GAN et Deep Learning : créer des données de toute pièces
Les GANs sont des modèles génératifs : ils créent de nouvelles instances de données qui ressemblent à vos données de formation. Par exemple, ils peuvent créer des images qui ressemblent à des photographies de visages humains, même si les visages n’appartiennent à aucune personne réelle.

Au cours des dernières années, les réseaux antagonistes génératifs (GANs) ont suscité beaucoup d’intérêt dans les milieux de la recherche et de l’ingénierie. Ils ont émergé comme une nouvelle et puissante méthode pour apprendre à générer des données réalistes. On s'attend à ce que les GANs se développent rapidement et qu'ils jouent un rôle important dans toute une série de domaines, y compris la vision par ordinateur.
Les GANs ont récemment été utilisés comme une méthode permettant de générer des images de haute qualité à partir de données de faible qualité. Ils sont également capables de générer des images à partir de simples données textuelles, comme des phrases décrivant des images. On pourrait dire qu’ils sont la tendance de nos jours.
Dans cet article, nous allons introduire les GANs, leur fonctionnement, leurs types et leurs cas d’usage.
Qu'est-ce qu'un GAN ?
Les GANs sont des modèles génératifs : ils créent de nouvelles instances de données qui ressemblent à vos données de formation. Par exemple, ils peuvent créer des images qui ressemblent à des photographies de visages humains, même si les visages n’appartiennent à aucune personne réelle. Ces images ont été créées par un GAN :

En 2014, lorsque des chercheurs en IA, dont Ian Goodfellow, ont introduit l’utilisation des GANs, cela a attiré de nombreuses startups et entreprises en IA. Il rattrape regalement les praticiens, les codeurs et les chercheurs dans tous les secteurs, à mesure qu’il mûrit et croît avec le temps.
Le potentiel des GANs pour le bien et le mal est énorme, car ils peuvent apprendre à imiter toute distribution de données. C’est-à-dire qu'ils peuvent apprendre à créer des objets extrêmement semblables à leurs versions réels dans n’importe quel domaine : images, musique, parole, prose. Ils peuvent également être utilisés pour générer du contenu médiatique faux. Par exemple, produire de fausses photos et vidéos, éventuellement, incriminantes ou ce qu'on appelle des Deepfakes.
À lire aussi : découvrez notre formation MLOps
Comment fonctionnent les GANs ?
Les GANs sont des réseaux de génération d'image via un process adversarial entre deux modèles distincts, un discriminateur et un générateur , qui sont entraînés simultanément.
Le modèle générateur a pour but de capturer la distribution des données d'entrée et générer de nouveaux échantillons appartenant au même domaine, alors que le discriminateur a pour but d'estimer les probabilités que des images soient issues de l'ensemble d'entraînement ou bien qu'elles aient été générées par le générateur . La performance du modèle de discrimination est utilisée pour mettre à jour les poids du modèle lui-même et du modèle générateur. Cela signifie que le générateur ne voit jamais réellement des exemples du domaine et est adapté en fonction de la performance de la discrimination.
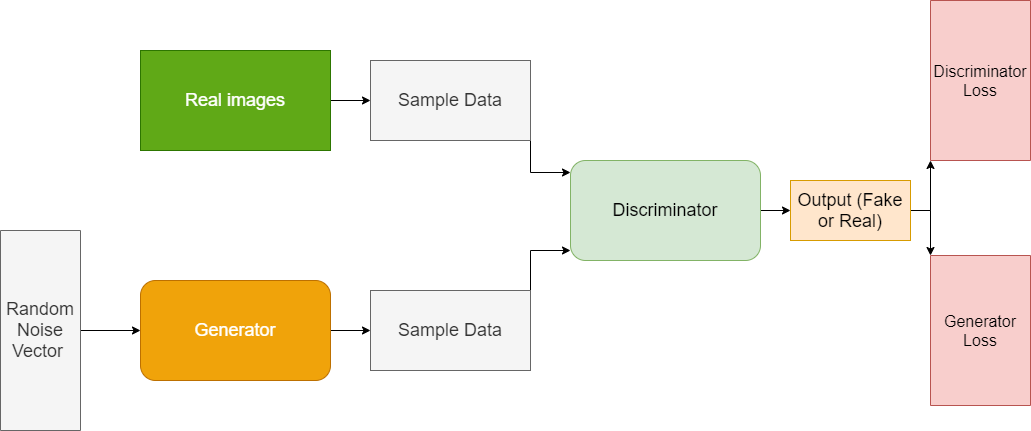
Le pouvoir des réseaux adversariaux vient du fait que le discriminateur et le générateur peuvent être non linéaire et constituent deux réseaux de neurones distincts qui s'entraînent simultanément.
De manière un peu plus formelle : Pour apprendre la distribution , le générateur construit un mapping entre une distribution de bruit à priori et une loi de probabilité = . Le discriminateur renvoie une probabilité que proviennent d'une donnée réelle plutôt que de .
Cette solution originale renvoie à l'idée du problème de la théorie des jeux min-max dans lequel 2 joueurs ( and ) s'affrontent.
- Générateur : Le générateur a pour but d'apprendre une distribution très proche des données réelles, de manière à pouvoir duper le discriminateur.
- Discriminateur : Le discriminateur a pour but de classifier les images générées en deux classes distinctes : real vs fake.
Le générateur et le discriminateur s'affrontent en jouant au jeu min-max à somme nulle qui peut être modéliser par la fonction suivante :
Nous voulons nous assurer d'entraîner le discriminateur à classifier correctement les valeurs des images issues des images réelles et donc de maximiser
et en même temps le discriminateur doit être capable de détecter les fausses images en retournant une probabilité proche de 0 en maximisant .
Le générateur, quant à lui, veut duper le discriminateur, ainsi il va apprendre à produire des images qui sont de plus en plus similaires à la distribution des images réelles. Ainsi, le but du générateur est de minimiser .
Quels sont les cas d’usage ?
Il existe plusieurs cas d'usage des GANs, on en prendra quelques exemples :
Génération des images réelles de tous types
La mission principale des GANs est de générer des images réelles compréhensibles par les humains, aujourd'hui ils sont capables de générer des images de visages humains, de plantes, d'animaux, et de tout objets en 2D et en 3D qui n'ont jamais existé. On peut également générer des images à partir de textes, DALL.E 2 par exemple, peut créer des images et de l’art originaux et réalistes à partir d’une description textuelle.
La super-résolution d’image
Ce cas d'usage sert démontrer l’utilisation des GANs, en particulier du modèle SRGAN, pour générer des images de sortie avec une résolution de pixel plus élevée, parfois beaucoup plus élevée. Cette technique peut être utilisé pour améliorer des images de satellites.

Traduction image-to-image
Il s'agit de traduire des photographies à travers des domaines, tels que le jour à la nuit, l’été à l’hiver, et plus encore avec des CycleGANs.

À lire aussi : découvrez notre formation MLOps
Retouche de photos
Les GANs peuvent aussi être utilisés pour reconstruire des photos de visages avec des caractéristiques spécifiques, telles que les changements de couleur des cheveux, le style, l’expression du visage, le sexe et même l'angle de rotation du visage et l'âge.
On peut également compléter, colorer ou combiner des images pour obtenir des résultats très réalistes.

Génération d'autres types de données
Aujourd'hui, il est de plus possible de créer de la musique, de la parole, des vidéos, du texte, des parfums et même de la visualisation de sons en utilisant uniquement des GANs.
Un exemple de visualisation du son, un projet appelé NeuralSynesthesia. Il s'agit de la création d'expériences visuelles à partir du son, en commençant par analyser l'audio pour détecter les percussions et les éléments harmoniques, puis alimenter le GAN par ces éléments afin de créer une expérience visuelle unique.
Les variantes d'un GAN
Il existe de nombreuses applications de génération de données en utilisant des GANs et il existe également plusieurs variantes de ce réseau, des versions améliorées ou bien adaptées à des cas bien précis. On prendra quelque exemples :
- StyleGAN : C'est une variant du GAN, capable de générer des images à très haute résolution. La façon la plus simple pour un GAN de générer des images est de mémoriser les images de l’ensemble de données de formation et tout en générant de nouvelles images, il peut ajouter du bruit aléatoire à une image existante. En réalité, StyleGAN ne fait pas cela, mais il apprend des caractéristiques concernant le visage humain et génère une nouvelle image du visage humain qui n’existe pas concrètement.
- CycleGAN: Ce réseau permet de faire de la traduction d'images entre deux domaines A et B sans avoir à disposer de données d'apprentissage sous la forme de paires d'images A et B. À titre d’exemple, ce genre de formulation peut apprendre une fonction de mapping entre : - des images artistiques et réalistes. - l'image d'un cheval et d'un zèbre. - l'image hivernale et l’image estivale.
- Conditional GAN (ou GAN conditionnel) : Dans les cGAN, un paramètre conditionnel est appliqué, ce qui signifie que le générateur et le discriminateur sont tous deux conditionnés par une sorte d’information auxiliaire (comme des étiquettes de classe ou des données) provenant d’autres modalités. En conséquence, le modèle idéal peut apprendre la cartographie multimodale des entrées aux sorties en étant alimenté avec différentes informations contextuelles. Par exemple, un cGAN peut être conditionner à générer que des images d'un digit bien spécifique (par exemple 1) après avoir être entraîné à générer des images du jeu de données MNIST. Ou de générer que des visages d'homme à partir du jeu de données Face.
- SRGAN : est un algorithme de super-résolution d'image, c'est-à-dire qu'il permet de résoudre une image de faible résolution à une image de haute résolution.
Il existe d'autres variantes telles que le DiscoGAN et le IsGAN.
Même si l'apprentissage des modèles de génération d'images est long et difficile, car ce processus est très demandeur en puissance de calcul, plusieurs entreprise et particulier considèrent ces derniers comme une alternative et une approche plus spécifique pour la data augmentation. Dans le cas des domaines les plus complexes, notamment le Deep Learning par renforcement, où le volume de données est limité, les modèles génératifs permettent un meilleur entraînement des modèles tout en fournissant des volumes de données plus ou moins illimités et à faible coût.


