RAGAS : l'outil d'évaluation de LLM
RAGAS (Retrieval Augmented Generation Assessment) est une librairie Python open source conçue spécifiquement pour évaluer les pipelines d'IA générative. Son approche repose sur un principe devenu incontournable dans le domaine : utiliser des LLM pour évaluer d'autres LLM, une technique connue sous le nom de LLM as a Judge.

L'évaluation des systèmes d'IA générative représente l'un des défis les plus complexes auxquels font face les équipes qui déploient des solutions basées sur les LLM. Comment mesurer objectivement la qualité d'une réponse générée ? Comment s'assurer qu'un système de RAG récupère les bons documents et les synthétise correctement ? Ces questions, longtemps restées sans réponse standardisée, trouvent aujourd'hui une solution avec RAGAS.
RAGAS (Retrieval Augmented Generation Assessment) est une librairie Python open source conçue spécifiquement pour évaluer les pipelines d'IA générative. Son approche repose sur un principe devenu incontournable dans le domaine : utiliser des LLM pour évaluer d'autres LLM, une technique connue sous le nom de "LLM as a Judge". Cette méthodologie permet d'automatiser l'évaluation à grande échelle tout en maintenant une pertinence que les métriques traditionnelles ne peuvent atteindre.
Dans cet article, nous allons explorer ce qu'est RAGAS, comprendre les métriques qu'il propose, et découvrir comment l'intégrer concrètement dans vos projets pour garantir la qualité de vos systèmes d'IA générative.
Pourquoi évaluer les systèmes RAG est si complexe
L'évaluation des systèmes de génération de texte a toujours posé des problèmes fondamentaux. Les métriques classiques comme BLEU ou ROUGE, héritées de la traduction automatique, comparent des chaînes de caractères et échouent à capturer la richesse sémantique des réponses générées par les LLM. Une réponse parfaitement correcte mais formulée différemment de la référence sera mal notée, tandis qu'une réponse reprenant les mêmes mots mais incohérente pourra obtenir un bon score.
Pour les systèmes RAG, la complexité est encore plus grande car l'évaluation doit couvrir plusieurs dimensions :
- La qualité de la récupération : les documents pertinents ont-ils été identifiés ?
- La fidélité de la génération : la réponse est-elle fidèle aux informations récupérées ?
- La pertinence de la réponse : répond-elle effectivement à la question posée ?
- L'absence d'hallucinations : le modèle n'a-t-il pas inventé d'informations ?
RAGAS répond à ces défis en proposant un ensemble de métriques spécialisées, chacune ciblant un aspect particulier du pipeline RAG. L'évaluation n'est plus une note unique et opaque, mais un tableau de bord multidimensionnel permettant d'identifier précisément où se situent les faiblesses du système.
| Approche d'évaluation | Avantages | Inconvénients |
|---|---|---|
| Métriques lexicales (BLEU, ROUGE) | Rapides, déterministes | Insensibles à la sémantique |
| Évaluation humaine | Haute qualité | Coûteuse, non scalable |
| LLM as a Judge (RAGAS) | Scalable, sémantiquement riche | Dépend du modèle juge |
| Métriques d'embedding | Capture la similarité | Moins interprétable |
Les métriques clés de RAGAS
RAGAS propose un ensemble de métriques complémentaires qui, combinées, offrent une vision complète de la performance d'un système RAG. Chaque métrique évalue un aspect spécifique du pipeline et retourne un score entre 0 et 1.
Faithfulness : la fidélité aux sources
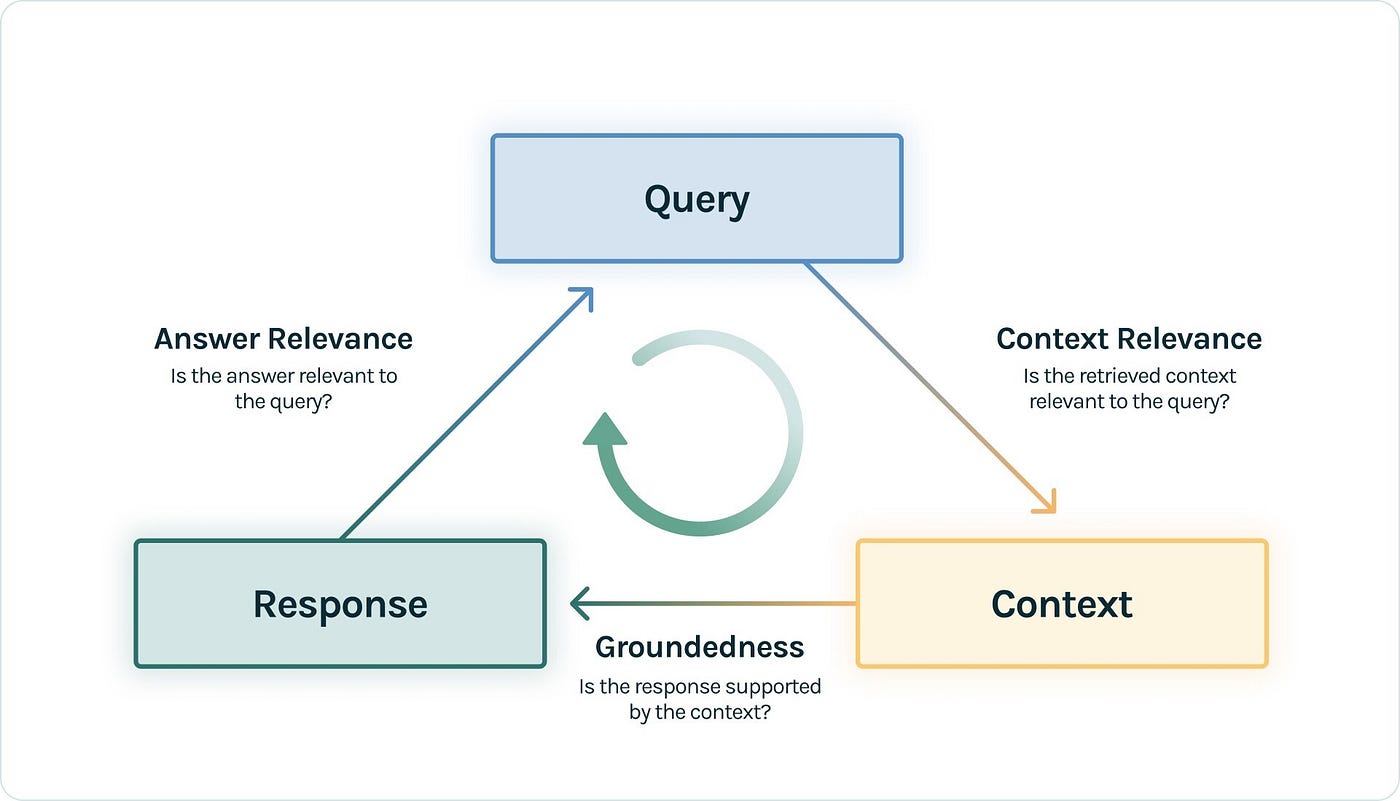
La métrique Faithfulness mesure si la réponse générée est fidèle aux documents récupérés. En d'autres termes, elle détecte les hallucinations en vérifiant que chaque affirmation de la réponse peut être justifiée par le contexte fourni. Un score élevé indique que le modèle n'invente pas d'informations et s'appuie strictement sur les sources disponibles.
Cette métrique est cruciale pour les applications où la fiabilité est primordiale : documentation technique, assistance juridique, ou tout domaine où une information erronée peut avoir des conséquences importantes.
Answer Relevancy : la pertinence de la réponse
Answer Relevancy évalue si la réponse générée répond effectivement à la question posée. Une réponse peut être parfaitement correcte et fidèle aux sources tout en étant hors sujet. Cette métrique identifie ces situations en analysant l'alignement entre la question et la réponse.
Context Precision et Context Recall
Ces deux métriques évaluent la qualité de l'étape de récupération :
- Context Precision : parmi les documents récupérés, quelle proportion est réellement pertinente ? Un score bas indique que le retriever ramène trop de bruit.
- Context Recall : parmi les informations nécessaires pour répondre, quelle proportion a été récupérée ? Un score bas suggère que des documents pertinents sont manqués.
L'équilibre entre ces deux métriques guide les optimisations du système de recherche : ajustement du nombre de documents récupérés, amélioration des embeddings, ou affinement de la stratégie de chunking.
À découvrir : notre formation LLM Engineering
LLM as a Judge : le principe au cœur de RAGAS
Le fonctionnement de RAGAS repose sur le paradigme LLM as a Judge, où un modèle de langage évalue les sorties d'un autre système. Cette approche, qui peut sembler circulaire au premier abord, s'est révélée remarquablement efficace pour capturer des nuances que les métriques automatiques traditionnelles ne peuvent saisir.
Concrètement, RAGAS utilise un LLM (le "juge") pour analyser chaque composant du pipeline :
- Pour la Faithfulness, le juge décompose la réponse en affirmations individuelles et vérifie si chacune peut être déduite du contexte
- Pour l'Answer Relevancy, il génère des questions hypothétiques à partir de la réponse et mesure leur similarité avec la question originale
- Pour les métriques de contexte, il évalue la pertinence de chaque document récupéré par rapport à la question
La flexibilité de RAGAS permet d'utiliser différents LLM comme juges selon vos contraintes. Pour les équipes soucieuses de confidentialité ou de coûts, l'intégration avec Ollama permet d'exécuter l'évaluation entièrement en local. Pour ceux privilégiant la qualité d'évaluation, les API d'OpenAI ou Anthropic offrent des modèles juges particulièrement performants.
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_precision
from langchain_openai import ChatOpenAI
# Configuration avec OpenAI comme juge
llm = ChatOpenAI(model="gpt-4o")
# Évaluation d'un dataset
results = evaluate(
dataset=eval_dataset,
metrics=[faithfulness, answer_relevancy, context_precision],
llm=llm,
)
print(results)
python
Pour une configuration locale avec Ollama :
from langchain_community.llms import Ollama
from ragas import evaluate
# Utilisation d'un modèle local comme juge
llm = Ollama(model="llama3.1:8b")
results = evaluate(
dataset=eval_dataset,
metrics=[faithfulness, answer_relevancy],
llm=llm,
)
python
| Modèle juge | Avantages | Cas d'usage |
|---|---|---|
| GPT-4o / Claude | Haute qualité d'évaluation | Production, benchmarks critiques |
| GPT-4o-mini | Bon compromis coût/qualité | Évaluation régulière |
| Llama 3.1 (Ollama) | Gratuit, données privées | Développement, données sensibles |
| Mistral | Performant, européen | Conformité RGPD |
Intégration pratique dans vos projets
L'adoption de RAGAS dans un projet existant suit généralement une progression en trois étapes : la préparation des données d'évaluation, la configuration des métriques, et l'intégration dans le workflow de développement.
Préparation du dataset d'évaluation
RAGAS attend un format de données spécifique contenant les éléments du pipeline RAG :
from datasets import Dataset
eval_data = {
"question": [
"Quels sont les avantages du fine-tuning de LLM ?",
"Comment fonctionne la technique RAG ?"
],
"answer": [
"Le fine-tuning permet d'adapter un modèle à un domaine spécifique...",
"RAG combine la récupération de documents avec la génération..."
],
"contexts": [
["Document 1 sur le fine-tuning...", "Document 2..."],
["Document sur RAG...", "Autre document..."]
],
"ground_truth": [
"Le fine-tuning améliore les performances sur des tâches spécifiques...",
"RAG utilise un retriever pour enrichir le contexte du LLM..."
]
}
eval_dataset = Dataset.from_dict(eval_data)
python
Pour les systèmes agentiques, RAGAS propose également des métriques adaptées qui évaluent la qualité des décisions prises par l'agent et la pertinence des outils utilisés.
Automatisation de l'évaluation
L'intérêt majeur de RAGAS réside dans sa capacité à s'intégrer dans des pipelines d'intégration continue. Plutôt que d'évaluer manuellement après chaque modification, vous pouvez automatiser le processus :
def evaluate_rag_pipeline(pipeline, test_questions):
"""Évalue un pipeline RAG et retourne les métriques."""
# Génération des réponses
results = []
for question in test_questions:
response = pipeline.query(question)
results.append({
"question": question,
"answer": response.answer,
"contexts": response.source_documents
})
# Conversion en dataset RAGAS
eval_dataset = Dataset.from_list(results)
# Évaluation
scores = evaluate(
dataset=eval_dataset,
metrics=[faithfulness, answer_relevancy, context_precision],
)
return scores
# Utilisation dans un test automatisé
def test_rag_quality():
scores = evaluate_rag_pipeline(my_pipeline, test_questions)
assert scores["faithfulness"] > 0.8, "Faithfulness trop basse"
assert scores["answer_relevancy"] > 0.75, "Relevancy insuffisante"
python
Cette approche permet de détecter les régressions dès qu'elles surviennent et de maintenir un niveau de qualité constant au fil des évolutions du système.
Conclusion
RAGAS s'impose comme un outil incontournable pour quiconque développe des systèmes d'IA générative en production. En fournissant des métriques spécialisées et une méthodologie d'évaluation robuste, il comble un vide que les approches traditionnelles ne pouvaient adresser.
L'approche LLM as a Judge, bien que nécessitant une certaine vigilance quant au choix du modèle évaluateur, offre une scalabilité et une pertinence que l'évaluation humaine ne peut égaler. La flexibilité de RAGAS, compatible aussi bien avec des API cloud qu'avec des modèles locaux via Ollama, permet de l'adapter à toutes les contraintes : confidentialité des données, maîtrise des coûts, ou exigences de qualité maximale.
Pour les équipes qui construisent des RAG, des assistants conversationnels ou des agents autonomes, intégrer RAGAS dans le workflow de développement n'est plus une option mais une nécessité. La capacité à mesurer objectivement la qualité des réponses, à identifier les faiblesses du pipeline et à suivre les améliorations au fil du temps constitue un avantage compétitif majeur dans un domaine où la fiabilité des systèmes d'IA devient un critère de différenciation essentiel.


