
Par Équipe Blent
Data Scientist
Publié le 8 juin 2022
Catégorie Machine Learning
YOLO : détection sur les images avec TensorFlow
Au cours des dernières années, les modèles Deep Learning ont gagné en renommée pour leur capacité à traiter l’information visuelle et ils sont devenus un élément clé de nombreuses applications de vision par ordinateur. Parmi les principaux problèmes que ces modèles peuvent résoudre est la détection et la localisation des objets dans les images. La détection d’objets est utilisée dans de divers domaines, y compris la conduite autonome, la vidéosurveillance et les soins de santé.
Parmi ces modèles, YOLO est l'un des plus connus et plus utilisés. Il permet de réaliser la détection d'objets en une seule étape et d'atteindre un très bon niveau de précision et une vitesse de détection élevée. Il est particulièrement bien adapté pour les applications en temps réel.
Dans cet article nous allons détailler la notion de la détection automatique d'objets dans des images, nous allons également introduire le modèle de Deep Learning YOLO, son fonctionnement et comment l'utiliser pour la détection d'images,
Détection d'objets
La détection d’objets est un phénomène de vision par ordinateur qui implique la détection de divers objets dans des images ou des vidéos numériques. Elle consiste à reconnaître des objets dans un environnement et à les classer par catégorie. Les objets peuvent être de toutes formes et de toutes tailles. La détection d’objets peut être utilisée dans diverses applications, telles que la sécurité, la robotique, la vision par ordinateur et la reconnaissance de formes.
Ce phénomène cherche à répondre à deux questions fondamentales :
- Qu’est-ce que l’objet ? Cette question vise à identifier l’objet dans une image spécifique.
- Où est-il ? Cette question vise à trouver l’emplacement exact de l’objet dans l’image.
L’image n’est pas contrainte d’avoir un seul objet, mais peut contenir plusieurs objets. La tâche est de classer et de localiser tous les objets dans l’image. La localisation est faite en utilisant le concept de boîte de délimitation qui peut être identifiée par certains paramètres numériques tout en respectant la limite de l’image.
À lire aussi : découvrez notre formation MLOps
La détection d’objets peut être faite à l'aide de diverses approches telles que :
- SSD (Single Shot Detector)
- R-CNN (Regional Convolutional Neural Network)
- Fast R-CNN
- Faster R-CNN
- Mask R-CNN
Bien que ces approches aient résolu les problèmes de limitation des données et de modélisation dans la détection d’objets, elles ne sont pas en mesure de détecter des objets dans un seul cycle d’algorithme. L’algorithme YOLO a gagné en popularité en raison de ses performances supérieures par rapport aux techniques de détection d’objets susmentionnées.
YOLO, définition et architecture
Les frameworks de détection antérieurs ont examiné différentes parties de l’image plusieurs fois à différentes échelles et ont réorienté la technique de classification des images pour détecter les objets. Cette approche est lente et inefficace.
YOLO adopte une approche totalement différente. Il ne regarde l’image entière qu’une seule fois et passe par le réseau une fois et détecte les objets. D’où le nom. Il est très rapide. C’est la raison pour laquelle il est devenu si populaire.
Principe de fonctionnement
L'algorithme divise l'image d'entrée en une grille de taille S x S. Pour chaque cellule de la grille, il prédit B cadres de délimitation(B=2 signifie qu'une cellule de la grille peut contenir au plus 2 objets), où chaque cadre de délimitation se compose de 4 coordonnées, d'un score de confiance pour la prédiction et de probabilités associé aux différentes classes C choisies comme label.
Ainsi, toutes ces prédictions sont codées sous la forme d'un vecteur de taille \(S×S×(B×5+C)\).
Regardons dans l'exemple suivant où l'on considère une grille de taille 3x3, il qu'un seul objet par cellule (donc B=1) et l'on souhaite détecter 3 classes différentes (c1,c2 et c3).
Ici, la cellule violette ne nous intéresse pas, car elle ne possède aucun objet. La cellule verte et jaune contiennent le centre de deux voitures, ainsi elles auront un vecteur label associé comme ci-dessous avec :

- pc = booléen qui indique si la cellule possède un objet
- (bx,by) = les coordonnées du centre de l'objet
- (bh,bw) = la longueur et la largeur de la bounding box (en rouge)
Les cadres rouges représentent les labels. Notre modèle est donc entraîné avec ces labels qui sont en fait simplement les rectangles qui encadrent le plus fidèlement les objets. Les cellules jaunes et vertes appartiennent à la grille 3x3.
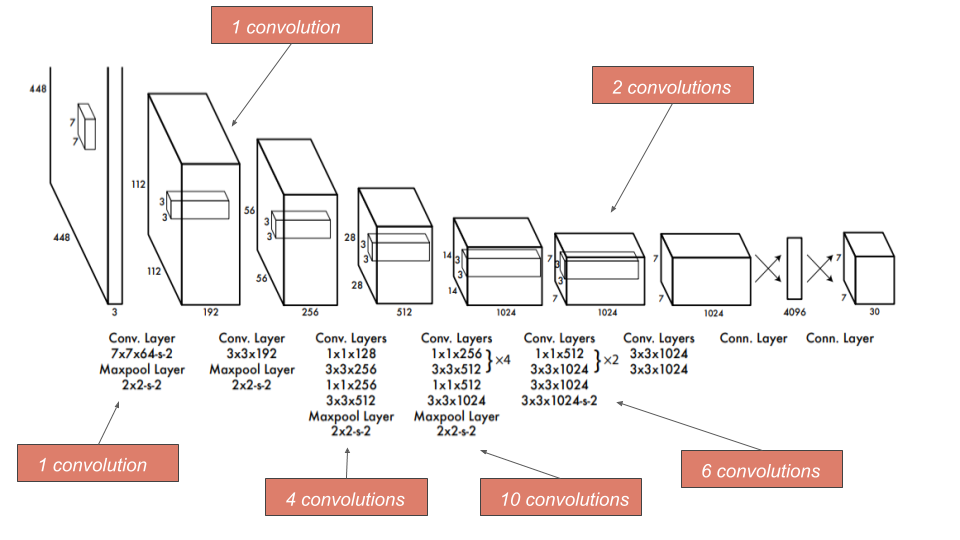
Architecture
L'architecture du modèle se compose de 24 couches convolutives pour extraire les features suivies de 2 couches denses entièrement connectées pour réaliser la détection d'objets.
Unicité des encadrements prédits
YOLO peut effectuer des détections de doublons pour le même objet. YOLO utilise IOU pour fournir une boîte de sortie qui entoure parfaitement les objets.
Chaque cellule de la grille est chargée de prévoir les cases limitatives et leurs scores de confiance. L'IOU est égale au rapport entre l'intersection de la zone prédite et réelle avec l'union de ces deux zones L’IOU est égale à 1 si la boîte de délimitation prévue est la même que la boîte réelle. Ce mécanisme élimine les boîtes limitantes qui ne sont pas égales à la boîte réelle.
L’image suivante présente un exemple simple du fonctionnement de l’IOU :

Nous entraînons un modèle à produire une boîte qui s’adapte parfaitement autour d’un objet. Par exemple, dans l’image ci-dessous, nous avons une boîte jaune et une boîte rouge. La boîte rouge représente la bonne boîte et la boîte jaune représente la prédiction de notre modèle. Le but de ce modèle serait de continuer à améliorer sa prédiction, jusqu’à ce que la boîte rouge et la boîte jaune se chevauchent parfaitement, c’est-à-dire que l’IOU entre les deux boîtes devient égale à 1.
Détection d'objets avec YOLO
Dans cet exemple, nous allons essayer de détecter tous les objets dans une image en utilisant le modèle pré-entraîné Yolo3 du framework OpenCV.
Nous allons commencer par importer les modules nécessaires.
import numpy as np import cv2 from google.colab.patches import cv2_imshow # colab do not support cv2.imshow()
Définissons tout d'abord les paramètres que nous allons utiliser pour utiliser le modèle YOLO. Nous aurons besoin du chemin vers les noms des classes du jeu de données COCO COCO_LABELS_FILE pour la prédiction des classes qui nous intéressent. Il faudra également utiliser les poids du modèle YOLO pré-entrainé YOLO_WEIGHTS_FILE. Le chemin vers une image de test est stocké dans IMAGE_FILE.
ROOT_COLAB = '/content/' COCO_LABELS_FILE = ROOT_COLAB + 'coco.names' YOLO_CONFIG_FILE = ROOT_COLAB + 'yolov3.cfg' YOLO_WEIGHTS_FILE = ROOT_COLAB + 'yolov3.weights' IMAGE_FILE = 'image.png' IMAGE = cv2.imread(ROOT_COLAB + IMAGE_FILE) CONFIDENCE_MIN = 0.5
Cette fonction permet de redimensionner une image en gardant le rapport de format.
On affiche ensuite l'image de test en utilisant la fonction imshow de OpenCV.
def ResizeWithAspectRatio(image, width=None, height=None, inter=cv2.INTER_AREA): dim = None image = image.copy() (h, w) = image.shape[:2] if width is None and height is None: return image if width is None: r = height / float(h) dim = (int(w * r), height) else: r = width / float(w) dim = (width, int(h * r)) return cv2.resize(image, dim, interpolation=inter) cv2_imshow(ResizeWithAspectRatio(IMAGE, width=700))

Nous lisons la liste des étiquettes (coco) YOLO. Cela serait en mesure de détecter les objets dans l’image
with open(COCO_LABELS_FILE, 'rt') as f: labels = f.read().rstrip('\n').split('\n')
Nous définissons aléatoirement pour chaque étiquette une couleur spécifique pour les cadres délimitant les objets de la photo.
np.random.seed(45) BOX_COLORS = np.random.randint(0, 255, size=(len(labels), 3), dtype="uint8")
Nous important le modèle en utilisant le fichier config et les poids du modèle.
yolo = cv2.dnn.readNetFromDarknet(YOLO_CONFIG_FILE, YOLO_WEIGHTS_FILE)
Nous allons extraire la couche de sortie uniquement, celle-là, nous permettra d'effectuer la détection.
yololayers = [yolo.getLayerNames()[i[0] - 1] for i in yolo.getUnconnectedOutLayers()] yololayers
Préparer l’image (blob) pour l’envoyer au réseau YOLO.
blobimage = cv2.dnn.blobFromImage(IMAGE, 1 / 255.0, (416, 416), swapRB=True, crop=False) yolo.setInput(blobimage)
Cette fonction permet de d'effectuer la détection et de stocker les scores de précisions, les cordonnées des boites de délimitation et labels des objets dans des listes. Nous utiliserons ces données la juste après pour afficher les résultats.
boxes_detected = [] confidences_scores = [] labels_detected = [] # boucler sur chacune des sorties de couche for output in layerOutputs: # boucler sur chacune des détections for detection in output: # extraire l’ID de classe et la confiance (c.-à-d. la probabilité) de la détection de l’objet courant scores = detection[5:] classID = np.argmax(scores) confidence = scores[classID] # Ne prendre que les prédictions avec plus de confiance que CONFIDENCE_MIN if confidence > CONFIDENCE_MIN: # zone de délimitation box = detection[0:4] * np.array([W, H, W, H]) (centerX, centerY, width, height) = box.astype("int") # Utiliser les coordonnées centrales (x, y) pour obtenir les coins haut et gauche de la zone de délimitation. x = int(centerX - (width / 2)) y = int(centerY - (height / 2)) # mettre à jour notre liste de résultats (detection) boxes_detected.append([x, y, int(width), int(height)]) confidences_scores.append(float(confidence)) labels_detected.append(classID)
Cette fonction permet de dessiner les cadres délimitant chaque objet sur l'image avec le score de précision associé.
label_names = [labels[i] for i in labels_detected] nb_results = len(boxes_detected) (H, W) = IMAGE.shape[:2] image = IMAGE.copy() if nb_results > 0: for i in range(nb_results): # extraire les coordonnées de la zone de délimitation (x, y) = (boxes_detected[i][0], boxes_detected[i][1]) (w, h) = (boxes_detected[i][2], boxes_detected[i][3]) # tracer un rectangle de délimitation et une étiquette sur l’image color = [int(c) for c in BOX_COLORS[labels_detected[i]]] cv2.rectangle(image, (x, y), (x + w, y + h), color, 2) score = str(round(float(confidences_scores[i]) * 100, 1)) + "%" text = "{}: {}".format(labels[labels_detected[i]], score) cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2) # Afficher l'image avec les boites cv2_imshow(ResizeWithAspectRatio(image, width=700))

Les limitations du YOLO et ses variantes
Bien que YOLO semble être le meilleur algorithme à utiliser si vous avez un problème de détection d’objet à résoudre, il est livré avec plusieurs limitations.
YOLO a du mal à détecter et à séparer les petits objets dans les images qui apparaissent en groupes, car chaque grille est contrainte de détecter un seul objet. Les petits objets qui viennent naturellement en groupes, comme une ligne de fourmis, sont donc difficiles à détecter et à localiser pour YOLO.
À lire aussi : découvrez notre formation MLOps
YOLO est également caractérisé par une précision inférieure par rapport à des algorithmes de détection d’objets beaucoup plus lents comme Fast RCNN.
Au fils des années, plusieurs variantes sont apparues pour remédier à ces problèmes du YOLO, parmi ces derniers, on peut citer :
- YOLOv2 : a été proposé pour résoudre le problème principle du YOLO : la détection de petits objets en groupes et la précision de localisation. YOLOv2 augmente la précision moyenne du réseau en introduisant la normalisation par lots.
- YOLO9000 : En utilisant une architecture de réseau similaire à YOLOv2, YOLO9000 a été proposé comme algorithme pour détecter plus de classes que COCO comme un ensemble de données de détection d’objet aurait pu rendre possible. Entraîné avec le jeu de données ImageNet qui a 22.000 classes, YOLO9000 est capable de détecter plus que 9000 classes.
Il existe d'autres variantes du YOLO adaptées à de différentes situations, certains sont très précis, d'autre sont très rapides telles que YOLOv3, YOLOv4, YOLOv5 et YOLACT.
YOLO est un modèle Deep Learning basé sur des CNNs conçu pour une détection rapide et précise en temps réels des objets dans des images. Jusqu’à présent, il a surpassé toutes les méthodes précédentes, surtout dans le domaine de la conduite autonome et de la surveillance.
Vous souhaitez vous former au MLOps ?
Articles similaires

20 sept. 2022
Hugging Face est une startup française qui s'est fait connaître grâce à l'infrastructure NLP qu'ils ont développée. Aujourd'hui, elle est sur le point de révolutionner le domaine du Machine Learning et traitement automatique du langage naturel. Dans cet article, nous allons présenter Hugging Face et détailler les taches de base que cette librairie permet de réaliser. Nous allons également énumérer ses avantages et ses alternatifs.
Équipe Blent
Data Scientist
Lire l'article

12 juil. 2022
spaCy est une bibliothèque open-source pour le traitement avancé du langage naturel. Elle est conçue spécifiquement pour une utilisation en production et permet de construire des applications qui traitent et comprennent de grands volumes de texte.
Équipe Blent
Data Scientist
Lire l'article

4 juil. 2022
Un auto-encodeur est une structure de réseaux neuronaux profonds qui s'entraîne pour réduire la quantité de données nécessaires pour représenter une donnée d'entrée. Ils sont couramment utilisés en apprentissage automatique pour effectuer des tâches de compression de données, d'apprentissage de représentations et de détection de motifs.
Équipe Blent
Data Scientist
Lire l'article
60 rue François 1er
75008 Paris
Blent est une plateforme 100% en ligne pour se former aux métiers Tech & Data.
Organisme de formation n°11755985075.

Data Engineering
IA Générative
MLOps
Cloud & DevOps
À propos
Gestion des cookies
© 2025 Blent.ai | Tous droits réservés