
Par Maxime Jumelle
CTO & Co-Founder
Publié le 13 mai 2022
Catégorie Machine Learning
Tests Python pour le Machine Learning
Dans l'univers du développement logiciel, les tests sont omniprésents. Ils permettent de vérifier que le logiciel ou l'application développée adopte correctement le comportement attendu, ne produit pas de bugs ou s'intègre efficacement dans un environnement existant.
Mais comment transposer tous ces tests de développement logiciel au cas où l'on entraîne et fait intervenir des modèles de Machine Learning ? Il n'est pas possible de rédiger des tests unitaires de la même façon, car un modèle fournit justement une prédiction, qui n'est a priori pas connu à l'avance. C'est pourquoi les Data Scientists et ML Engineers ont imaginé des méthodes de test à réaliser spécifiquement sur les modèles de Machine Learning.
Dans cet article, nous allons voir comment il est possible de formuler des tests logiciels adaptés aux modèles de Machine Learning.
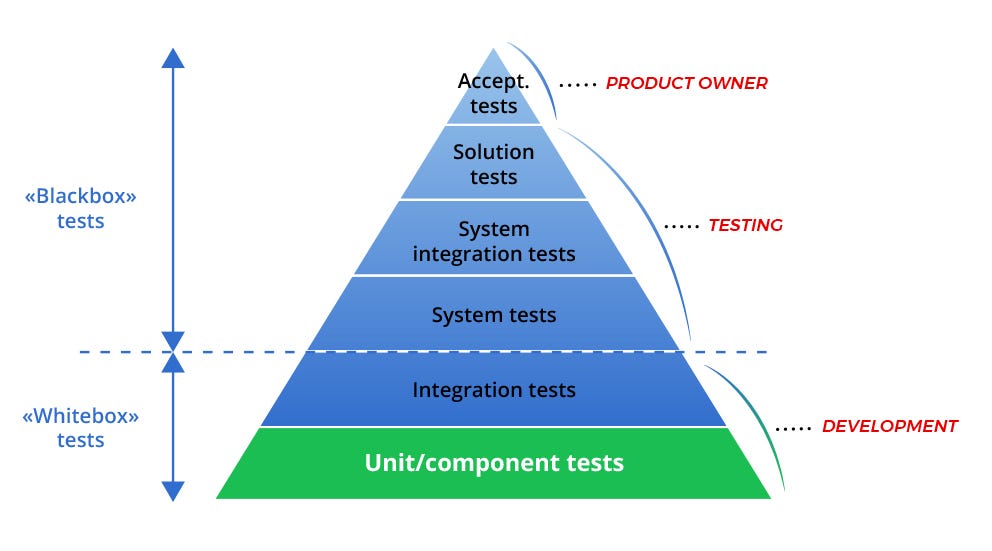
Tester des applications
Avant de rentrer dans les détails des tests d'algorithmes de Machine Learning, décrivons tout d'abord les bonnes pratiques héritées du développement logiciel.
À lire aussi : découvrez notre formation MLOps
Tests logiciels
Dans ce contexte, une suite de tests inclut habituellement trois composantes.
- Les tests unitaires, où l'on s'assure qu'une portion atomique du code fonctionne correctement (par exemple, une fonction). En règle générale, ce sont des tests rapides et faciles à mettre en place. Cet article présente de façon détaillée les tests unitaires en Python.
- Les tests de régression, où l'on doit s'assurer que le développement d'une nouvelle fonctionnalité ne va pas faire survenir un bug déjà rencontré par le passé.
- Les tests d'intégration, où on cherche à voir si la fonctionnalité développée va être correctement intégré dans l'application sans générer des erreurs dues à son interaction avec d'autres composantes. Ces erreurs sont en pratique plus difficiles à prévenir, d'où la difficulté de construire des tests d'intégration efficaces.
Dans les faits, les bonnes pratiques nécessitent de suivre plusieurs conventions. En travail collaboratif, notamment avec git, les règles de base suivantes sont appliquées.
- Ne jamais fusionner de branches si les tests ne sont pas valides.
- Toujours écrire des tests pour de nouvelles fonctionnalités.
- Lorsque l'on corrige un bug, toujours écrire le test et l'appliquer sur la correction.
Tests de modèles de Machine Learning
Essayons maintenant de transposer ce que nous venons de voir pour tester les modèles de Machine Learning. Une fois un modèle de Machine Learning calibré, nous souhaiterions obtenir un rapport d'évaluation contenant les informations suivantes.
- Performances avec des métriques définies sur des sous-ensembles (
X_testpar exemple). - Graphes de validation : courbe PR, courbe ROC, densité des classes, courbe de calibration.
- Audit du modèle avec des modèles d'interprétabilité (PDP, valeurs de Shapley).
- Sous-population où le modèle génère des faux-positifs ou faux-négatifs avec un fort degré de confiance.
Par ailleurs, on y retrouve également d'autres bonnes pratiques qui s'inscrivent toujours dans une logique de démarche de qualité.
- Toujours sauvegarder les hyper-paramètres, sous-échantillons utilisés et le modèle entraîné.
- Mettre à jour un environnement de production avec un modèle aux meilleures performances ou selon un seuil minimal.
Face à ces besoins de tester, nous pouvons voir que calculer des performances sur un sous-échantillon ou afficher des courbes n'est pas suffisant pour s'assurer que le modèle est « valide ». Pour les systèmes de Machine Learning, nous devrions effectuer deux méthodes en parallèle.
- L'évaluation de modèle, où l'on calcule ses performances, audite son fonctionnement et affiche des courbes.
- Le test de modèle où l'on développe des tests explicites pour vérifier que le comportement du modèle est bien celui attendu.
Test de modèles
Lorsque l'on fait référence aux tests de modèles, on cherche à vérifier le bon fonctionnement et comportement du modèle. Pour cela, nous distinguons deux classes de tests de modèles.
- Les tests pré-entraînement, qui nous permettent d'identifier des erreurs ou incohérences avant même l'entraînement du modèle.
- Les tests post-entraînement, qui vont utiliser le modèle entraîné et inspecter le comportement de ce dernier par rapport à des scénarios de référence que l'on décide en amont.
Il n'y a pas de meilleur test possible. Chaque test doit être défini en fonction du contexte, du cas d'application et surtout de l'importance que l'on accorde aux décisions du modèle.
Les tests pré-entraînement
Les tests pré-entraînement permettent d'éviter de se lancer dans l'entraînement d'un modèle si certains critères ne sont pas respectés. Très souvent, ces critères portent sur les données et les tests, bien que rapide à mettre en place, permettent déjà de soulever certains points. Parmi les tests qui peuvent être réalisés avant l'entraînement, nous retrouvons surtout de tests de cohérence des données.
- Taille du jeu de données.
- Format de la variable réponse.
- Proportion des classes dans la classification binaire.
- Représentativité de l'échantillon par rapport à la population d'étude.
En soi, il s'agit de tests qui peuvent être rédigés au même titre que les tests unitaires précédents. Définissons les tests du pipeline processing. Ce pipeline est composé de deux nodes, chacun appelant une fonction.
encode_features, qui va encoder numériquement les variables du datasetprimary.split_dataset, qui va séparer le jeu de données en une base d'apprentissage et une base de test.
Commençons par la fonction encode_features : elle s'attend à recevoir un DataFrame nommé dataset. Il y a plusieurs choses que nous devons vérifier à l'issue de cette fonction.
- La colonne
purchasedest-elle toujours intacte dans le sens où elle n'est constituée que de 0 et de 1 ? - Toutes les colonnes sont-elles numériques ?
- Avons-nous suffisamment d'observations pour entraîner le modèle ?
- Les proportions de classes positives et négatives sont-elles au moins supérieures à un seuil ?
Dès maintenant, nous pouvons définir plusieurs tests avant même d'entraîner un modèle, et donc d'éviter de gâcher des ressources si ces tests ne sont pas valides.
Tests post-entraînement
Les tests post-entraînement vont être exécutés une fois le modèle calibré. Contrairement aux tests précédents, ils sont plus subtils car l'objectif est de mettre en évidence certains aspects et comportements particuliers du modèle pour vérifier qu'ils n'aboutissent pas à des erreurs ou à des incohérences qui pourraient avoir d'importantes répercussions.
Pour cela, nous pouvons faire intervenir plusieurs outils.
- Des exemples de données dont on connaît (en dehors de la base d'apprentissage) les réponses.
- Les méthodes d'interprétabilité avec SHAP par exemple.
- Des méthodes d'évaluation de propriétés, comme la régularité de la loi jointe.
Commençons par récupérer le modèle de boosting que nous avions entraîné avec la base de test.
Tests d'invariance
Les tests d'invariance nous permettent de définir un ensemble de perturbations à appliquer sur une ou plusieurs observations pour observer à quel point cela affecte la sortie du modèle.
À lire aussi : découvrez notre formation MLOps
Par exemple, supposons qu'un utilisateur, ayant visité un produit dont le prix est de 59€. Un test d'invariance consisterait à dire qu'une variation de \(\pm 1€\) ne devrait pas faire varier la probabilité d'acheter de \(\pm x%\). Une variation importante pourrait signifier que cette variable a beaucoup d'impact, alors qu'en réalité, il est peu probable que pour un article de 59€ une variation de 1€ fasse drastiquement augmenter ou baisser la probabilité.
Calculons cette différence (en valeur absolue) de probabilité (pour la classe positive) pour chaque observation d'un jeu de données.

Tests directionnels
Les tests directionnels semblent proches des tests d'invariance, à la différence près que l'ensemble des perturbations que nous allons appliquer aux observations devraient avoir un effet connu à l'avance sur la sortie du modèle.

Tests unitaires du modèle
Au même titre que les tests unitaires sont réalisés pour les fonctions de collecte et de transformation de données, les tests unitaires pour le modèle consistent à vérifier que ce dernier prédit la bonne réponse pour des observations qui sont supposées être parfaitement classifiées.
Une méthode consiste à calculer des prototypes : il s'agit d'observations qui représentent le plus les données. En d'autres termes, il s'agit d'un concept proche des centres de clusters formés par les observations. Et un algorithme non-supervisé permettant de détecter les prototypes est le k-médoïde, proche des k-moyennes dans son fonctionnement mais qui calcule le médoïde, point d'un cluster dont la distance avec tous les autres points est la plus petite.
Quand utiliser des tests logiciels en Machine Learning
Faire des tests logiciels sur des modèles de Machine Learning demande du temps, car cela nécessite de bien comprendre le cas d'application du modèle, les considérations liées au phénomène que cherche à modéliser le modèle, mais également de les implémenter de manière robuste.
Il y a plusieurs situations où l'implémentation de tests sur les modèles est nécessaire.
- Dans l'approche MLOps, on cherche à automatiser l'entraînement de modèle sur des nouveaux jeux de données. En conséquence, même si le modèle restera le même, ses paramètres, et donc ses propriétés, seront différents. Face à ce constat, il est donc plus que recommandé de mettre en place des tests pour éviter de déployer en production un modèle qui ne satisferait pas des contraintes décisives.
- Pour les modèles qui évoluent dans des domaines sensibles et/ou réglementés, tels que l'assurance ou la médecine, il est important de s'assurer que le comportement du modèle ne sera pas chaotique une fois en production, ou tout du moins que son comportement reste un minimum prévisible.
Dans tous les cas, faire des tests de modèles reste une sage décision, au même titre que les tests logiciels que les développeurs doivent fournir.
Vous souhaitez vous former au MLOps ?
Articles similaires

20 sept. 2022
Hugging Face est une startup française qui s'est fait connaître grâce à l'infrastructure NLP qu'ils ont développée. Aujourd'hui, elle est sur le point de révolutionner le domaine du Machine Learning et traitement automatique du langage naturel. Dans cet article, nous allons présenter Hugging Face et détailler les taches de base que cette librairie permet de réaliser. Nous allons également énumérer ses avantages et ses alternatifs.
Équipe Blent
Data Scientist
Lire l'article

12 juil. 2022
spaCy est une bibliothèque open-source pour le traitement avancé du langage naturel. Elle est conçue spécifiquement pour une utilisation en production et permet de construire des applications qui traitent et comprennent de grands volumes de texte.
Équipe Blent
Data Scientist
Lire l'article

4 juil. 2022
Un auto-encodeur est une structure de réseaux neuronaux profonds qui s'entraîne pour réduire la quantité de données nécessaires pour représenter une donnée d'entrée. Ils sont couramment utilisés en apprentissage automatique pour effectuer des tâches de compression de données, d'apprentissage de représentations et de détection de motifs.
Équipe Blent
Data Scientist
Lire l'article
60 rue François 1er
75008 Paris
Blent est une plateforme 100% en ligne pour se former aux métiers Tech & Data.
Organisme de formation n°11755985075.

Data Engineering
IA Générative
MLOps
Cloud & DevOps
À propos
Gestion des cookies
© 2025 Blent.ai | Tous droits réservés