associé.
Skip-gram ou CBOW ?
Skip-gram fonctionne bien lorsque les données d’entraînement ne sont pas assez et il représente très bien les mots ou les phrases rares. À l'inverse, CBOW est plus rapide à l’entraînement que le skip-gram et il est plus précis pour les mots fréquents.


