
Par Maxime Jumelle
CTO & Co-Founder
Publié le 12 mars 2020
Catégorie Machine Learning
Data Scientist ou Data Engineer ?
Avec l’essor de la Data Science ces dernières années, on entend souvent parler du métier de Data Scientist. Mais le métier de Data Engineer est moins connu du grand public, et dans certains cas mal compris. Pourtant, ces deux métiers sont complémentaires et l’un ne va pas sans l’autre. Mais quelle est la frontière entre ces deux métiers ? Et d’abord, que font-ils exactement ?
Le cycle de vie d’un projet Data Science
Pour bien comprendre ces deux métiers, observons comment un projet Data Science voit le jour. Prenons un exemple : le Vélib’ Métropole, ces fameux vélos en libre-service (VLS) de la ville de Paris dont la gestion de la flotte est assez contestée. La ville de Paris souhaite optimiser l’alimentation en vélos des stations en fonction de plusieurs paramètres : heure de la journée, localisation de la station, météo, et autres informations. Pour cela, elle souhaite avoir un service Web qui permet de prédire en temps réel le nombre de vélos qui seront utilisés dans l’heure suivante, pour chaque station.

Comment allons-nous réaliser ce projet Data Science dans son ensemble ?
Découpons ce projet en plusieurs étapes, étudions point par point les phases de ce projet et notons le rôle du Data Scientist et du Data Engineer dans chacune des phases.
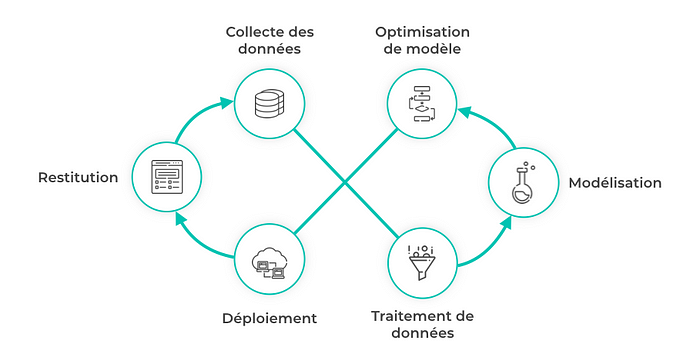
Collecte des données
La première étape indispensable est la collecte des données, qui permet de récupérer les données disponibles dans des bases plus ou moins importantes, mais qui doit surtout être rigoureusement effectuée en fonction du sujet d’étude : Ici, nous allons récupérer tous les trajets effectués sur une année complète.
C’est le Data Engineer qui intervient en premier. C’est lui qui va requêter, extraire et rassembler les sources de données.

Chaque trajet est identifié par un identifiant unique (trip_id), et toutes les informations de temps (start_time, end_time) et de localisation (from_station, to_station) permettront de connaître l’affluence à chaque station et à chaque heure ...
... Mais c’est presque 80,000 trajets effectués par jour ! La quantité de données est immense (plusieurs dizaines de Go), et la seule solution est de passer par du calcul parallèle, bien connu des Data Engineers. Cette méthode de calcul permet de s’affranchir de la limite mémoire des ordinateurs en lançant et en automatisant des calculs distribués sur plusieurs serveurs dans le Cloud : peut-être vous en avez déjà entendu parler, mais MapReduce est une méthode très efficace. Heureusement pour nous, il existe plusieurs frameworks qui facilite la mise en place de calcul parallèle, dont Hadoop et Spark en sont les plus populaires.
Tout ceci nécessite donc la mise en place d’une architecture Big Data : le Data Engineer récolte toutes les sources de données dans un Data Lake, met en place des pipelines de données qui permettront d’acheminer facilement la donnée et de s’assurer de son format normalisé : terminé les données perdues dans tous les recoins, la centralisation dans un Data Warehouse est la clé de voûte du toute entreprise data-driven.
Traitement des données
Le Data Scientist ne peut pas travailler avec autant de données : le Data Engineer doit d’abord agréger les données en fonction de ce que souhaitera faire le Data Scientist.
Le Data Engineer apporte sa connaissance des données qu’il a précédemment récolté, puis c’est le Data Scientist qui va effectuer l’étude de ces dernières.
Pour les vélos, le Data Engineer aura regroupé, pour chaque station, et par jour, l’affluence en fonction de l’heure. Le Data Scientist pourra ensuite récupérer un jeu de données beaucoup moins important, mais plus facilement maniable. Une fois les données récupérées, commence pour le Data Scientist une étape consommatrice en temps et très importante pour la suite du projet, à savoir la préparation des donnés. Cette étape a deux objectifs :
Inspecter les valeurs manquantes/aberrantes et nettoyer les colonnes.
Obtenir de la connaissance sur les données pour la suite du projet grâce notamment à la Data Visualisation et les statistiques descriptives. Cette étape permet de commencer à envisager les premiers modèles de Machine Learning.
Modélisation
La modélisation consiste à créer et calibrer le modèle prédictif en fonction des données, c’est-à-dire l’algorithme qui va être capable de prédire le nombre de vélos qui seront utilisés l’heure suivante dans chaque station.
C’est le coeur de métier du Data Scientist, qui maîtrise une palette d’algorithmes qu’il peut utiliser en fonction des problématiques de chaque projet.
C’est à ce moment-là que les compétences en statistiques et en algorithmique sont essentielles pour cette étape.
Mais il faut pas oublier les trois étapes essentielles qui surviennent pendant la modélisation.
L’optimisation des hyper-paramètres permet de gagner en performances. La recherche par grille ou une méthode d’optimisation bayésienne permettent déjà d’obtenir des gains de performance en peu de temps.
La validation de modèles pour s’assurer de la capacité du modèle à généraliser sur de nouvelles observations. Les techniques de Bootstrapping et de ré-échantillonnage sont les principaux outils du Data Scientist.
L’interprétation qui nous permet d’étudier le comportement du modèle. Aujourd’hui, de puissants outils comme les valeurs de Shapley, LIME ou encore DeepLIFT pour les réseaux de neurones s’efforcent à comprendre au maximum comment le modèle agit face à une donnée.
Optimisation
Puisque les données elles aussi évoluent, le modèle doit suivre la tendance : le comportement des usagers peut varier d’une année sur l’autre. Il est donc primordial d’optimiser le modèle avec de nouvelles données ou pour obtenir de meilleures performances.
Le Data Scientist connaît bien cette phase, mais il doit veiller à ne pas consacrer plus de temps que nécessaire pour gagner en performances.
Aujourd’hui, certains modèles peuvent doubler leurs performances avec une optimisation ingénieuse et des calculs optimisés.
Déploiement
Pour terminer, ce service ne sera pas hébergé en local sur l’ordinateur, mais sera sur un serveur et disponible pour la ville de Paris. Le déploiement est une des dernières étapes pour la mise en production du projet.
Le Data Scientist rend un projet propre et documenté, et le Data Engineer s’assure que les pipelines de données (la façon dont les données transitent) sont correctement établis. En interaction avec le DevOps (responsable des services déployés dans le Cloud), il aide ce dernier afin de préparer au mieux et dans les meilleurs conditions le déploiement du projet.
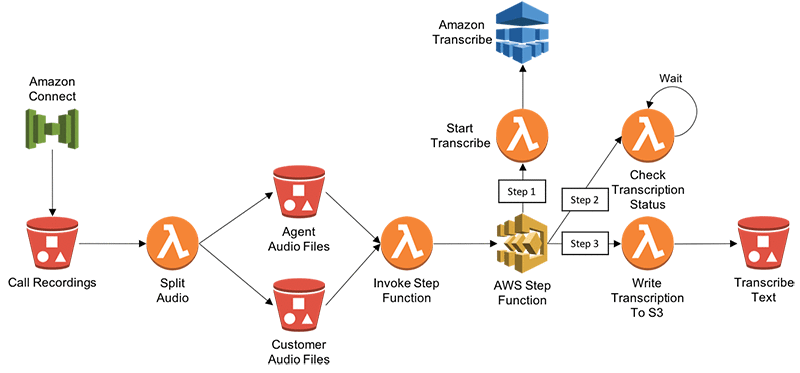
Puisque nous rencontrons plus de compétences IT dans cette partie, le Data Engineer se doit d’avoir quelques notions en Cloud Computing. Une fois déployé, l’algorithme est disponible et peut être utilisé par l’intermédiaire d’une API (interface d’utilisation entre l’algorithme et les applications web/mobile).
Restitution
Dans certains cas, un dashboard permet de visualiser plus facilement ses données pour prendre des décisions plus aisément : la restitution, truffée de Data Visualization et d’UX, est la dernière ligne droite du projet.
Le Data Engineer assiste les développeurs en fournissant une documentation technique sur les données. Même s’il n’intervient que rarement à cette partie, plus le Data Engineer aura produit une documentation claire, plus les temps de développement seront courts.
Et voilà ! Nous pourrons voir, en temps réel, combien de vélos seront utilisés pour chaque station en Île-de-France, et tout ça grâce à la Data Science.
Commence ta carrière
Blent propose le premier bootcamp 100% en ligne où vous pouvez vous former à la Data Science et au Data Engineering sur des projets des entreprises. Cumulant des classes virtuelles avec nos professeurs et travaux en e-learning pendant 3 mois à temps partiel, tu seras opérationnel à la fin de la formation pour donner un boost à ta carrière.
Blent Family !
Vous souhaitez vous former au MLOps ?
Articles similaires

20 sept. 2022
Hugging Face est une startup française qui s'est fait connaître grâce à l'infrastructure NLP qu'ils ont développée. Aujourd'hui, elle est sur le point de révolutionner le domaine du Machine Learning et traitement automatique du langage naturel. Dans cet article, nous allons présenter Hugging Face et détailler les taches de base que cette librairie permet de réaliser. Nous allons également énumérer ses avantages et ses alternatifs.
Équipe Blent
Data Scientist
Lire l'article

12 juil. 2022
spaCy est une bibliothèque open-source pour le traitement avancé du langage naturel. Elle est conçue spécifiquement pour une utilisation en production et permet de construire des applications qui traitent et comprennent de grands volumes de texte.
Équipe Blent
Data Scientist
Lire l'article

4 juil. 2022
Un auto-encodeur est une structure de réseaux neuronaux profonds qui s'entraîne pour réduire la quantité de données nécessaires pour représenter une donnée d'entrée. Ils sont couramment utilisés en apprentissage automatique pour effectuer des tâches de compression de données, d'apprentissage de représentations et de détection de motifs.
Équipe Blent
Data Scientist
Lire l'article
60 rue François 1er
75008 Paris
Blent est une plateforme 100% en ligne pour se former aux métiers Tech & Data.
Organisme de formation n°11755985075.

Data Engineering
IA Générative
MLOps
Cloud & DevOps
À propos
Gestion des cookies
© 2024 Blent.ai | Tous droits réservés