Semantic Layer : faire rejoindre les données aux utilisateurs
Dans un contexte où les entreprises accumulent des volumes de données toujours plus importants, un fossé se creuse souvent entre les équipes techniques qui structurent ces données et les équipes métiers qui doivent les exploiter au quotidien. Les Data Engineers construisent des modèles de données optimisés pour la performance et la cohérence, mais ces structures restent fréquemment incompréhensibles pour un directeur commercial ou un responsable marketing qui souhaite simplement répondre à une question business.

Dans un contexte où les entreprises accumulent des volumes de données toujours plus importants, un fossé se creuse souvent entre les équipes techniques qui structurent ces données et les équipes métiers qui doivent les exploiter au quotidien. Les Data Engineers construisent des modèles de données optimisés pour la performance et la cohérence, mais ces structures restent fréquemment incompréhensibles pour un directeur commercial ou un responsable marketing qui souhaite simplement répondre à une question business.
C'est précisément pour combler ce fossé qu'a émergé le concept de Semantic Layer, ou couche sémantique. Cette abstraction permet de traduire les données techniques en concepts métiers compréhensibles, offrant aux utilisateurs professionnels la possibilité d'interroger les données sans maîtriser SQL ni comprendre les subtilités des modèles relationnels. En créant un vocabulaire commun entre les données brutes et leur signification business, la couche sémantique devient un élément clé des architectures data modernes, facilitant l'adoption de la donnée à l'échelle de l'entreprise.
Qu'est-ce qu'une Semantic Layer ?
La Semantic Layer est une couche d'abstraction qui se positionne entre les données stockées dans un Data Warehouse et les outils de consommation (tableaux de bord, outils de BI, applications métiers). Son rôle principal est de définir des concepts métiers — métriques, dimensions, relations — de manière centralisée et réutilisable, indépendamment de la complexité technique sous-jacente.
Concrètement, plutôt que de demander à un analyste d'écrire une requête SQL complexe impliquant plusieurs jointures et agrégations pour calculer le chiffre d'affaires par région, la couche sémantique lui permet d'utiliser directement un concept préétabli comme "Revenu" associé à la dimension "Région". La traduction en requête SQL optimisée est gérée automatiquement par la couche sémantique.
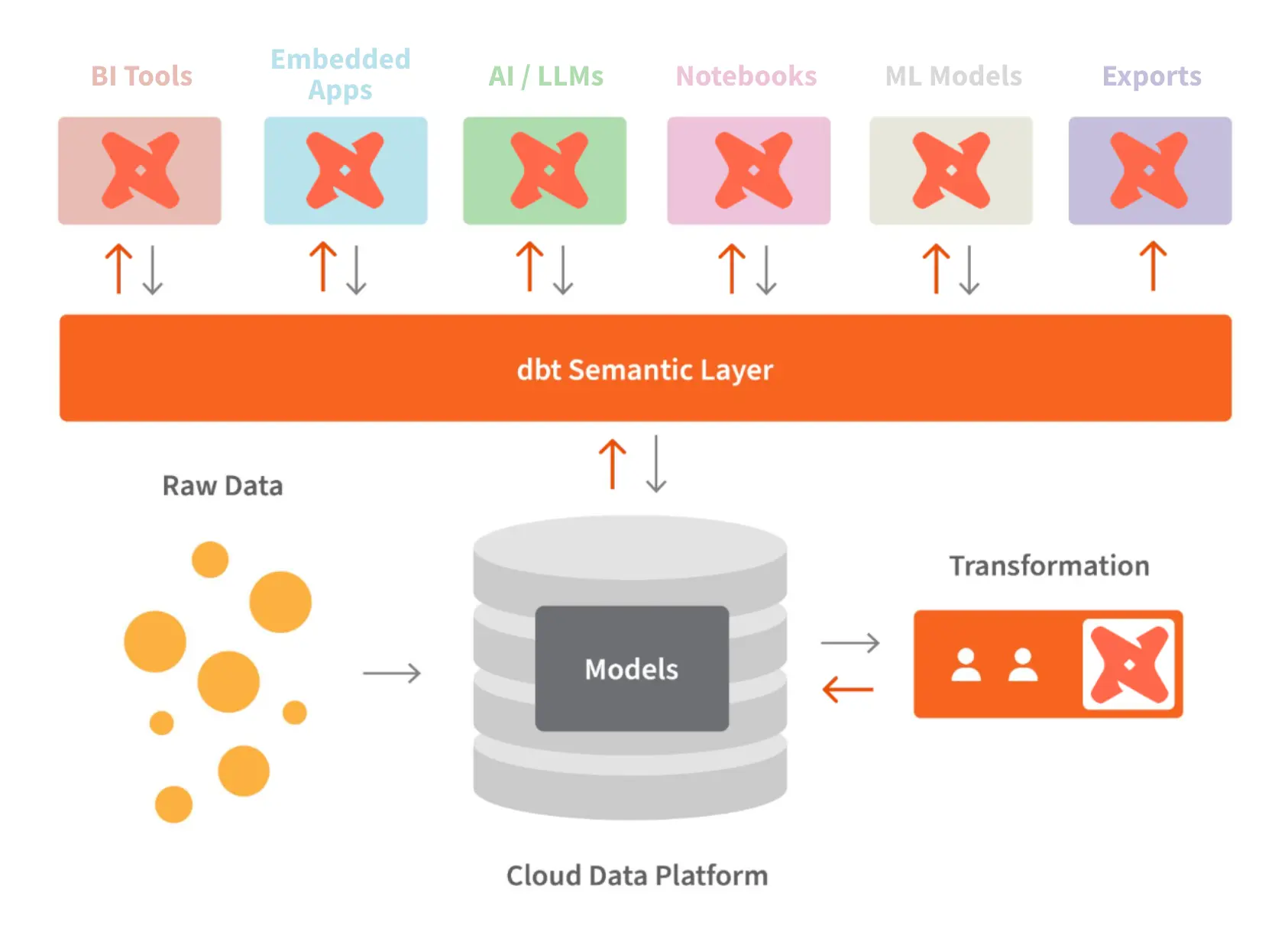
Cette approche présente plusieurs avantages fondamentaux :
- Uniformisation des définitions : une métrique comme le "taux de conversion" est définie une seule fois et utilisée de manière cohérente dans tous les rapports et analyses, éliminant les divergences d'interprétation entre équipes.
- Accessibilité accrue : les utilisateurs métiers peuvent explorer les données en utilisant un vocabulaire qu'ils comprennent, sans dépendre systématiquement des équipes Data pour chaque nouvelle question.
- Gouvernance renforcée : les règles de calcul et les logiques métiers sont centralisées, facilitant les audits et garantissant la traçabilité des métriques.
- Réduction de la dette technique : au lieu de dupliquer la même logique de calcul dans des dizaines de tableaux de bord, celle-ci est maintenue en un point unique.
La couche sémantique s'inscrit naturellement dans les architectures ELT modernes où les données sont d'abord chargées brutes dans le Data Warehouse, transformées avec des outils comme dbt, puis exposées aux utilisateurs via cette couche d'abstraction métier.
Fonctionnement et composants clés
Pour bien comprendre la valeur ajoutée d'une Semantic Layer, il est essentiel de saisir les éléments qui la composent et la manière dont elle interagit avec le reste de l'infrastructure data.
Métriques et dimensions
Au cœur de toute couche sémantique se trouvent les métriques et les dimensions. Les métriques représentent les mesures quantitatives que l'entreprise souhaite suivre : chiffre d'affaires, nombre de commandes, taux de rétention, marge brute. Les dimensions constituent les axes d'analyse selon lesquels ces métriques peuvent être découpées : date, région, catégorie de produit, segment client.
La définition d'une métrique dans une couche sémantique inclut généralement :
- La formule de calcul (somme, moyenne, ratio, calcul complexe)
- Les tables sources et les colonnes impliquées
- Les filtres par défaut éventuels
- Les dimensions compatibles pour l'analyse
Cette définition centralisée garantit que lorsqu'un utilisateur demande le "Revenu mensuel par pays", le calcul effectué sera toujours identique, quel que soit l'outil de visualisation utilisé.
Modèle sémantique et relations
Au-delà des métriques individuelles, la couche sémantique définit un modèle sémantique qui décrit les relations entre les différentes entités métiers. Ce modèle abstrait la complexité des schémas en étoile ou en flocon du Data Warehouse pour présenter une vue logique orientée métier.
Par exemple, un modèle sémantique pour une entreprise e-commerce pourrait définir les entités "Client", "Commande", "Produit" et "Fournisseur" avec leurs relations respectives. Un utilisateur métier n'a pas besoin de savoir que ces informations sont réparties dans huit tables différentes avec des clés étrangères complexes — il voit simplement des concepts qu'il comprend et peut combiner librement.
| Composant | Rôle | Exemple |
|---|---|---|
| Métrique | Mesure quantitative calculée | Revenu total, Panier moyen |
| Dimension | Axe d'analyse | Date, Pays, Catégorie |
| Entité | Objet métier | Client, Produit, Commande |
| Relation | Lien entre entités | Client → Commande |
| Filtre | Restriction prédéfinie | Commandes confirmées uniquement |
Outils et solutions du marché
L'écosystème des Semantic Layers s'est considérablement développé ces dernières années, avec des approches variées allant de solutions intégrées aux outils de BI jusqu'à des plateformes dédiées.
dbt Semantic Layer représente l'une des évolutions les plus significatives dans ce domaine. Intégré à dbt Cloud, il permet de définir des métriques directement dans les projets dbt existants, en s'appuyant sur les modèles de transformation déjà créés. Cette approche "metrics-as-code" offre les mêmes avantages de versioning et de collaboration que dbt apporte aux transformations SQL. Les métriques définies peuvent ensuite être consommées par différents outils de BI via une API standardisée.

Cube est une plateforme open-source spécialisée dans la création de couches sémantiques. Elle propose un langage de modélisation dédié pour définir les métriques et dimensions, un moteur de cache intelligent pour optimiser les performances, et des APIs permettant d'exposer ces métriques à n'importe quelle application. Cube s'intègre avec les principaux Data Warehouses comme Snowflake, BigQuery ou Redshift.
LookML de Looker (désormais partie de Google Cloud) constitue l'une des implémentations historiques du concept de couche sémantique. Ce langage de modélisation permet de définir des vues logiques sur les données, avec des métriques et dimensions réutilisables. L'approche de Looker a largement contribué à populariser le concept de couche sémantique dans l'industrie.
AtScale propose une solution entreprise qui crée une couche sémantique universelle compatible avec les outils de BI existants (Tableau, Power BI, Excel). Son approche se distingue par sa capacité à optimiser automatiquement les requêtes et à gérer le cache de manière intelligente.
D'autres acteurs comme MetricFlow (acquis par dbt Labs), Metriql ou encore les fonctionnalités natives de certains outils comme Power BI avec ses mesures DAX contribuent à enrichir cet écosystème. Le choix d'une solution dépend généralement de l'infrastructure existante, des compétences de l'équipe et du degré de centralisation souhaité.
Intégration dans l'architecture data moderne
La couche sémantique ne fonctionne pas de manière isolée — elle s'inscrit dans une architecture data globale où chaque composant joue un rôle spécifique.
Dans une architecture typique du Modern Data Stack, les données sont d'abord ingérées depuis les sources opérationnelles vers le Data Warehouse à l'aide d'outils comme Fivetran ou Airbyte. Elles sont ensuite transformées et modélisées avec dbt pour créer des tables analytiques propres et documentées. La couche sémantique vient se positionner au-dessus de ces tables transformées pour exposer les métriques métiers aux outils de consommation.
Cette architecture présente plusieurs bénéfices :
- Séparation des responsabilités : les Data Engineers se concentrent sur la fiabilité des pipelines et la qualité des transformations, tandis que les Analytics Engineers définissent les métriques métiers dans la couche sémantique.
- Flexibilité des outils de consommation : les équipes peuvent utiliser différents outils de BI ou d'analyse sans dupliquer les définitions de métriques.
- Évolutivité : l'ajout de nouvelles sources de données ou de nouvelles métriques se fait de manière modulaire sans impacter l'ensemble du système.
La couche sémantique interagit également avec les pratiques de Data Governance. En centralisant les définitions métiers, elle facilite la création d'un catalogue de données compréhensible et la mise en place de contrôles d'accès granulaires basés sur les concepts métiers plutôt que sur les tables techniques.
À découvrir : notre formation Data Engineer
Cas d'usage et bonnes pratiques
L'adoption d'une couche sémantique se justifie particulièrement dans certains contextes où la valeur apportée est immédiatement perceptible.
Harmonisation des KPIs à l'échelle de l'entreprise : lorsque différentes équipes utilisent des définitions divergentes pour les mêmes métriques, la couche sémantique permet d'établir une source de vérité unique. Une entreprise retail peut ainsi s'assurer que le "taux de conversion" signifie exactement la même chose pour l'équipe e-commerce, l'équipe marketing et la direction financière.
Self-service analytics : en rendant les données accessibles via des concepts métiers compréhensibles, la couche sémantique permet aux utilisateurs non techniques d'explorer les données de manière autonome. Les équipes Data sont ainsi libérées des demandes ad hoc répétitives et peuvent se concentrer sur des projets à plus forte valeur ajoutée.
Accélération des projets analytiques : lorsqu'une nouvelle initiative nécessite des analyses, les métriques déjà définies dans la couche sémantique peuvent être réutilisées instantanément, réduisant considérablement le temps de mise en œuvre.
Pour tirer le meilleur parti d'une couche sémantique, plusieurs bonnes pratiques méritent d'être suivies :
- Impliquer les équipes métiers dès la définition des métriques pour s'assurer que le vocabulaire utilisé correspond à leur réalité quotidienne.
- Documenter exhaustivement chaque métrique avec sa définition business, sa méthode de calcul et ses cas d'usage recommandés.
- Versionner les définitions pour pouvoir tracer les évolutions et comprendre les changements historiques dans les calculs.
- Commencer par les métriques les plus utilisées plutôt que de chercher à tout modéliser d'emblée — une approche itérative permet d'obtenir rapidement de la valeur.
Conclusion
La Semantic Layer s'impose progressivement comme un composant essentiel des architectures data modernes, répondant au besoin croissant de démocratiser l'accès aux données au sein des organisations. En créant un pont entre la complexité technique des Data Warehouses et le vocabulaire métier des utilisateurs finaux, elle permet de transformer les données en un véritable actif stratégique accessible à tous.
L'écosystème des outils de couche sémantique a atteint une maturité suffisante pour que les entreprises puissent choisir une solution adaptée à leur contexte, qu'il s'agisse d'une approche intégrée avec dbt, d'une plateforme dédiée comme Cube, ou des fonctionnalités natives de leur outil de BI. Pour les Data Engineers et Analytics Engineers, la maîtrise de ces concepts devient une compétence différenciante, permettant de créer des infrastructures data qui servent réellement les besoins métiers plutôt que de simplement stocker et transformer des données. Dans un monde où la capacité à prendre des décisions basées sur les données devient un avantage concurrentiel majeur, la couche sémantique représente l'un des leviers les plus efficaces pour accélérer cette transformation.


