Les Transformers, incontournables du Deep Learning
Les transformers, ou les modèles séquence à séquence, sont des modèles de Deep Learning qui appartiennent à une classe spéciale d’architectures de réseaux de neurones récurrents. Ils sont devenus des modèles de choix pour les Data Scientists lorsqu'ils travaillent sur du texte, remplaçant les anciens RNNs tels que le LSTM ou le GRU.

Pour faire de la traduction en temps réel, du Text-to-Speech, ou encore du Speech-to-Text, jusqu'à ces dernières années, l'état de l'art était les RNNs, nourris avec des couches de Word Embeddings, et parfois quelques couches de convolution sur les séquences d'entrée pour en extraire des caractéristiques. Néanmoins, 2020 était certainement l’année des transformers ! Initialement développé pour le langage naturel, ils sont maintenant utilisés pour des tâches de vision par machine. Les transformers, ou les modèles séquence à séquence, sont des modèles de Deep Learning qui appartiennent à une classe spéciale d’architectures de réseaux de neurones récurrents. Ils sont devenus des modèles de choix pour les Data Scientists lorsqu'ils travaillent sur du texte (NLP), remplaçant les anciens RNNs tels que le LSTM.
Dans cet article, nous allons détailler le principe du traitement du langage naturel en utilisant des RNNs, le fonctionnement et l'architecture des transformers, leurs avantages et les cas d'usage de nos jours.
Traitement du texte (NLP) en utilisant des RNNs
Les RNNs sont idéales pour résoudre des problèmes où la séquence est plus importante que les éléments individuels eux-mêmes. On les utilise généralement pour traiter des données séquentielles, qui peuvent être des données chronologiques ou des données textuelles de n’importe quel format.
Les séquences sont des objets dont chaque élément possède un ordre, une position, une inscription dans le temps. Par exemple, dans une phrase, chaque mot vient dans un certain ordre et il est prononcé sur un intervalle de temps distinct de celui des autres.
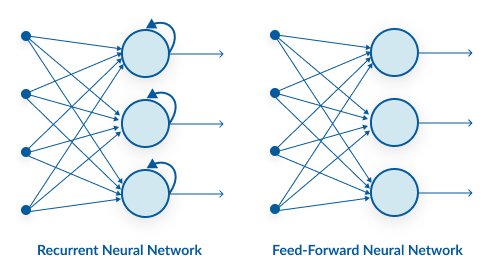
En raison de leur mémoire interne, les RNNs peuvent se souvenir de choses importantes au sujet de l’entrée qu’ils ont reçue, ce qui leur permet d’être très précis dans la prédiction de ce qui vient après. Dans un réseau de neurones standard, l’information ne se déplace que dans une direction, de la couche d’entrée, en passant par les couches cachées, à la couche de sortie. L’information circule directement dans le réseau et ne touche jamais un nœud deux fois.
À lire aussi : découvrez notre formation MLOps
Dans un RNN, l’information passe par une boucle. Lorsqu’il prend une décision, il tient compte des données actuelles et de ce qu’il a appris des données reçues précédemment.
Imaginons que nous avons un réseau de neurones classique et donnons-lui le mot Bonjour comme entrée et il traite le mot caractère par caractère. Au moment où il atteint le caractère j, il a déjà oublié b, o et n, ce qui rend presque impossible pour ce type de réseau neuronal de prédire quelle lettre viendrait ensuite.
Un RNN, cependant, est capable de se souvenir de ces caractères en raison de sa mémoire interne. Il produit la sortie, la copie et la boucle dans le réseau.
Pour obtenir plus de couches de calcul pour être en mesure de résoudre ou d’estimer des tâches plus complexes, la sortie du RNN pourrait être alimentée dans un autre RNN, ou n’importe quel nombre de couches de RNNs.
À mesure que le nombre de couches augmente, les données précédentes sont perdues. C'est le problème de la disparition du gradient. Pour résoudre ce problème, Gated Recurrent Unit (GRU) ou Long Term Short Term Memory (LSTM) peuvent être utilisés.
Les LSTMs par exemple, sont une variante des RNNs. Ils sont capables de se souvenir des entrées sur une longue période de temps. C’est parce qu'ils contiennent des informations dans une mémoire, un peu comme la mémoire d’un ordinateur.
Le LSTM peut lire, écrire et supprimer des informations de sa mémoire. Dans cette mémoire, on décide à chaque fois de stocker ou de supprimer des informations en fonction de l’importance qu’elle accorde à l’information. L’attribution de l’importance se fait par des poids, qui sont également appris par l’algorithme.

Cela signifie simplement qu’il apprend au fil du temps ce qui est important et ce qui ne l’est pas. C'est ce qu'on appelle le mécanisme d'attention. En appliquant ce dernier, on est en train de regarder une séquence d’entrée et décider à chaque étape quelles parties de la séquence sont importantes. Ce genre de modèle à mémoire longue est connu pour être très efficace pour le traitement du langage naturel, la classification et la traduction du texte.
Les réseaux récurrents étaient, jusqu’à présent, l’un des meilleurs moyens de capturer et traiter les dépendances dans les séquences. Récemment, une nouvelle architecture appelée Transformer ou transformer a été introduite. Elle utilise le mécanisme d’attention qu'on vient de voir tout comme LSTM. C'est une architecture pour transformer une séquence en une autre à l’aide de deux parties (encodeur et décodeur), mais elle diffère des autres modèles séquentiels décrits existants, car elle n’implique pas de réseaux récurrents.
Mais comment est-ce que ça marche réellement et comment peut-on traiter de langues séquences de texte sans RNNs ?
Apprentissage séquence à séquence et architecture des transformers
Les réseaux de neurones transformers sont des modèles Sequence-to-Sequence (Seq2seq), c'est-à-dire qu'ils sont des réseaux qui transforment une séquence donnée d’éléments, comme la séquence de mots dans une phrase, en une autre séquence.
Ils ont pour but de prévoir une séquence de longueur variable en fonction d’une autre aussi de longueur variable. Le principe est de tenir compte du contexte des observations à prévoir (mécanisme d’attention). Ce type de modèle est particulièrement performant en traduction, où la séquence de mots d’une langue est transformée en une séquence de mots différents dans une autre langue.
Les modèles Seq2seq
Avant l'apparition des transformers, les modèles Seq2seq faisaient appel à des LSTM ou des GRU. L'architecture de ces derniers se compose de deux parties :

- Un encodeur : qui crée une représentation vectorielle d’une séquence de mots. En effet, chaque token en entrée (ici des mots) est transformé en vecteur (Word Embedding) de taille identique. Ensuite, les RNNs vont le transformer en un vecteur d'état (ou un vecteur de contexte). Le vecteur contexte contient toutes les informations que l’encodeur a pu détecter à partir de l’entrée. La sortie de l'encodeur est alors mise en entrée d’un décodeur (un autre ensemble de RNNs).
- Un décodeur : qui retourne une séquence de mots à partir d’une représentation vectorielle. Le vecteur de contexte de la cellule finale de l’encodeur est entré dans la première cellule du réseau de décodeurs (un RNN). En utilisant ces états initiaux, le décodeur commence à générer la séquence de sortie et ces sorties sont également prises en considération pour les sorties futures, c'est-à-dire que chaque RNN prend comme entrée la sortie du RNN qui le précède. De cette façon, la dépendance des mots est prise en compte et la notion de mémoire des RNNs est respectée.
L’idée du transformer est de conserver l’interdépendance des mots d’une séquence en n’utilisant pas de réseau récurrent, mais seulement le mécanisme d’attention qui est au centre de son architecture.
Architecture des transformers
Les transformers héritent l'architecture encodeur-décodeur des modèles Seq2seq. Mais cette fois sans faire appel à des RNNs. En effet, il ne 'agit d'un seul encodeur et un seul décodeur, mais plutôt de séries.
En effet, la partie d'encodage se compose d'une pile d’encodeurs (le choix du nombre six ici est arbitraire, on peut certainement expérimenter avec d’autres arrangements). La partie décodeur de décodage est une pile de décodeurs du même nombre.
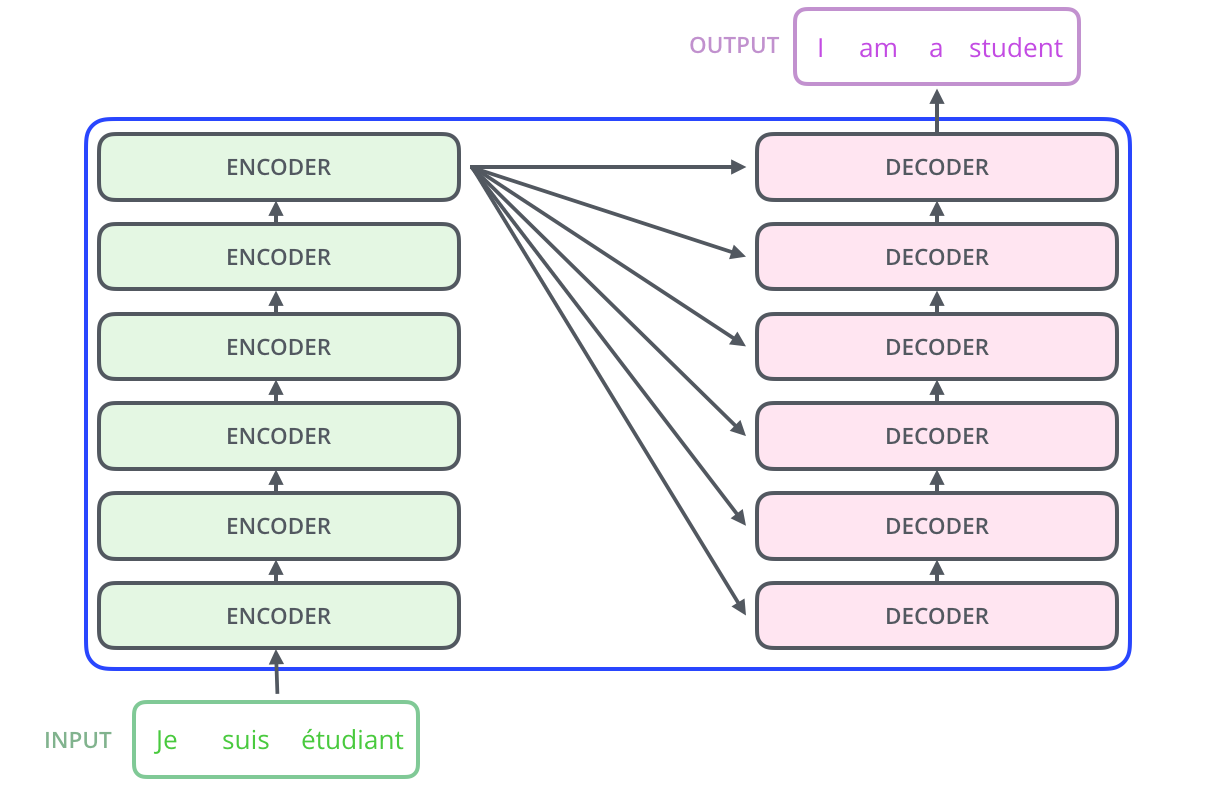
Chaque encodeur se compose de deux parties :
- Une couche dite de self-attention : une couche qui aide l’encodeur à regarder d’autres mots dans la phrase d’entrée alors qu’il encode un mot spécifique. On va prendre ce mécanisme en détaille juste après.
- Une couche de neurones à propagation avant (ou Feed-forward Neural Network): un réseau de neurones classique pour faire circuler l'information directement dans le modèle.
Chaque décodeur représente une couche supplémentaire à ceux des encodeurs. C'est la partie Encoder-Decoder attention. Elle est située entre la couche self-attention et la couche feed forward. Elle permet au décodeur de réaliser le mécanisme d’attention entre la séquence d’entrée (encodée) et la séquence de sortie (en train d’être décodée).
Mécanisme du self-attention
Comme nous l'avons déjà dit, le mécanisme d'attention permet de décider, à chaque étape du fonctionnement du modèle, quelles parties de la séquence A sont importantes lorsqu'il est en train de traiter la séquence B (Dans le cas de ce mécanisme appliqué à la traduction, la séquence A est la phrase à traduire, la séquence B et la phrase traduite). C'est dire que l'on calcule l'importance des mots de la séquence de sortie en se référant à la séquence d'entrée.
À lire aussi : découvrez notre formation MLOps
Par contre, pour le mécanisme de self-attention, on applique tout simplement le mécanisme d’attention à une seule séquence. C'est-à-dire l'importance de chaque mot ici dépend des autres mots de la même phrase.
Prenons un exemple pour mieux comprendre.
Le nageur n'a pas traverse le lac parce qu'il était fatigue.
Ici, le il fait référence au nageur, le processus de self-attention aura donc pour objectif de détecter le lien entre le nageur et il.
Le nageur n'a pas traverse le lac parce qu'il était trop large.
Ici, le il fait référence au lac, le processus de self-attention aura ainsi pour objectif de détecter le lien entre le lac et il. Ce mécanisme représente l'élément central de d'architecture des transformers. Son rôle est de faire garder l’interdépendance des mots dans la représentation des séquences.
Quand et pourquoi utiliser des transformers ?
On utilise principalement un transformer pour la traduction et la génération de texte. Il est par exemple utilisé par les traducteurs en ligne, les services Text-to-Speech, ou du Speech-to-Text pour traiter de manière automatique et en temps réel du langage naturel.
Contrairement aux anciens modèles utilisant des RNN, les modèles modernes basés sur des Transformers ont la capacité de lier les mots entre eux (notion du self-attention) ce qui leur permet d’obtenir des phrases bien plus proches du langage écrit ou parlé, et de donner le bon sens à un mot surtout dans les cas ou ce dernier peu en avoir plusieurs.
Les Transformers peuvent également être utilisés dans d’autres domaines comme le traitement d’images, analyse de séquence biologique et compréhension de vidéo.
On peut citer en guise d'exemple quelques modèles de Deep Learning se basant sur des transformers :
- BERT (Bidirectional Encoder Representations from Transformers) introduit en 2019 par Google.
- GPT-2 et GPT-3 (Generative Pre-trained Transformer) introduit par OpenAI.
En bref, les transformers sont des modèles d’apprentissage conçus pour gérer des données séquentielles en utilisant des mécanismes d’attention. Ils sont très puissants et très utilisés par les Data Scientists pour les tâches complexe de NLP, bien qu'ils peuvent parfois être v et de temps d'entrainement.


