Devenir Développeur IA : tout savoir
Le métier de développeur connaît une transformation profonde avec l'émergence de l'IA générative. Là où l'intelligence artificielle était autrefois le domaine réservé des Data Scientists et des chercheurs en machine learning, la donne a radicalement changé. Aujourd'hui, n'importe quel développeur peut intégrer des capacités d'IA dans ses applications sans avoir à maîtriser les mathématiques complexes de l'apprentissage profond ou à entraîner ses propres modèles.

Le métier de développeur connaît une transformation profonde avec l'émergence de l'IA Générative. Là où l'intelligence artificielle était autrefois le domaine réservé des Data Scientists et des chercheurs en machine learning, la donne a radicalement changé. Aujourd'hui, n'importe quel développeur peut intégrer des capacités d'IA dans ses applications sans avoir à maîtriser les mathématiques complexes de l'apprentissage profond ou à entraîner ses propres modèles.
Cette démocratisation s'explique par l'émergence des LLM accessibles via API, des frameworks d'orchestration comme LangChain ou LlamaIndex, et d'une multitude d'outils qui abstraient la complexité technique. Le rôle de développeur IA — parfois appelé AI Engineer ou LLM Engineer — est devenu une spécialisation à part entière, distincte de la Data Science traditionnelle et centrée sur l'intégration et l'orchestration de modèles existants.
Dans cet article, nous allons explorer le parcours pour devenir développeur IA, en détaillant les compétences essentielles à acquérir et les étapes clés de cette montée en compétence. De la compréhension des fondamentaux jusqu'au déploiement en production, voici la roadmap complète pour transformer vos compétences de développeur en expertise IA.
Les fondamentaux : comprendre et interagir avec les LLM
Avant de construire des applications sophistiquées, il est essentiel de maîtriser les concepts fondamentaux qui sous-tendent les modèles de langage modernes. Cette première étape pose les bases sur lesquelles tout le reste s'appuie.
L'architecture Transformer, introduite en 2017, constitue le socle technique de tous les LLM actuels. Sans entrer dans les détails mathématiques, comprendre les principes de l'attention et du traitement séquentiel permet de mieux appréhender les forces et limites de ces modèles : leur capacité à capturer des dépendances longues dans le texte, mais aussi leur sensibilité à la formulation des requêtes.
Le Prompt Engineering représente l'art de formuler des instructions efficaces pour obtenir les réponses souhaitées. Cette compétence, souvent sous-estimée, fait une différence considérable dans la qualité des résultats obtenus. Les techniques clés incluent :
- Le few-shot prompting : fournir quelques exemples du comportement attendu
- Le chain-of-thought : demander au modèle de raisonner étape par étape
- La structuration claire des instructions avec des délimiteurs et des formats de sortie explicites
Au-delà du prompt lui-même, le Context Engineering élargit la réflexion à l'ensemble des informations fournies au modèle : system prompts, historique de conversation, documents de référence, métadonnées utilisateur. Orchestrer ce contexte de manière optimale devient crucial lorsque la fenêtre de contexte du modèle se remplit.
| Concept | Description | Importance |
|---|---|---|
| Transformers | Architecture des LLM modernes | Comprendre les capacités et limites |
| Prompt Engineering | Formulation des instructions | Qualité des réponses |
| Context Engineering | Gestion du contexte complet | Applications complexes |
| Hugging Face | Plateforme de modèles et datasets | Écosystème incontournable |
| SDK et APIs | Interfaces d'accès aux modèles | Intégration technique |
L'écosystème Hugging Face constitue une ressource incontournable. Cette plateforme centralise des milliers de modèles pré-entraînés, des datasets, et des outils comme la librairie Transformers. Savoir naviguer dans ce catalogue, charger un modèle, et utiliser les pipelines standard fait partie des compétences de base du développeur IA.
Enfin, la maîtrise des SDK fournis par les principaux providers (OpenAI, Anthropic, Mistral) permet d'interagir programmatiquement avec les modèles. Ces interfaces exposent des fonctionnalités avancées comme le streaming de réponses, les function calls, ou le contrôle fin des paramètres de génération (température, top_p, etc.).
À découvrir : notre formation LLM Engineering
Embeddings et recherche sémantique
La deuxième étape du parcours introduit une brique technique fondamentale : les embeddings. Ces représentations vectorielles du texte permettent de capturer le sens sémantique des mots et des phrases, ouvrant la voie à des fonctionnalités puissantes comme la recherche par similarité.
Un embedding transforme un texte — mot, phrase ou document entier — en un vecteur de plusieurs centaines de dimensions. Deux textes sémantiquement proches auront des vecteurs proches dans cet espace, même s'ils utilisent des mots différents. Cette propriété est à la base de la recherche sémantique, bien plus puissante que la recherche par mots-clés traditionnelle.
Les Sentence Transformers constituent la référence open source pour générer des embeddings de qualité. Ces modèles, disponibles sur Hugging Face, permettent d'encoder du texte en vecteurs optimisés pour la similarité sémantique :
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = model.encode(["Première phrase", "Deuxième phrase"])
python
Pour exploiter ces embeddings à l'échelle, les bases de données vectorielles deviennent indispensables. Des solutions comme Pinecone, Weaviate, Qdrant ou Chroma permettent de stocker des millions de vecteurs et d'effectuer des recherches de similarité en millisecondes. Comprendre leurs spécificités — indexation, filtrage par métadonnées, performances — fait partie des compétences attendues du développeur IA.
Construire des systèmes RAG
Le RAG (Retrieval Augmented Generation) représente l'une des applications les plus répandues de l'IA générative en entreprise. Ce pattern architectural permet d'augmenter les connaissances d'un LLM avec des données propriétaires, résolvant le problème fondamental de la connaissance figée des modèles.
Les composants d'un pipeline RAG
Un système RAG se décompose en plusieurs étapes, chacune nécessitant des choix techniques :
-
Chunking : découper les documents en segments de taille appropriée. Trop grands, ils diluent l'information pertinente ; trop petits, ils perdent le contexte. Les stratégies varient : découpage fixe, par phrases, par paragraphes sémantiques.
-
Embedding et indexation : vectoriser chaque chunk et le stocker dans une base vectorielle. Le choix du modèle d'embedding impacte directement la qualité de la récupération.
-
Retrieval : à partir d'une question utilisateur, récupérer les chunks les plus pertinents. Les retrievers naïfs utilisent une simple similarité cosine, tandis que les approches avancées combinent recherche dense et sparse via des techniques comme le Reciprocal Rank Fusion.
-
Reranking : réordonner les résultats avec un modèle de reranking plus précis mais plus lent, permettant d'affiner la sélection des documents réellement pertinents.
-
Génération : injecter les chunks récupérés dans le contexte du LLM pour générer une réponse augmentée.
Optimisation et évaluation
Construire un RAG fonctionnel est relativement simple grâce à des frameworks comme LlamaIndex. L'optimiser pour la production demande davantage d'expertise :
- Les métadonnées et filtres permettent de restreindre la recherche à des sous-ensembles pertinents (par date, par source, par catégorie).
- L'évaluation des performances avec des outils comme RAGAS mesure la fidélité des réponses, la pertinence du contexte récupéré, et l'absence d'hallucinations.
- Les traces et observabilité permettent de debugger les requêtes problématiques et d'identifier les points d'amélioration.
Agents IA et systèmes multi-agents
L'IA agentique représente l'évolution naturelle au-delà du RAG. Plutôt que de simplement récupérer et synthétiser de l'information, un agent peut planifier, raisonner et agir de manière autonome pour accomplir des tâches complexes.
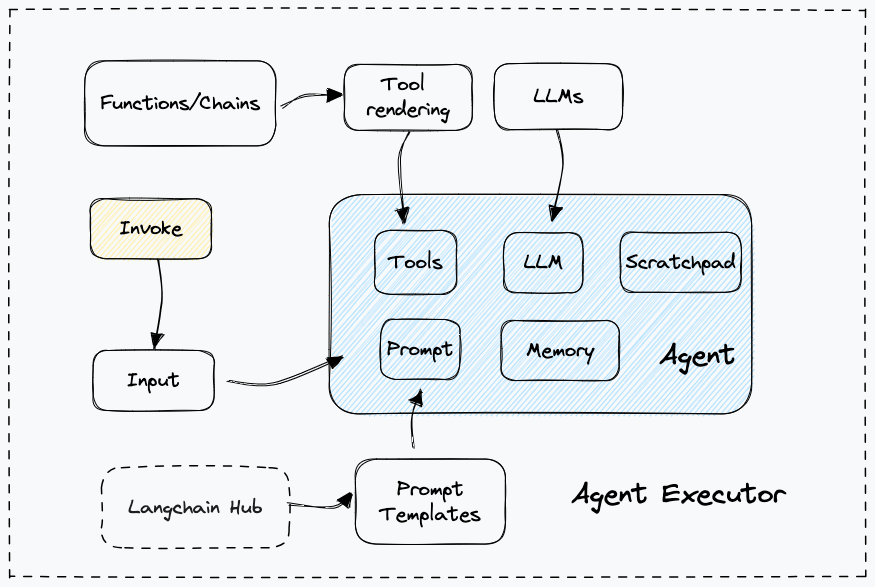
Un agent se caractérise par une architecture en boucle : il observe son environnement, réfléchit à la prochaine action à effectuer, l'exécute via un outil, puis itère jusqu'à atteindre son objectif. Cette capacité à orchestrer plusieurs étapes de manière autonome ouvre des possibilités considérables.
Les compétences clés pour développer des agents incluent :
- La définition d'outils : chaque capacité de l'agent (recherche web, exécution de code, appels API) est exposée comme un outil avec une description précise que le LLM peut invoquer.
- La communication entre outils : les agents sophistiqués chaînent plusieurs outils, passant les résultats de l'un comme entrée de l'autre.
- Les systèmes multi-agents : plusieurs agents spécialisés collaborent, avec des mécanismes de délégation et de coordination.
- Le protocole MCP (Model Context Protocol) : standard émergent pour exposer des outils de manière interopérable entre différents systèmes.
L'évaluation des agents pose des défis spécifiques. Au-delà de la qualité des réponses, il faut mesurer la pertinence de la sélection des outils, l'efficacité du plan d'exécution, et la robustesse face aux erreurs. Le monitoring des appels — tracer chaque invocation d'outil, chaque décision de l'agent — devient essentiel pour debugger et améliorer ces systèmes.
Déployer en production
La dernière étape du parcours concerne le passage à la production, où les préoccupations d'ingénierie logicielle classiques s'appliquent pleinement aux applications IA.
La conteneurisation avec Docker est le standard pour packager les applications IA avec leurs dépendances. Un Dockerfile bien conçu garantit la reproductibilité et facilite le déploiement sur différents environnements.
Pour les équipes qui souhaitent servir leurs propres modèles plutôt que d'utiliser des APIs tierces, des outils comme vLLM permettent de déployer des serveurs d'inférence optimisés. Ces solutions implémentent des techniques avancées (continuous batching, paged attention) pour maximiser le throughput.
Les applications IA en production nécessitent également :
- Des files d'attente pour gérer les pics de charge et lisser les requêtes vers les APIs de modèles
- Le HTTP streaming pour afficher les réponses progressivement plutôt que d'attendre la génération complète
- Le checkpointing pour sauvegarder l'état des tâches longues et permettre la reprise en cas d'erreur
- Des proxies inverses pour gérer le load balancing, le rate limiting, et la terminaison SSL
| Aspect production | Outils / Technologies | Objectif |
|---|---|---|
| Conteneurisation | Docker, Kubernetes | Reproductibilité, scalabilité |
| Serving de modèles | vLLM, TGI | Performance d'inférence |
| Gestion de charge | Redis, RabbitMQ | Lissage des pics |
| Streaming | SSE, WebSockets | Expérience utilisateur |
| Observabilité | LangSmith, Langfuse | Debugging, monitoring |
Conclusion
Le parcours pour devenir développeur IA suit une progression logique : des fondamentaux de l'interaction avec les LLM jusqu'au déploiement de systèmes complexes en production. Chaque étape construit sur la précédente, permettant une montée en compétence progressive et structurée.
L'essentiel à retenir est que ce parcours est accessible à tout développeur motivé. Contrairement à la Data Science qui exige une solide formation mathématique, le développement IA s'appuie sur des compétences d'ingénierie logicielle classiques : conception d'architecture, intégration de services, gestion de la production. Les modèles de langage deviennent des composants à orchestrer, pas des algorithmes à implémenter.
Les opportunités professionnelles sont considérables. Les entreprises recherchent massivement des profils capables de transformer les capacités des LLM en applications métier concrètes. Que ce soit pour construire des assistants conversationnels, des systèmes de recherche intelligents, ou des agents autonomes, les compétences de développeur IA sont aujourd'hui parmi les plus demandées du marché.
Pour ceux qui souhaitent structurer leur apprentissage, les ressources ne manquent pas : documentation des frameworks, tutoriels pratiques, et formations spécialisées permettent d'acquérir ces compétences de manière efficace. L'écosystème évolue rapidement, mais les fondamentaux présentés dans cet article constituent une base solide qui restera pertinente quelle que soit l'évolution des outils spécifiques.


