Détecter le Data Drift et le Concept Drift en production
Le Data Drift et le Concept Drift sont deux phénomènes critiques que tout Machine Learning Engineer doit surveiller en production. Ces dérives, souvent silencieuses, peuvent progressivement dégrader les performances d'un modèle sans qu'aucune alerte technique ne soit déclenchée. Comprendre ces mécanismes et mettre en place des systèmes de détection adaptés est devenu une compétence essentielle dans l'approche MLOps.

Le Data Drift et le Concept Drift sont deux phénomènes critiques que tout Machine Learning Engineer doit surveiller en production. Ces dérives, souvent silencieuses, peuvent progressivement dégrader les performances d'un modèle sans qu'aucune alerte technique ne soit déclenchée. Comprendre ces mécanismes et mettre en place des systèmes de détection adaptés est devenu une compétence essentielle dans l'approche MLOps.
En effet, un modèle performant lors de son déploiement peut rapidement devenir obsolète si les données qu'il reçoit en production diffèrent de celles sur lesquelles il a été entraîné. Cette problématique, souvent sous-estimée, est pourtant responsable d'une grande partie des échecs de projets Machine Learning en environnement réel.
Comprendre les différents types de drift
Avant de mettre en place des stratégies de détection, il est crucial de bien distinguer les deux types de dérives que l'on rencontre en production.
Le Data Drift (ou covariate shift) correspond à un changement dans la distribution des données d'entrée au fil du temps. Concrètement, les features que reçoit votre modèle en production ne ressemblent plus à celles utilisées lors de l'entraînement. Ce phénomène peut avoir plusieurs origines :
- Un changement de comportement des utilisateurs (nouvelles habitudes de consommation, évolution démographique).
- Une modification dans les systèmes en amont qui alimentent le modèle (changement de capteur, mise à jour d'une API tierce).
- Des effets saisonniers ou des événements externes (crise économique, pandémie, nouvelles réglementations).
Le Concept Drift, quant à lui, est plus subtil. Il survient lorsque la relation entre les variables d'entrée et la variable cible évolue. Autrement dit, même si vos données d'entrée restent similaires, la "bonne réponse" n'est plus la même. Un exemple classique est celui d'un modèle de scoring crédit : les critères qui définissaient un bon payeur en 2019 ne sont peut-être plus les mêmes après une crise économique majeure.
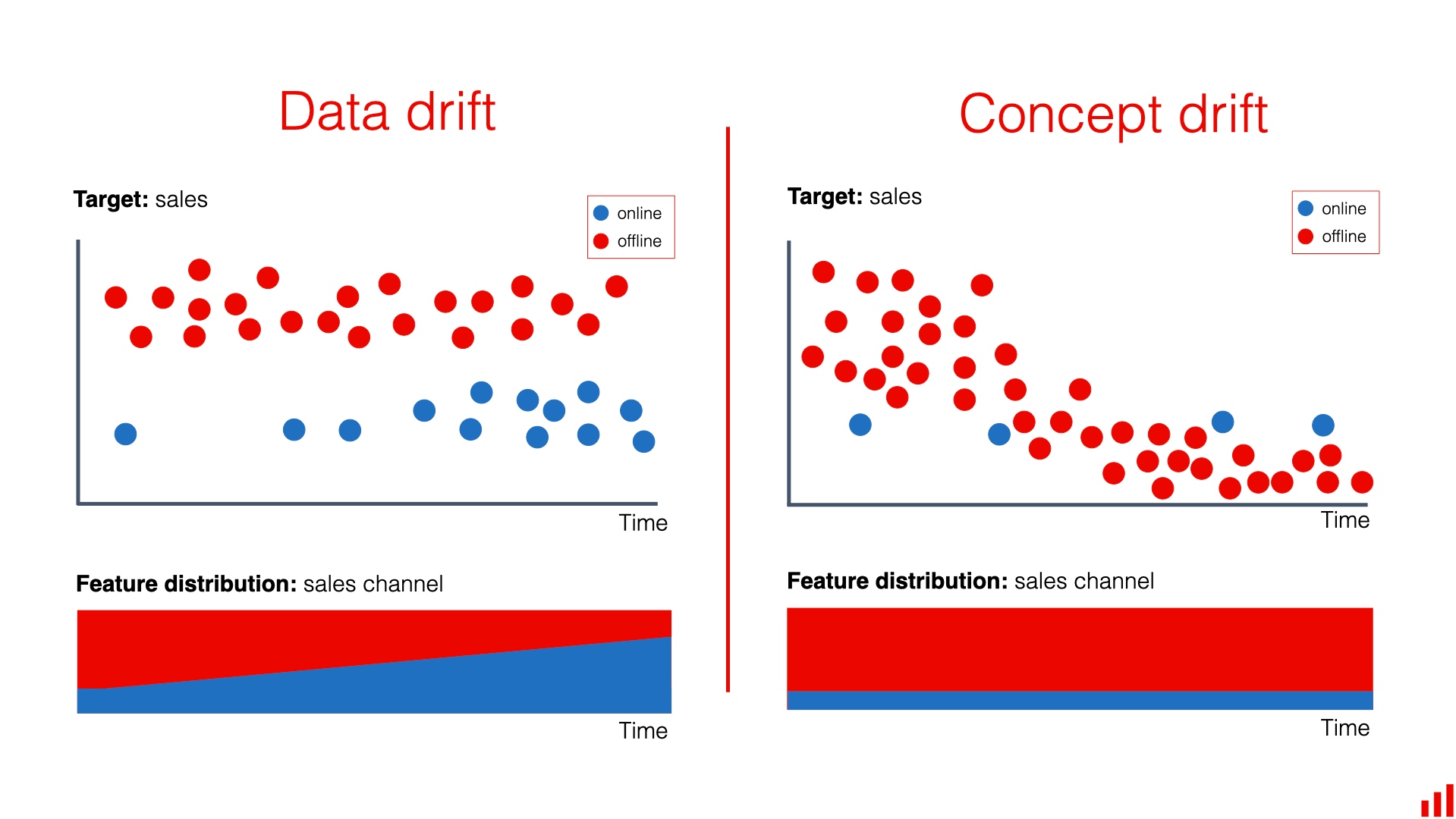
Il existe également des variantes de ces dérives selon leur temporalité :
| Type de drift | Caractéristique | Exemple |
|---|---|---|
| Drift soudain | Changement brutal et permanent | Nouvelle réglementation |
| Drift graduel | Évolution lente et continue | Changement démographique |
| Drift récurrent | Pattern cyclique ou saisonnier | Comportement d'achat selon les fêtes |
| Drift temporaire | Changement ponctuel puis retour à la normale | Événement exceptionnel |
À lire aussi : découvrez notre formation MLOps
Méthodes de détection des dérives
La détection des drifts repose sur des approches statistiques permettant de comparer les distributions de données entre une période de référence (généralement les données d'entraînement) et les données de production.
Tests statistiques pour le Data Drift
Pour les variables numériques, plusieurs tests sont couramment utilisés. Le test de Kolmogorov-Smirnov (KS) compare les fonctions de répartition cumulatives de deux échantillons et est particulièrement adapté pour détecter des différences globales de distribution. Le test de Wasserstein (ou Earth Mover's Distance) mesure le "coût" de transformation d'une distribution en une autre, offrant une interprétation plus intuitive.
Pour les variables catégorielles, le test du Chi-2 ou la divergence de Jensen-Shannon permettent d'évaluer si les proportions de chaque catégorie ont significativement changé.
from scipy import stats
import numpy as np
# Données de référence (entraînement) et de production
reference_data = np.random.normal(0, 1, 1000)
production_data = np.random.normal(0.5, 1.2, 1000) # Distribution décalée
# Test de Kolmogorov-Smirnov
ks_statistic, p_value = stats.ks_2samp(reference_data, production_data)
if p_value < 0.05:
print(f"Data Drift détecté ! (p-value: {p_value:.4f})")
else:
print("Pas de drift significatif détecté")
python
Surveillance du Concept Drift
La détection du Concept Drift est plus complexe car elle nécessite d'avoir accès aux vraies valeurs cibles (ground truth), ce qui n'est pas toujours immédiat en production. Plusieurs stratégies peuvent être mises en place :
- Monitoring des métriques de performance : suivre l'évolution de l'accuracy, du F1-score ou de l'AUC au fil du temps lorsque les labels sont disponibles.
- Analyse des résidus : pour les problèmes de régression, observer si les erreurs de prédiction changent de pattern.
- Détection par fenêtre glissante : comparer les performances du modèle entre différentes fenêtres temporelles.
Outils de monitoring en production
Plusieurs solutions permettent d'industrialiser la détection des drifts et de l'intégrer dans un pipeline MLOps.
Evidently AI
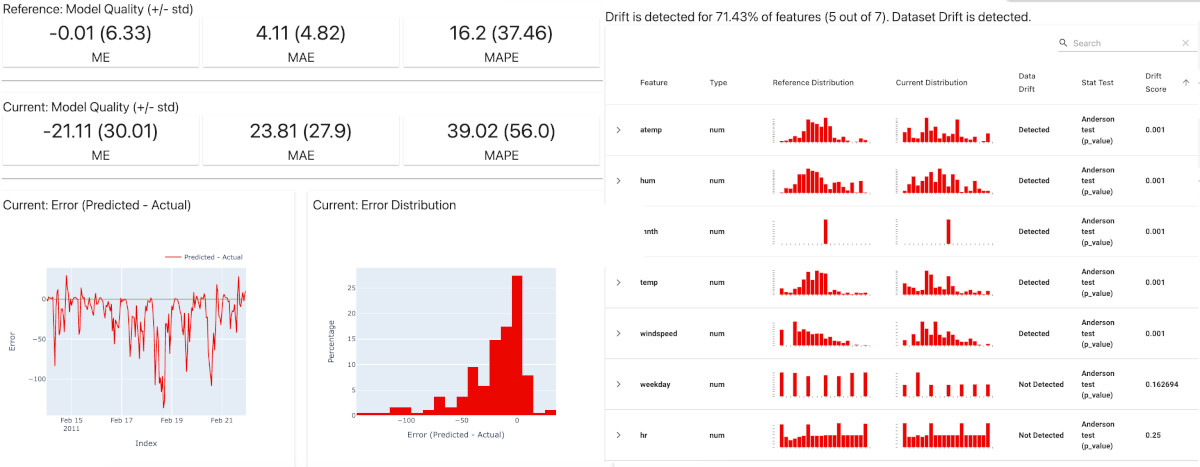
Evidently AI est devenu l'un des outils de référence pour le monitoring des modèles de Machine Learning. Cette librairie open source permet de générer des rapports détaillés sur la qualité des données et les performances des modèles.
import pandas as pd
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset, TargetDriftPreset
# Chargement des données
reference = pd.read_csv("data/reference.csv")
current = pd.read_csv("data/production.csv")
# Création du rapport de Data Drift
data_drift_report = Report(metrics=[
DataDriftPreset(),
])
data_drift_report.run(
reference_data=reference,
current_data=current
)
# Export du rapport
data_drift_report.save_html("drift_report.html")
python
Evidently propose plusieurs fonctionnalités particulièrement utiles :
- Des rapports visuels interactifs permettant d'explorer les dérives variable par variable.
- Des tests automatisés intégrables dans des pipelines CI/CD pour déclencher des alertes.
- Un monitoring en temps réel via l'intégration avec des outils comme Grafana ou Prometheus.
Intégration dans un pipeline MLOps
Pour être véritablement efficace, la détection des drifts doit être intégrée dans une stratégie MLOps globale. Voici un exemple d'architecture :
import mlflow
from evidently.test_suite import TestSuite
from evidently.tests import TestNumberOfDriftedColumns
def check_data_drift(reference_data, current_data, threshold=0.3):
"""
Vérifie le data drift et log les résultats dans MLflow
"""
suite = TestSuite(tests=[
TestNumberOfDriftedColumns(lt=int(len(reference_data.columns) * threshold))
])
suite.run(reference_data=reference_data, current_data=current_data)
result = suite.as_dict()
with mlflow.start_run():
mlflow.log_metric("drift_detected", 1 if not result["summary"]["all_passed"] else 0)
mlflow.log_metric("drifted_columns_count", result["summary"]["failed"])
if not result["summary"]["all_passed"]:
# Déclencher une alerte ou un ré-entraînement
trigger_retraining_pipeline()
return result
python
À lire aussi : découvrez notre formation MLOps
D'autres outils méritent également d'être mentionnés. Alibi Detect propose des méthodes avancées de détection de drift, notamment basées sur le Deep Learning. NannyML se spécialise dans l'estimation des performances du modèle sans avoir besoin des labels (très utile quand le ground truth arrive avec du délai). Whylogs permet de profiler les données en temps réel avec une empreinte mémoire très faible.
Stratégies de réaction face aux dérives
Détecter un drift n'est que la première étape. Encore faut-il savoir comment réagir. Plusieurs stratégies peuvent être envisagées selon le contexte :
Le ré-entraînement périodique consiste à mettre à jour le modèle à intervalles réguliers, que du drift soit détecté ou non. Cette approche simple convient aux environnements où les dérives sont graduelles et prévisibles.
Le ré-entraînement déclenché lance une mise à jour du modèle uniquement lorsqu'un drift significatif est détecté. Cette stratégie est plus efficace en termes de ressources mais nécessite un système de monitoring robuste.
L'apprentissage en ligne (online learning) permet au modèle de s'adapter continuellement aux nouvelles données. Cette approche est particulièrement adaptée aux environnements très dynamiques mais demande une architecture plus complexe.
Le fallback consiste à maintenir plusieurs versions du modèle et à basculer vers une version plus générique ou plus récente en cas de drift détecté.
Conclusion
La surveillance des dérives en production est un pilier fondamental du MLOps moderne. Un modèle de Machine Learning n'est jamais figé : il évolue dans un environnement dynamique où les données et les comportements changent constamment. Mettre en place une stratégie de détection du Data Drift et du Concept Drift permet d'anticiper la dégradation des performances et de maintenir la fiabilité des systèmes de prédiction.
Des outils comme Evidently AI, combinés à des plateformes de tracking comme MLflow, offrent aujourd'hui les moyens d'industrialiser cette surveillance. L'enjeu pour les équipes Data n'est plus seulement de déployer des modèles performants, mais de s'assurer qu'ils le restent dans la durée. En intégrant ces pratiques dès la conception des pipelines, les Machine Learning Engineers peuvent garantir une qualité de service constante et réagir rapidement aux évolutions du contexte métier.


