Data Lineage : tracer le parcours de vos données
Dans un écosystème data de plus en plus complexe, où les données transitent par de multiples systèmes avant d'atteindre les utilisateurs finaux, une question fondamentale se pose : d'où viennent réellement les données que nous utilisons pour prendre des décisions ? Entre les extractions depuis des sources opérationnelles, les transformations successives dans les pipelines ETL/ELT, les agrégations dans le Data Warehouse et les visualisations dans les tableaux de bord, le parcours d'une donnée peut rapidement devenir opaque.

Dans un écosystème data de plus en plus complexe, où les données transitent par de multiples systèmes avant d'atteindre les utilisateurs finaux, une question fondamentale se pose : d'où viennent réellement les données que nous utilisons pour prendre des décisions ? Entre les extractions depuis des sources opérationnelles, les transformations successives dans les pipelines ETL/ELT, les agrégations dans le Data Warehouse et les visualisations dans les tableaux de bord, le parcours d'une donnée peut rapidement devenir opaque.
C'est précisément pour répondre à ce besoin de transparence qu'a émergé le concept de Data Lineage, ou lignage de données. Cette pratique consiste à documenter et visualiser le cycle de vie complet des données, depuis leur origine jusqu'à leur consommation finale. En offrant une traçabilité exhaustive des transformations appliquées et des dépendances entre les différents éléments du système d'information, le Data Lineage devient un pilier essentiel de la gouvernance des données et de la confiance que les organisations peuvent accorder à leurs analyses.
Pourquoi tracer le parcours des données ?
La complexité croissante des architectures data modernes rend le suivi manuel des données pratiquement impossible. Une entreprise moyenne utilise aujourd'hui des dizaines de sources de données différentes, plusieurs outils de transformation et d'orchestration, et de nombreuses couches de consommation. Sans visibilité sur ce parcours, les équipes Data et les utilisateurs métiers naviguent à l'aveugle.
Le Data Lineage répond à plusieurs enjeux critiques pour les organisations :
- Confiance dans les données : lorsqu'un dirigeant consulte un indicateur de performance, il doit pouvoir comprendre comment ce chiffre a été calculé et à partir de quelles données sources. Le lineage permet de remonter la chaîne complète et de valider la pertinence des résultats.
- Analyse d'impact : avant de modifier une table source ou une règle de transformation, les équipes Data doivent pouvoir identifier tous les éléments en aval qui seront affectés. Sans cette visibilité, le moindre changement peut provoquer des effets de bord imprévus sur des rapports critiques.
- Conformité réglementaire : des réglementations comme le RGPD exigent de pouvoir démontrer comment les données personnelles sont collectées, transformées et utilisées. Le lineage fournit cette traçabilité indispensable aux audits.
- Debugging et résolution d'incidents : lorsqu'une anomalie est détectée dans un tableau de bord, le lineage permet de remonter rapidement à la source du problème, qu'il s'agisse d'une erreur dans les données d'origine ou d'un bug dans une transformation intermédiaire.
Dans le contexte du Modern Data Stack, où les données passent par des outils d'ingestion comme Airbyte ou Fivetran, des transformations avec dbt, et une exposition via des outils de BI, la nécessité d'une vue unifiée du parcours des données devient encore plus prégnante.
Les différentes dimensions du Data Lineage
Le Data Lineage peut être appréhendé selon plusieurs niveaux de granularité, chacun répondant à des besoins spécifiques au sein de l'organisation.
Lineage technique vs lineage métier
Le lineage technique se concentre sur les aspects infrastructurels : quelles tables sont lues par quel job, quelles colonnes sont utilisées dans quelles transformations, quels pipelines alimentent quels datasets. Cette vision est principalement destinée aux Data Engineers et aux équipes techniques qui doivent maintenir et faire évoluer les systèmes.
Le lineage métier adopte une perspective plus fonctionnelle, en traduisant les flux techniques en concepts compréhensibles par les utilisateurs finaux. Plutôt que de parler de tables et de colonnes, on évoque des indicateurs comme le "chiffre d'affaires" ou des dimensions comme le "segment client". Cette abstraction permet aux équipes métiers de comprendre la provenance des données qu'elles manipulent quotidiennement.
| Dimension | Lineage technique | Lineage métier |
|---|---|---|
| Audience | Data Engineers, DBA | Analystes, décideurs |
| Granularité | Tables, colonnes, jobs | Métriques, KPIs, rapports |
| Vocabulaire | SQL, schémas, pipelines | Termes métiers |
| Usage principal | Maintenance, debugging | Gouvernance, confiance |
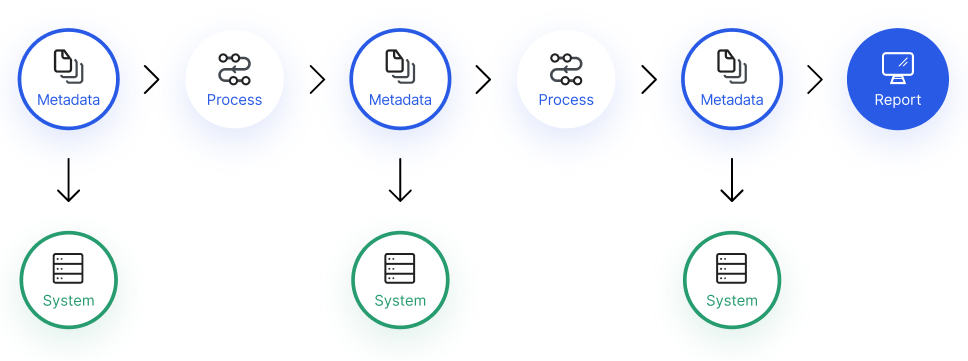
Lineage statique vs lineage dynamique
Le lineage statique est dérivé de l'analyse du code source : scripts SQL, configurations dbt, définitions de pipelines Airflow ou Prefect. Il documente les relations potentielles entre les éléments du système, indépendamment de leur exécution effective.
Le lineage dynamique capture les flux réels observés lors de l'exécution des pipelines. Il intègre des métadonnées d'exécution comme les timestamps, les volumes de données traités ou les durées de processing. Cette approche offre une vision plus fidèle de ce qui se passe réellement en production, mais nécessite une instrumentation plus poussée des systèmes.
Outils et solutions de Data Lineage
L'écosystème des outils de Data Lineage s'est considérablement enrichi ces dernières années, avec des approches variées allant de solutions open source légères à des plateformes enterprise complètes.
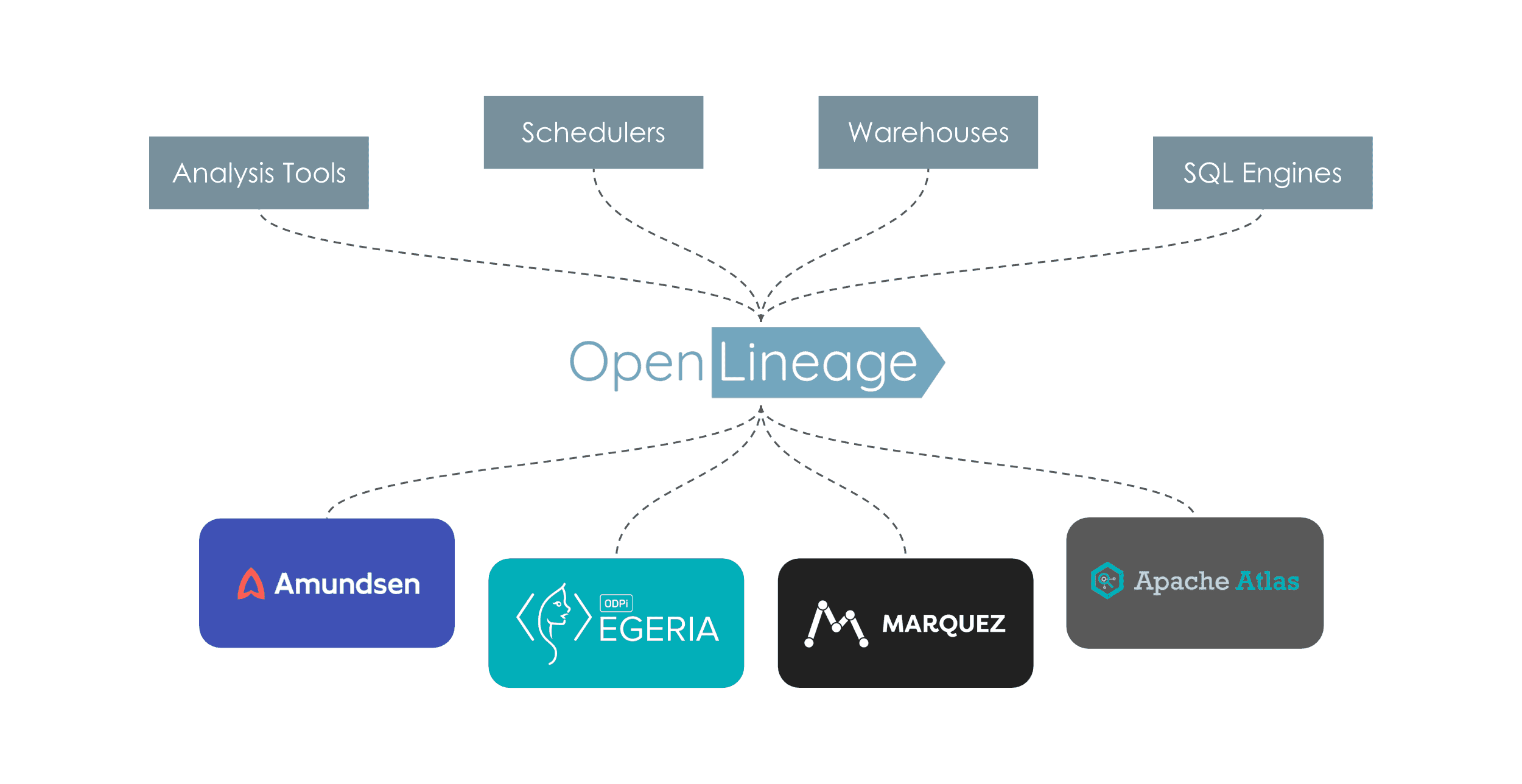
OpenLineage est un standard open source qui définit un format commun pour capturer et échanger des métadonnées de lineage. Plutôt qu'un outil à part entière, il s'agit d'une spécification permettant l'interopérabilité entre différents systèmes. Des intégrations natives existent avec Airflow, Spark, dbt et de nombreux autres outils du Modern Data Stack. Cette approche standardisée évite le vendor lock-in et facilite la construction d'une vue unifiée du lineage à travers des technologies hétérogènes.
Marquez, développé par WeWork puis devenu projet de la Linux Foundation, est une plateforme de collecte et de visualisation de métadonnées construite sur le standard OpenLineage. Elle permet de centraliser les informations de lineage provenant de multiples sources et d'explorer visuellement les dépendances entre les datasets. Son architecture modulaire et son API ouverte en font une base solide pour construire une solution de gouvernance sur mesure.
DataHub, initialement créé par LinkedIn, est une plateforme de découverte et de gouvernance des données qui intègre des fonctionnalités de lineage. Au-delà du simple tracking des flux, DataHub propose un catalogue de données complet avec recherche, documentation collaborative et gestion des ownership. Son adoption par de nombreuses entreprises tech témoigne de sa maturité.
Atlan représente la nouvelle génération de plateformes de gouvernance, avec une approche "data workspace" qui combine catalogue, lineage, collaboration et observabilité. L'interface moderne et les intégrations natives avec les outils cloud en font une solution particulièrement adaptée aux organisations qui ont adopté le Modern Data Stack.
Côté solutions propriétaires, Collibra et Alation dominent le marché enterprise avec des fonctionnalités avancées de gouvernance, de glossaire métier et de stewardship. Ces plateformes s'adressent aux grandes organisations ayant des besoins complexes de conformité et de collaboration cross-fonctionnelle.
Il est également important de noter que certains outils intègrent nativement des capacités de lineage. dbt génère automatiquement une documentation incluant le graphe de dépendances entre les modèles, offrant une forme de lineage technique sans configuration supplémentaire. De même, les Data Warehouses modernes comme Snowflake ou BigQuery proposent des fonctionnalités natives de tracking des accès et des transformations.
Mise en œuvre et bonnes pratiques
L'implémentation d'une solution de Data Lineage nécessite une approche progressive et pragmatique. Vouloir capturer immédiatement l'intégralité des flux de données d'une organisation est souvent contre-productif.
Une approche recommandée consiste à commencer par les données les plus critiques : les indicateurs suivis par la direction, les rapports réglementaires, les données alimentant des décisions opérationnelles majeures. En documentant d'abord ces flux prioritaires, les équipes peuvent démontrer rapidement la valeur du lineage et affiner leur méthodologie avant d'étendre la couverture.
L'automatisation de la collecte est un facteur clé de succès. Les solutions qui nécessitent une documentation manuelle des flux deviennent rapidement obsolètes face à l'évolution constante des pipelines. Privilégier des outils capables d'extraire automatiquement le lineage depuis le code source ou les métadonnées d'exécution garantit une information toujours à jour.
La gouvernance du lineage lui-même ne doit pas être négligée. Il convient de définir clairement les responsabilités : qui valide l'exactitude du lineage ? Comment sont gérées les exceptions ? Quelle est la fréquence de mise à jour acceptable ? Ces questions organisationnelles sont souvent plus déterminantes que le choix de l'outil technique.
Enfin, le lineage ne prend sa pleine valeur que s'il est accessible aux bonnes personnes au bon moment. Intégrer les informations de lineage directement dans les outils de BI, dans la documentation des datasets ou dans les alertes d'incident permet de contextualiser l'information et d'en maximiser l'usage.
À découvrir : notre formation Data Engineer
Conclusion
Le Data Lineage s'impose progressivement comme une composante indispensable de toute architecture data mature. En offrant une visibilité complète sur le parcours des données, il répond aux enjeux de confiance, de conformité et d'efficacité opérationnelle qui préoccupent les organisations data-driven.
L'écosystème des outils a considérablement mûri, avec des solutions adaptées à tous les contextes : des standards ouverts comme OpenLineage pour les équipes techniques souhaitant garder le contrôle, des plateformes intégrées comme DataHub ou Atlan pour celles recherchant une solution clé en main, et des offres enterprise pour les organisations aux besoins de gouvernance avancés. Pour les Data Engineers, la capacité à mettre en place et exploiter le lineage devient une compétence différenciante. Au-delà de la construction de pipelines performants, il s'agit désormais de garantir la transparence et la traçabilité des flux de données, conditions sine qua non pour que les organisations puissent véritablement exploiter leur patrimoine data en toute confiance.