RAG vs Agents : le comparatif ultime
L'émergence des applications d'intelligence artificielle en entreprise a popularisé deux approches distinctes pour exploiter la puissance des LLM : le RAG (Retrieval-Augmented Generation) et les agents IA. Si ces deux paradigmes permettent d'enrichir les capacités des modèles de langage au-delà de leurs connaissances intrinsèques, ils reposent sur des philosophies fondamentalement différentes qui conditionnent leurs cas d'usage respectifs.

L'émergence des applications d'intelligence artificielle en entreprise a popularisé deux approches distinctes pour exploiter la puissance des LLM : le RAG (Retrieval-Augmented Generation) et les agents IA. Si ces deux paradigmes permettent d'enrichir les capacités des modèles de langage au-delà de leurs connaissances intrinsèques, ils reposent sur des philosophies fondamentalement différentes qui conditionnent leurs cas d'usage respectifs.
Le RAG s'est imposé comme la solution de référence pour connecter un LLM à des sources de données externes, permettant de générer des réponses ancrées dans une base documentaire actualisée. Les agents IA, quant à eux, introduisent une dimension d'autonomie où le système peut raisonner, planifier et exécuter des actions de manière itérative pour atteindre un objectif. Ces deux approches ne sont pas mutuellement exclusives — l'Agentic RAG en est la preuve — mais comprendre leurs différences fondamentales est essentiel pour choisir l'architecture adaptée à chaque problème.
Dans cet article, nous allons décortiquer les mécanismes qui distinguent le pipeline linéaire du RAG de la boucle décisionnelle des agents, explorer les capacités de planification et de sélection dynamique d'outils propres aux systèmes agentiques, et identifier les contextes où chaque approche excelle.
Pipeline linéaire vs boucle décisionnelle
La différence la plus structurante entre RAG et agents réside dans leur mode d'exécution. Le RAG suit un pipeline linéaire prédéterminé, tandis que les agents opèrent dans une boucle décisionnelle qui s'adapte dynamiquement aux résultats obtenus.
Le RAG : une séquence fixe et prévisible
Le RAG classique s'articule autour de trois étapes immuables qui s'enchaînent systématiquement dans le même ordre :
- Indexation : les documents sont découpés en chunks, vectorisés via un modèle d'embedding, puis stockés dans une base vectorielle
- Récupération : la requête utilisateur est transformée en vecteur et une recherche de similarité identifie les chunks les plus pertinents
- Génération : les chunks récupérés sont injectés dans le contexte du LLM qui produit la réponse finale
Cette architecture présente l'avantage de la prévisibilité. Chaque requête emprunte exactement le même chemin, ce qui facilite le debugging, l'optimisation et la maîtrise des coûts. Le nombre d'appels au LLM est fixe (généralement un seul pour la génération), et le temps de réponse reste relativement constant.

Cependant, cette rigidité constitue également sa principale limitation. Si la recherche initiale ne retourne pas les documents pertinents — parce que la requête était mal formulée ou que l'information est dispersée sur plusieurs sources — le RAG ne peut pas s'adapter. Il génère sa réponse avec les documents récupérés, qu'ils soient pertinents ou non, sans possibilité de reformuler sa recherche ou d'explorer d'autres pistes.
L'agent : une boucle itérative et adaptative
L'architecture agentique fonctionne selon un paradigme radicalement différent. Un agent basé sur le pattern ReAct alterne entre réflexion et action dans une boucle qui se répète jusqu'à atteindre l'objectif :
Requête: "Quel est le chiffre d'affaires de notre principal concurrent l'année dernière ?"
Thought: Je dois d'abord identifier qui est le principal concurrent de l'entreprise.
Action: search_internal_docs(query="principal concurrent analyse concurrentielle")
Observation: Document trouvé mentionnant TechCorp comme principal concurrent.
Thought: Maintenant je dois trouver le CA de TechCorp pour l'année dernière.
Action: search_financial_data(query="TechCorp chiffre d'affaires 2024")
Observation: Aucun résultat dans la base interne.
Thought: L'information n'est pas disponible en interne, je vais chercher sur le web.
Action: web_search(query="TechCorp revenue 2024 annual report")
Observation: Rapport annuel trouvé indiquant un CA de 2.3 milliards d'euros.
Thought: J'ai maintenant toutes les informations pour répondre.
Response: Le principal concurrent, TechCorp, a réalisé un chiffre d'affaires de 2.3 milliards d'euros en 2024.
plaintext
Cette capacité d'adaptation permet à l'agent de surmonter les échecs intermédiaires et de construire progressivement sa compréhension du problème. Là où le RAG aurait échoué à la première recherche infructueuse, l'agent a pu pivoter vers une source alternative.
| Caractéristique | RAG classique | Agent IA |
|---|---|---|
| Mode d'exécution | Pipeline linéaire fixe | Boucle itérative adaptative |
| Nombre d'étapes | Prédéterminé (3 étapes) | Variable selon la tâche |
| Gestion des échecs | Aucune adaptation | Reformulation et alternatives |
| Prévisibilité | Élevée | Variable |
| Coût par requête | Fixe et maîtrisé | Variable selon la complexité |
| Latence | Constante | Variable |
Cette différence fondamentale d'architecture a des implications directes sur les cas d'usage appropriés pour chaque approche. Le RAG excelle pour les questions simples et directes où une seule recherche suffit généralement à trouver l'information. Les agents deviennent indispensables dès que la résolution du problème nécessite plusieurs étapes, des sources multiples, ou une adaptation en fonction des résultats intermédiaires.
Planification et sélection dynamique d'outils
Au-delà de la boucle d'exécution, les agents IA se distinguent par deux capacités absentes du RAG classique : la planification et la sélection dynamique d'outils. Ces mécanismes permettent aux agents de traiter des problèmes d'une complexité inaccessible aux pipelines linéaires.
La planification comme avantage stratégique
Les architectures agentiques avancées, comme le pattern Plan-and-Execute, intègrent une phase explicite de planification où le LLM décompose l'objectif en sous-tâches avant de commencer l'exécution. Cette approche présente plusieurs avantages :
- Vision globale : l'agent identifie l'ensemble des étapes nécessaires avant de se lancer, évitant les impasses
- Parallélisation : les sous-tâches indépendantes peuvent être exécutées simultanément
- Priorisation : l'agent peut ordonner les tâches de manière optimale, traitant d'abord celles qui conditionnent les autres
- Résilience : si une sous-tâche échoue, le plan peut être révisé sans repartir de zéro
Le RAG, par construction, ne possède pas cette capacité de projection. Il traite chaque requête de manière isolée, sans considération pour les dépendances ou les optimisations possibles. Pour une question comme "Compare les performances financières de nos trois principaux concurrents", le RAG tenterait une unique recherche là où un agent planifierait trois recherches distinctes puis une phase de synthèse comparative.
Sélection dynamique d'outils
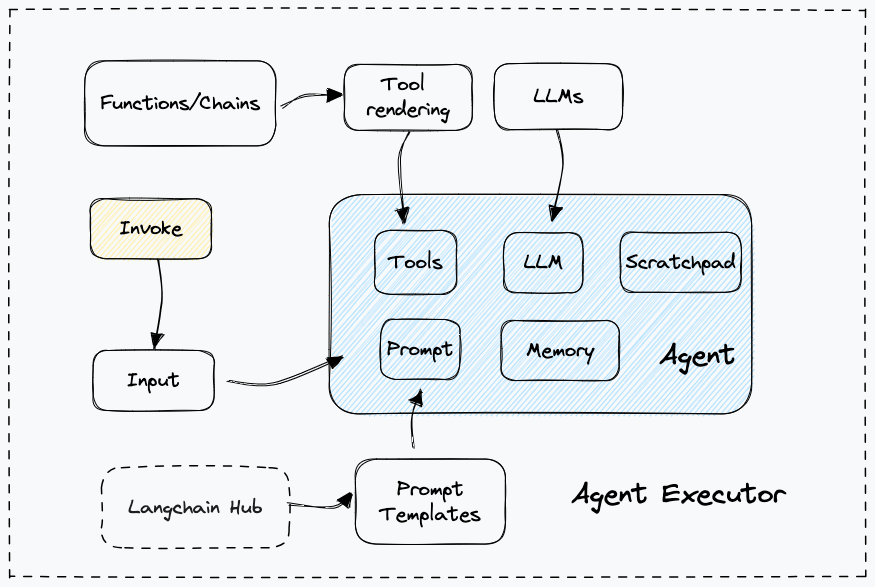
La sélection dynamique d'outils constitue l'autre différenciateur majeur des architectures agentiques. Un agent dispose généralement d'un arsenal d'outils parmi lesquels il choisit à chaque étape celui qui semble le plus approprié :
- Recherche vectorielle dans une base documentaire
- Recherche par mots-clés pour des termes précis
- Requêtes SQL sur des bases de données structurées
- Appels API vers des systèmes externes
- Exécution de code pour des calculs complexes
- Recherche web pour des informations publiques
Cette flexibilité permet à l'agent de s'adapter au type de problème rencontré. Face à une question nécessitant un calcul, il invoquera un outil d'exécution de code. Face à une demande de données temps réel, il privilégiera une API. Face à une recherche documentaire, il utilisera la base vectorielle.
# Configuration d'un agent avec multiple outils
from langchain.agents import AgentExecutor, create_openai_tools_agent
tools = [
Tool(name="vector_search", description="Recherche sémantique dans la documentation", func=search_docs),
Tool(name="sql_query", description="Requête SQL sur la base de données clients", func=execute_sql),
Tool(name="calculator", description="Effectue des calculs mathématiques", func=calculate),
Tool(name="web_search", description="Recherche d'informations sur internet", func=web_search),
Tool(name="send_email", description="Envoie un email à un destinataire", func=send_email)
]
agent = create_openai_tools_agent(llm, tools, prompt)
executor = AgentExecutor(agent=agent, tools=tools)
python
Le RAG, en comparaison, est limité à un seul mode d'interaction avec les données : la recherche vectorielle suivie de la génération. Cette spécialisation le rend très efficace pour son cas d'usage nominal, mais incapable de traiter des problèmes nécessitant d'autres types d'opérations.
À découvrir : notre formation Agentic AI
Cas d'usage : quand choisir RAG ou agent ?
Le choix entre RAG et agent ne relève pas d'une supériorité absolue de l'un sur l'autre, mais d'une adéquation au contexte. Chaque approche excelle dans des situations spécifiques qu'il convient d'identifier.
Quand le RAG est le choix optimal
Le RAG s'impose comme la solution la plus pertinente dans plusieurs contextes :
Questions-réponses sur une base documentaire : pour un système de FAQ intelligent, un assistant de support technique ou un moteur de recherche documentaire, le RAG offre le meilleur rapport qualité/coût. La requête de l'utilisateur correspond généralement à un besoin d'information ponctuel que la base documentaire peut satisfaire en une seule recherche.
Contraintes de latence strictes : lorsque le temps de réponse est critique (chatbot grand public, assistant temps réel), la prévisibilité du RAG garantit une latence constante et optimisable. Les agents, avec leur nombre variable d'itérations, ne peuvent pas offrir cette garantie.
Budget LLM contraint : le coût d'un appel RAG est fixe et prévisible, tandis qu'un agent peut multiplier les appels au LLM selon la complexité de la tâche. Pour des déploiements à grande échelle avec des contraintes budgétaires serrées, le RAG reste plus économique.
Besoin d'explicabilité simple : le pipeline RAG est facilement auditable — on peut inspecter les documents récupérés et comprendre pourquoi une réponse a été générée. Les trajectoires d'un agent sont plus complexes à analyser.
Quand les agents deviennent indispensables
Les agents IA prennent l'avantage dès que la complexité de la tâche dépasse les capacités d'un pipeline linéaire :
Tâches multi-étapes : toute mission nécessitant une séquence d'actions — rechercher, analyser, transformer, agir — requiert la boucle itérative des agents. Réserver un vol en tenant compte des contraintes de calendrier, comparer des offres puis effectuer la réservation dépasse fondamentalement les capacités du RAG.
Sources de données multiples et hétérogènes : lorsque l'information est dispersée entre plusieurs systèmes (base documentaire, CRM, API externes, web), seul un agent peut naviguer intelligemment entre ces sources pour construire une réponse complète.
Requêtes ambiguës ou complexes : face à une question mal formulée ou nécessitant une interprétation, l'agent peut clarifier, reformuler, et itérer jusqu'à obtenir un résultat satisfaisant. Le RAG subit passivement la qualité de la requête initiale.
Actions sur des systèmes externes : dès que le système doit agir sur le monde (envoyer un email, créer un ticket, mettre à jour une base de données), les agents sont indispensables. Le RAG est purement consultatif.
| Critère de choix | Privilégier RAG | Privilégier Agent |
|---|---|---|
| Complexité de la tâche | Questions simples et directes | Tâches multi-étapes |
| Sources de données | Base unique et homogène | Sources multiples et hétérogènes |
| Latence requise | Temps réel critique | Temps de réflexion acceptable |
| Budget | Contraint | Flexible |
| Type d'interaction | Consultation d'information | Consultation et action |
| Prévisibilité | Comportement déterministe requis | Adaptabilité privilégiée |
L'hybridation : le meilleur des deux mondes
Il est important de noter que RAG et agents ne sont pas mutuellement exclusifs. L'Agentic RAG combine les deux approches en dotant un système RAG de capacités agentiques : le LLM peut décider de reformuler sa recherche, d'explorer plusieurs collections, ou de combiner les résultats de multiples requêtes.
De même, un agent peut utiliser le RAG comme l'un de ses outils. Dans une architecture de superviseur d'agents, un agent spécialisé dans la recherche documentaire peut implémenter un pipeline RAG optimisé, tandis que d'autres agents gèrent les interactions avec les API ou l'exécution de code.
À lire : découvrez notre formation Agentic AI
Conclusion
RAG et agents IA représentent deux philosophies complémentaires pour augmenter les capacités des LLM. Le RAG offre un pipeline linéaire efficace, prévisible et économique pour connecter un modèle à une base de connaissances. Les agents introduisent une boucle décisionnelle adaptative, des capacités de planification et une sélection dynamique d'outils qui permettent de traiter des problèmes d'une complexité supérieure.
Le choix entre ces deux approches dépend fondamentalement de la nature du problème à résoudre. Pour des questions-réponses simples sur une base documentaire avec des contraintes de latence et de coût, le RAG reste la solution optimale. Dès que la tâche implique plusieurs étapes, des sources hétérogènes, ou des actions sur des systèmes externes, les agents deviennent indispensables.
La tendance actuelle vers l'hybridation suggère que l'opposition RAG vs agents est en partie artificielle. Les architectures les plus sophistiquées combinent les avantages des deux approches, utilisant le RAG comme composant optimisé au sein de systèmes agentiques plus larges. Maîtriser ces deux paradigmes et savoir les articuler constitue désormais une compétence essentielle pour concevoir des applications d'Agentic AI performantes et adaptées aux besoins réels des entreprises.


