
Par Équipe Blent
Data Scientist
Publié le 28 mars 2022
Catégorie Machine Learning
Validation croisée en Machine Learning
Pour les êtres humains, la généralisation est la chose la plus naturelle possible. On peut classer à la volée. Par exemple, nous reconnaîtrions certainement un oiseau même si nous n’avions jamais vu un autre qui lui ressemble. Néanmoins, cela n'est pas évident du tout pour un modèle de Machine Learning.
Un modèle entraîné sur un jeu de données est capable de prédire les étiquettes des éléments de ce dernier. Mais une fois testé sur d'autres éléments, ce n'est pas vraiment certain qu'il ait la bonne réponse. C’est pourquoi vérifier la capacité de l’algorithme à généraliser est une tâche importante qui nécessite beaucoup d’attention lors de la construction du modèle. Pour ce faire, on utilise la validation croisée.
Dans cet article, nous allons détailler la notion de la validation d'un modèle prédictif, les méthodes et les techniques possibles, et comment et quand faut-il les utiliser.
Pourquoi utiliser la validation croisée ?
Faire entraîner un modèle prédictif et le tester sur les mêmes données est une erreur : un modèle qui n'a fait que répéter les étiquettes des échantillons qu’il vient de voir aurait un score parfait.
Le modèle dans ce cas peut déborder les données. Cela se produit parce qu’au lieu de comprendre la structure sous-jacente des données, il « mémorise » les caractères propres à cet ensemble de données et un problème apparaît ensuite lorsque le modèle est mis en production avec des données qu’il n’a jamais vues auparavant.
À lire aussi : découvrez notre formation MLOps
C'est pourquoi il est très important de tester la stabilité de son modèle de Machine Learning en évaluant sa performance avec des données encore inédites. En se basant sur les résultats de ce test, on pourra juger si un sur-apprentissage ou un sous-apprentissage a eu lieu, ou bien si le modèle est capable de généraliser.
Il existe des techniques de validation pour évaluer le rendement d’un modèle sur différents fractionnements de données afin d’atténuer les problèmes comme celui-ci, et pour sélectionner le modèle approprié pour le problème de modélisation prédictive en question. C'est ce qu'on appelle la validation croisée (ou Cross-validation en anglais).
La validation croisée a principalement trois objectifs :
- Évaluer la capacité d'un modèle prédictif à généraliser et produire des prédictions correctes avec n'importe quelle donnée.

- Régler les hyperparamètres d'un modèle dans l'objectif d'avoir les meilleurs résultats possibles. Il s'agit de tester la performance du modèle avec différentes configurations et en choisir la meilleure selon les résultats de la validation croisée.

- Comparer plusieurs modèles pour sélectionner celui le plus approprié pour le problème de modélisation puisque le choix de l'algorithme de prédiction dépend du type et des caractéristiques du jeu de données en question.

Bien qu’il y ait plusieurs méthodes de validation croisée, elles partagent des principes fondamentaux et chacune est adaptée à des situations bien précises. On peut citer, par exemple, la K-Fold, le Shuffle Split ou le Leave-One-Out.
Techniques de la validation croisée pour le Machine Learning
Il existe plusieurs façons d’évaluer les modèles de Machine Learning. Voici quelques exemples :
Jeux d’entraînement et de test
C'est la technique la plus simple et la plus courante. Vous ne savez peut-être pas que c’est une méthode de validation croisée, mais vous l’utilisez certainement tous les jours.
L'idée, c'est de couper notre jeu de données en deux parties : un jeu d'entraînement et un jeu de test. Habituellement, l'ensemble d'entrainement est environ 70% de l’ensemble de données et l’ensemble de test est 30 %, mais on peut choisir le fractionnement qui convient le mieux selon le jeu de données. Le jeu de test n’est pas utilisé pour entraîner le modèle, mais uniquement pour l’évaluer.
On entraîne tout d'abord son modèle avec le premier groupe et puis on utilise le groupe de test pour lui attribuer un score et évaluer son rendement avec les données qu'il ne connait pas.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
Cette méthode est très efficace surtout avec des jeux de données volumineux.
K-Fold
Dans cette technique, l’ensemble des données est divisé en k ensembles de tailles presque égales. Le premier ensemble est sélectionné comme ensemble de test et le modèle est entraînée sur les autres ensembles \(k-1\). Le taux d’erreur est ensuite calculé après ajustement du modèle aux données de test.

Dans la deuxième itération, le deuxième ensemble est sélectionné comme un ensemble de test et les autres ensembles k-1 sont utilisés pour l'entrainement et on calcule le taux d’erreur à nouveau. Ce processus se poursuit pour tous les k sets.
Le score final à attribuer à son modèle peut être retrouvé en moyennant les performances obtenues sur les k folds.
import numpy as np from sklearn.model_selection import KFold X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) y = np.array([1, 2, 3, 4]) kf = KFold(n_splits=2) for train_index, test_index in kf.split(X): print("TRAIN:", train_index, "TEST:", test_index) X_train, X_test = X[train_index], X[test_index] y_train,y_test = y[train_index], y[test_index]
TRAIN: [2 3] TEST: [0 1] TRAIN: [0 1] TEST: [2 3]
Le problème avec cette méthode, c'est qu'elle ne fonctionne pas très bien dans les cas de classification. Surtout si le nombre de classes n'est pas élevé, on risque d'avoir les mêmes étiquettes dans l'ensemble de test et dans l'ensemble d'entrainement. Cela va affecter négativement la performance du modèle.
Pour remédier à cela, on peut utiliser la stratification. C'est une variante de K-Fold qui renvoie des ensembles de données stratifiés, c'est-à-dire qu'en conserve le pourcentage d’échantillons pour chaque classe.
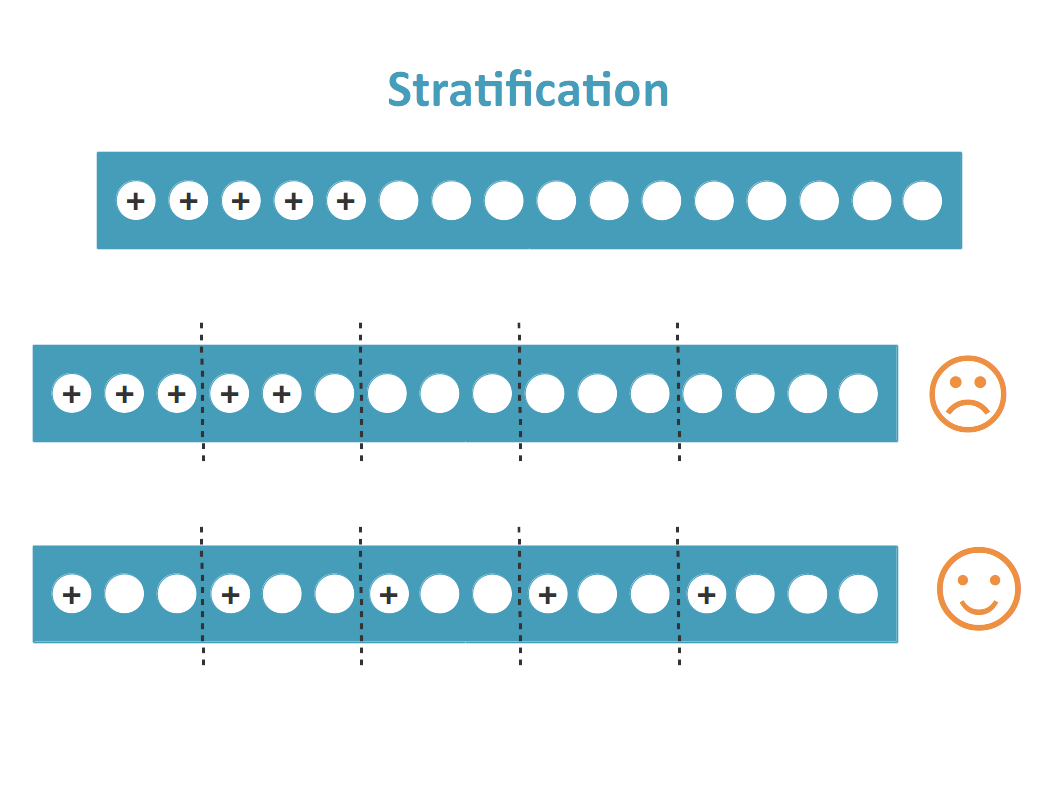
Au niveau du code, il suffit d'utiliser le module StratifiedKFold de la bibliothèque Scikit-Learn à la place de KFoldet ensuite effectuer le même travaille.
Leave One Out
Dans cette méthode, on divise les données en données d'entrainement et en bancs de test, mais cette fois d’une façon différente. Au lieu de diviser les données en 2 sous-ensembles, comme son nom l'indique, on choisit une seule observation comme données de test et tout le reste est étiqueté comme données d'entrainement.
À lire aussi : découvrez notre formation MLOps
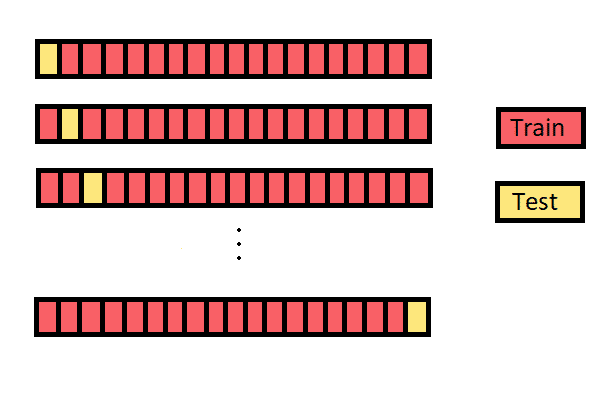
Maintenant, la deuxième observation est sélectionnée comme données de test et le modèle est entraîne sur les données restantes. Ce processus se poursuit pour toutes les observations. À chaque fois, on entraîne le modèle sur les données et on regarde s'il a pu trouver la bonne réponse pour l'observation qu'on a laissé à côté.
import numpy as np from sklearn.model_selection import LeaveOneOut X = np.array([[1, 2], [3, 4]]) y = np.array([1, 2]) loo = LeaveOneOut() for train_index, test_index in loo.split(X): print("TRAIN:", train_index, "TEST:", test_index) X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] print(X_train, X_test, y_train, y_test)
TRAIN: [1] TEST: [0] [[3 4]] [[1 2]] [2] [1] TRAIN: [0] TEST: [1] [[1 2]] [[3 4]] [1] [2]
Le problème avec cette méthode, c'est qu'on augmente fortement le temps de calcul puisqu'on fait entraîner autant de modèles que le nombre de points dans le jeu complet. Il est déconseillé d'utiliser cette méthode lorsqu'on est en train de travailler avec un grand volume de donnée, ce ne sera pas facile de tirer des conclusions.
Une solution possible à ce problème est d'utiliser le Leave P Out. Cette méthode crée tous les ensembles d'entrainement et de tests possibles en utilisant des échantillons p comme ensemble de tests. P représente le nombre d'éléments du groupe de test à laisser à côté à chaque fois.
Au niveau du code, il suffit d'utiliser le module LeavePOutde la bibliothèque Scikit-Learn à la place de LeaveOneOutet ensuite effectuer le même travaille. Les sorties cette fois seront des groupes distincts que ce soit pour les ensembles d'entraînement ou les ensembles de test .
La différence entre cette méthode et celle de K-Fold, c'est que le Leave P Out crée des ensembles de tests qui ne se chevauchent pas.
Monte Carlo (Shuffle-Split)
La validation croisée de Monte Carlo, aussi connue sous le nom de Shuffle Split, est une stratégie très flexible de validation croisée. Dans cette technique, les ensembles de données sont répartis aléatoirement en ensembles d'entrainement et de test.
Elle permet aussi de décider le pourcentage de l’ensemble de données que nous voulons utiliser comme ensemble d'entrainement et du pourcentage à utiliser comme ensemble de validation. Si le pourcentage ajouté de la taille de l’ensemble d'entrainement et de validation n’est pas égal à 100, le reste de l’ensemble de données n’est pas utilisé.

import numpy as np from sklearn.model_selection import ShuffleSplit X = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [3, 4], [5, 6]]) y = np.array([1, 2, 1, 2, 1, 2]) rs = ShuffleSplit(n_splits=5, train_size=0.5, test_size=.25,random_state=0) for train_index, test_index in rs.split(X): print("TRAIN:", train_index, "TEST:", test_index)
TRAIN: [1 3 0] TEST: [5 2] TRAIN: [4 0 2] TEST: [1 3] TRAIN: [1 2 4] TEST: [3 5] TRAIN: [3 4 1] TEST: [5 2] TRAIN: [3 5 1] TEST: [2 4]
StratifiedShuffleSplit est une fusion de StratifiedKFold et ShuffleSplit, qui renvoie des ensembles aléatoires stratifiés. Les ensembles sont réalisés en conservant le pourcentage d’échantillons pour chaque classe.
Cette méthode peut être utilisé pour s'assurer que les ensembles obtenus n'aient pas les mêmes étiquettes, mais elle ne garantit pas que ces derniers ne soient pas répétés dans certaines itérations, ce qui est très probable dans le cas de jeux de données peu volumineux. Il est conseillé alors d'utiliser cette technique avec des données de grande taille.
Les séries temporelles
Les techniques traditionnelles de validation croisée ne fonctionnent pas sur les données séquentielles comme les séries chronologiques parce qu'on ne peut pas choisir des points de données aléatoires et les attribuer à l’ensemble de test ou à l’ensemble d'entrainement, car il n’est pas logique d’utiliser les valeurs du futur pour prévoir les valeurs dans le passé.
Il y a principalement deux façons de procéder.
- La méthode roulante :
Dans cette méthode, on va commencer par un petit sous-ensemble de données comme ensemble d'entrainement, on fait des prédictions pour les points de données ultérieurs, puis on vérifie l’exactitude des points de données prévus. Les mêmes points de données prévus sont ensuite inclus dans le prochain ensemble de données d'entrainement et les points de données subséquents sont prévus.

import numpy as np from sklearn.model_selection import TimeSeriesSplit X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]]) y = np.array([1, 2, 3, 4, 5, 6]) tscv = TimeSeriesSplit(n_splits=5) for train_index, test_index in tscv.split(X): print("TRAIN:", train_index, "TEST:", test_index) X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index]
TRAIN: [0] TEST: [1] TRAIN: [0 1] TEST: [2] TRAIN: [0 1 2] TEST: [3] TRAIN: [0 1 2 3] TEST: [4] TRAIN: [0 1 2 3 4] TEST: [5]
- La méthode bloquante :
L’idée est de diviser l’ensemble de formation en deux plis à chaque itération à condition que l’ensemble de validation soit toujours en avance sur l’ensemble d'entrainement. Lors de la première itération, on entraîne le modèle candidat, par exemple, sur les données de janvier à février et on valide avec les données de mars, et pour la prochaine itération, on entraîne sur les données d'avril à juin, et on valide sur les données d’août, et ainsi de suite jusqu’à la fin de l’ensemble d'entrainement. De cette façon, la dépendance est respectée.
À lire aussi : découvrez notre formation MLOps

La validation croisée pour le Deep Learning
Pour les modèles Deep Learning, généralement on n'utilise pas les techniques qui nécessitent d’entraîner un modèle plusieurs fois. Cela sera très coûteux en matière de temps de calculs.
La méthode la plus utiliser dans ce cas est de diviser l’ensemble de données en trois parties.
- Ensemble d'entrainement : une partie de l’ensemble de données pour l'entrainement du modèle.
- Ensemble de validation : une partie de l’ensemble de données pour valider pendant l'entrainement.
- Ensemble de test : une partie de l’ensemble de données pour la validation finale du modèle.
Lorsqu'on travaille avec des réseaux de neurones simple ou rapide à entraîner, on peut utiliser les autres méthodes comme le K-fold. Dans ce cas, il n'y a pas une différence entre le Machine Learning et le Deep Learning.
En bref, La validation croisée est une technique pour évaluer un modèle et tester ses performances. C'est un outil puissant, très facile à utiliser. Le plus important, c'est d'être logique lors du choix des pourcentages de division de son jeu de données et de choisir la bonne approche pour chaque cas d'utilisation.
Articles similaires

20 sept. 2022
Hugging Face est une startup française qui s'est fait connaître grâce à l'infrastructure NLP qu'ils ont développée. Aujourd'hui, elle est sur le point de révolutionner le domaine du Machine Learning et traitement automatique du langage naturel. Dans cet article, nous allons présenter Hugging Face et détailler les taches de base que cette librairie permet de réaliser. Nous allons également énumérer ses avantages et ses alternatifs.
Équipe Blent
Data Scientist
Lire l'article

12 juil. 2022
spaCy est une bibliothèque open-source pour le traitement avancé du langage naturel. Elle est conçue spécifiquement pour une utilisation en production et permet de construire des applications qui traitent et comprennent de grands volumes de texte.
Équipe Blent
Data Scientist
Lire l'article

4 juil. 2022
Un auto-encodeur est une structure de réseaux neuronaux profonds qui s'entraîne pour réduire la quantité de données nécessaires pour représenter une donnée d'entrée. Ils sont couramment utilisés en apprentissage automatique pour effectuer des tâches de compression de données, d'apprentissage de représentations et de détection de motifs.
Équipe Blent
Data Scientist
Lire l'article
60 rue François 1er
75008 Paris
Blent est une plateforme 100% en ligne pour se former aux métiers Tech & Data.
Organisme de formation n°11755985075.

Data Engineering
IA Générative
MLOps
Cloud & DevOps
À propos
Gestion des cookies
© 2025 Blent.ai | Tous droits réservés