Data Contracts : fiabiliser les échanges entre équipes
Dans un écosystème data de plus en plus distribué, où les données circulent entre de multiples équipes, systèmes et applications, une problématique récurrente émerge : comment garantir que les données échangées respectent les attentes de ceux qui les consomment ? Entre les équipes backend qui produisent des données, les Data Engineers qui les transforment et les Data Analysts qui les exploitent, les incompréhensions et les incidents liés à des changements non anticipés sont monnaie courante.

Dans un écosystème data de plus en plus distribué, où les données circulent entre de multiples équipes, systèmes et applications, une problématique récurrente émerge : comment garantir que les données échangées respectent les attentes de ceux qui les consomment ? Entre les équipes backend qui produisent des données, les Data Engineers qui les transforment et les Data Analysts qui les exploitent, les incompréhensions et les incidents liés à des changements non anticipés sont monnaie courante.
C'est pour répondre à ce besoin de fiabilisation des échanges qu'a émergé le concept de Data Contracts. Inspirés des contrats d'API bien connus dans le monde du développement logiciel, les Data Contracts formalisent les engagements entre producteurs et consommateurs de données. En définissant explicitement la structure, la qualité et les règles d'évolution des données échangées, ils permettent de transformer des flux de données fragiles en interfaces stables et prévisibles, réduisant drastiquement les incidents en production et les frictions entre équipes.
Qu'est-ce qu'un Data Contract ?
Un Data Contract est un accord formel entre un producteur de données et ses consommateurs qui définit précisément ce que contient un dataset, comment il est structuré, et quelles garanties sont offertes sur sa qualité et sa disponibilité. Contrairement à une simple documentation descriptive, un Data Contract a vocation à être versionné, testé et appliqué automatiquement dans les pipelines de données.
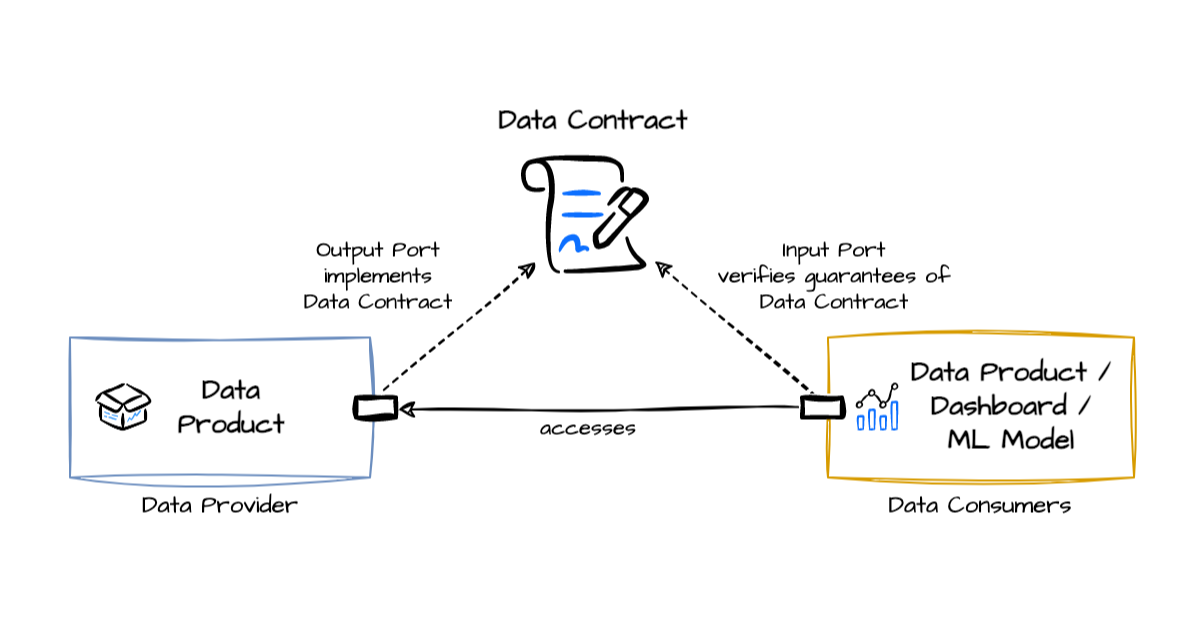
Concrètement, un Data Contract spécifie plusieurs éléments essentiels :
-
Le schéma des données : les colonnes ou champs présents, leurs types (string, integer, timestamp), leur caractère obligatoire ou optionnel, et les contraintes associées (unicité, valeurs autorisées, formats).
-
Les règles de qualité : les invariants que les données doivent respecter (pas de valeurs nulles sur certains champs, cohérence entre colonnes, plages de valeurs acceptables).
-
Les métadonnées opérationnelles : la fréquence de mise à jour, le propriétaire du dataset, les SLAs de disponibilité, et les canaux de communication en cas d'incident.
-
Les règles d'évolution : comment le schéma peut évoluer dans le temps (ajout de colonnes autorisé, suppression interdite sans préavis, processus de dépréciation).
Cette formalisation transforme ce qui était auparavant un accord implicite (ou inexistant) en un engagement explicite et vérifiable. Lorsqu'une équipe backend modifie la structure d'une table sans respecter le contrat, les tests échouent avant que le changement n'atteigne la production, évitant ainsi des heures de debugging pour les équipes en aval.
L'analogie avec les contrats d'API est particulièrement éclairante. De la même manière qu'une API REST définit ses endpoints, ses paramètres et ses codes de retour, un Data Contract définit la "surface" d'un dataset. Les consommateurs peuvent s'appuyer sur cette interface stable sans craindre qu'un changement côté producteur ne casse leurs pipelines ou leurs analyses.
Pourquoi les Data Contracts sont devenus essentiels
L'adoption croissante des Data Contracts répond à des douleurs bien réelles que connaissent les équipes data, particulièrement dans les organisations où les données sont produites par de nombreuses équipes différentes.
Le premier problème majeur est celui des changements de schéma non anticipés. Une équipe produit ajoute un champ, en renomme un autre ou modifie un type de données pour répondre à ses propres besoins, sans réaliser que des dizaines de pipelines et tableaux de bord dépendent de cette structure. Le résultat : des jobs qui échouent en pleine nuit, des métriques faussées découvertes des jours plus tard, et des heures perdues à identifier l'origine du problème.
Le second enjeu concerne la qualité des données. Sans contrat explicite, les équipes consommatrices découvrent souvent les problèmes de qualité après coup : valeurs nulles inattendues, doublons, incohérences entre champs liés. Ces anomalies se propagent dans les transformations et finissent par impacter les décisions business basées sur des données erronées.
Enfin, les Data Contracts répondent à un besoin d'autonomie des équipes. Dans une organisation data mature, les producteurs de données ne peuvent pas connaître tous les usages faits de leurs datasets. Les contrats permettent de découpler les équipes : tant que le contrat est respecté, chaque partie peut évoluer indépendamment. Les producteurs peuvent optimiser leur implémentation interne, les consommateurs peuvent construire de nouveaux cas d'usage, sans coordination permanente.
| Problème | Sans Data Contract | Avec Data Contract |
|---|---|---|
| Changement de schéma | Découvert en production | Détecté avant déploiement |
| Anomalie de qualité | Propagée silencieusement | Bloquée à la source |
| Communication inter-équipes | Réunions fréquentes, Slack | Interface documentée et stable |
| Responsabilité | Floue, finger-pointing | Clairement définie |
Implémentation des Data Contracts
Mettre en place des Data Contracts dans une organisation nécessite à la fois des choix techniques et une évolution des pratiques de collaboration entre équipes.
Définition et format des contrats
Un Data Contract se matérialise généralement sous forme d'un fichier de configuration versionné (YAML, JSON ou format propriétaire) qui décrit l'ensemble des spécifications du dataset. Ce fichier est stocké dans un repository Git aux côtés du code qui produit ou transforme les données, permettant de tracer l'historique des évolutions et d'appliquer des processus de revue.
# Exemple simplifié de Data Contract
name: orders
version: 2.1.0
owner: team-ecommerce
description: Commandes validées par les clients
schema:
- name: order_id
type: string
required: true
unique: true
- name: customer_id
type: string
required: true
- name: total_amount
type: decimal
required: true
constraints:
minimum: 0
- name: created_at
type: timestamp
required: true
quality:
- rule: total_amount >= 0
- rule: created_at <= current_timestamp()
sla:
freshness: 1 hour
availability: 99.9%
yaml
Plusieurs outils et frameworks ont émergé pour faciliter cette implémentation. Soda permet de définir des checks de qualité qui peuvent servir de base aux contrats. Great Expectations offre des fonctionnalités similaires avec une approche programmatique en Python. Des solutions plus spécialisées comme Schemata ou les fonctionnalités natives de certains Data Catalogs (Atlan, DataHub) proposent des interfaces dédiées à la gestion des contrats.
Dans une architecture moderne utilisant dbt, les contrats peuvent être partiellement implémentés via les tests dbt et la documentation des modèles. Les tests de schéma (types, non-nullité, unicité) et les tests personnalisés permettent de valider que les données produites respectent les engagements pris.
Intégration dans les pipelines
Pour que les Data Contracts aient un impact réel, ils doivent être validés automatiquement à chaque exécution des pipelines. Cette validation peut intervenir à plusieurs moments :
-
À la production : avant qu'un producteur ne publie de nouvelles données, les tests du contrat vérifient que la structure et la qualité sont conformes. En cas d'échec, le pipeline s'arrête et alerte l'équipe responsable.
-
À la consommation : les consommateurs peuvent également valider que les données qu'ils reçoivent respectent le contrat attendu, servant de filet de sécurité supplémentaire.
-
En CI/CD : lors d'une modification du code de production, les changements de schéma sont comparés au contrat existant. Si une modification "breaking" est détectée (suppression de colonne, changement de type incompatible), le déploiement est bloqué.
Cette intégration dans les pipelines Airflow, Prefect ou autres orchestrateurs transforme les contrats d'un simple document en une barrière de qualité active qui empêche les régressions d'atteindre la production.
Gouvernance et évolution
Un aspect souvent sous-estimé des Data Contracts concerne leur cycle de vie et leur gouvernance. Un contrat n'est pas figé : les besoins évoluent, de nouveaux champs sont nécessaires, d'autres deviennent obsolètes. Il est essentiel de définir des règles claires pour gérer ces évolutions.
Une pratique courante consiste à distinguer les changements "backward compatible" (ajout d'une colonne optionnelle) des changements "breaking" (suppression d'une colonne, modification de type). Les premiers peuvent être déployés librement, les seconds nécessitent un processus de communication et de migration : annonce préalable, période de dépréciation, puis suppression effective une fois que les consommateurs se sont adaptés.
La mise en place d'un registre central des contrats facilite la découverte et la gouvernance. Les équipes peuvent y consulter les contrats existants, identifier les propriétaires des datasets, et être notifiées des évolutions à venir. Ce registre peut être intégré à un Data Catalog existant ou constituer un outil dédié.
À découvrir : notre formation Data Engineer
Conclusion
Les Data Contracts représentent une évolution majeure dans la manière dont les organisations gèrent les échanges de données entre équipes. En formalisant les engagements entre producteurs et consommateurs, ils transforment des flux de données fragiles et sources de frictions en interfaces stables et prévisibles.
Leur adoption requiert un investissement initial : définition des contrats, mise en place de l'outillage de validation, évolution des pratiques de collaboration. Mais le retour sur investissement est significatif : réduction drastique des incidents liés aux changements de schéma, amélioration de la qualité des données, et autonomie accrue des équipes qui peuvent évoluer à leur rythme sans coordination permanente.
Pour les Data Engineers, la maîtrise des Data Contracts devient une compétence différenciante. Au-delà de la construction de pipelines performants, il s'agit désormais de concevoir des architectures data où la fiabilité est garantie par design, permettant aux organisations de construire en confiance sur leurs fondations data.