Gérer l'état des agents IA
La gestion de l'état englobe l'ensemble des mécanismes permettant à un agent de persister, récupérer et exploiter les informations nécessaires à son fonctionnement. Elle détermine ce que l'agent "sait" à un instant donné, comment il accède à ses connaissances passées, et comment il maintient la cohérence de ses actions dans le temps. Dans cet article, nous allons explorer les différentes dimensions de cette problématique, des arbitrages entre mémoire court terme et long terme jusqu'aux architectures de stockage adaptées, en passant par les patterns d'event sourcing et la distinction fondamentale entre mémoire conversationnelle et mémoire de tâche.

L'émergence de l'Agentic AI a transformé notre façon de concevoir les systèmes d'intelligence artificielle. Les agents IA ne se contentent plus de répondre à des requêtes isolées : ils raisonnent, planifient et exécutent des séquences d'actions complexes pour atteindre leurs objectifs. Cependant, cette sophistication croissante soulève un défi technique majeur : comment un agent peut-il maintenir une compréhension cohérente de son contexte à travers le temps et les interactions ?
Sans gestion d'état appropriée, un agent se retrouve condamné à repartir de zéro à chaque échange, incapable de se souvenir des informations collectées, des actions entreprises ou des préférences exprimées par l'utilisateur. Cette amnésie structurelle limite drastiquement l'utilité des agents dans des scénarios réels où la continuité et l'apprentissage sont essentiels.
La gestion de l'état englobe l'ensemble des mécanismes permettant à un agent de persister, récupérer et exploiter les informations nécessaires à son fonctionnement. Elle détermine ce que l'agent "sait" à un instant donné, comment il accède à ses connaissances passées, et comment il maintient la cohérence de ses actions dans le temps. Dans cet article, nous allons explorer les différentes dimensions de cette problématique, des arbitrages entre mémoire court terme et long terme jusqu'aux architectures de stockage adaptées, en passant par les patterns d'event sourcing et la distinction fondamentale entre mémoire conversationnelle et mémoire de tâche.
Mémoire court terme vs long terme : deux temporalités complémentaires
La gestion de l'état d'un agent IA s'articule autour de deux horizons temporels distincts qui répondent à des besoins différents et impliquent des stratégies d'implémentation spécifiques.
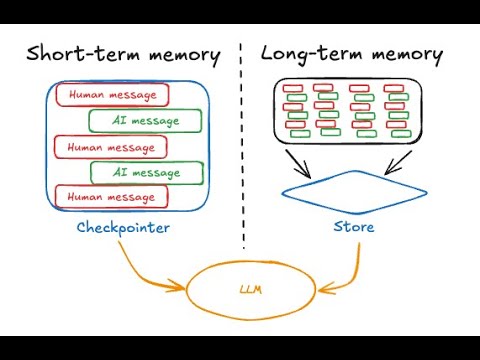
La mémoire à court terme correspond au contexte immédiat de l'agent : les derniers échanges d'une conversation, les résultats des actions récentes, l'état courant d'une tâche en cours d'exécution. Dans la pratique, cette mémoire se matérialise principalement par la fenêtre de contexte du LLM, c'est-à-dire l'ensemble des tokens que le modèle peut traiter simultanément lors d'un appel. Cette mémoire présente des caractéristiques distinctes :
- Capacité limitée : définie par la taille de la fenêtre de contexte (4K, 32K, 128K tokens selon les modèles)
- Accès immédiat : aucune récupération externe nécessaire, tout est dans le prompt
- Volatilité : les informations disparaissent une fois la session terminée ou le contexte saturé
- Coût proportionnel : chaque token consommé impacte directement la facturation et la latence
La mémoire à long terme vise à persister l'information au-delà de la session courante. Elle permet à l'agent de se souvenir d'interactions passées, de connaissances accumulées, de préférences utilisateur ou de faits métier importants. Cette mémoire nécessite un système de stockage externe et des mécanismes de récupération pour être exploitée, introduisant une latence et une complexité supplémentaires.
| Caractéristique | Mémoire court terme | Mémoire long terme |
|---|---|---|
| Durée de rétention | Session en cours | Persistante |
| Capacité | Limitée (fenêtre contexte) | Extensible |
| Latence d'accès | Immédiate | Requiert une récupération |
| Implémentation | Gestion du contexte LLM | Stockage externe + retrieval |
| Coût | Tokens par appel | Infrastructure de stockage |
La gestion efficace de la mémoire court terme repose sur des stratégies d'optimisation du contexte. La fenêtre glissante conserve uniquement les N derniers messages, évacuant les plus anciens. Le résumé progressif condense périodiquement l'historique en un synopsis plus compact, préservant l'essentiel tout en libérant de l'espace. La sélection par pertinence utilise un mécanisme de retrieval pour n'inclure que les éléments directement liés à la requête courante.
def manage_short_term_memory(messages, max_tokens=4000):
"""Gestion du contexte avec résumé progressif."""
current_tokens = count_tokens(messages)
if current_tokens > max_tokens:
# Séparer messages anciens et récents
old_messages = messages[:-5]
recent_messages = messages[-5:]
# Résumer les anciens messages
summary = llm.summarize(old_messages)
# Reconstruire le contexte optimisé
return [
{"role": "system", "content": f"Résumé des échanges précédents: {summary}"}
] + recent_messages
return messages
python
L'articulation entre ces deux niveaux de mémoire constitue un enjeu architectural majeur. Un agent performant doit pouvoir enrichir son contexte court terme avec des informations pertinentes extraites de sa mémoire long terme, tout en évitant de surcharger la fenêtre de contexte avec des données non essentielles. Ce mécanisme de récupération sélective s'apparente au fonctionnement du RAG, appliqué non plus à des documents externes mais à la propre mémoire de l'agent.
Memory stores : choisir l'architecture de stockage adaptée
La mémoire long terme d'un agent IA nécessite une infrastructure de stockage persistant. Le choix de cette infrastructure impacte directement les capacités de l'agent, ses performances et sa scalabilité. Trois grandes familles de solutions se distinguent, chacune avec ses forces et ses cas d'usage privilégiés.
Bases de données vectorielles
Les bases vectorielles (Pinecone, Weaviate, Chroma, Qdrant) constituent le choix naturel pour stocker des souvenirs sous forme d'embeddings. Elles permettent une recherche par similarité sémantique, récupérant les informations conceptuellement proches de la requête courante même si les formulations diffèrent. Cette capacité est particulièrement précieuse pour la mémoire épisodique, où l'agent doit retrouver des conversations ou événements passés pertinents.
L'architecture type combine vectorisation des souvenirs via un modèle d'embedding, stockage dans la base vectorielle avec métadonnées associées (timestamp, tags, identifiants), et récupération par recherche de similarité lors des requêtes. Cette approche excelle pour les requêtes ouvertes du type "Qu'avons-nous discuté concernant le projet X ?" où la correspondance exacte est impossible.
Bases de données relationnelles
Les bases SQL (PostgreSQL, MySQL) offrent une structure rigide mais puissante pour les informations factuelles et les relations bien définies. Elles sont idéales pour stocker les préférences utilisateur explicites, les états de workflow, les métadonnées structurées ou les données transactionnelles. L'extension pgvector de PostgreSQL permet même de combiner stockage relationnel et vectoriel dans une même infrastructure.
Les bases relationnelles brillent lorsque l'agent doit répondre à des requêtes précises : "Quel est le statut du ticket #1234 ?", "Quelles sont les préférences de notification de cet utilisateur ?". La garantie ACID assure la cohérence des données, essentielle pour les états critiques d'un agent en production.
Bases de données graphe
Les bases graphe (Neo4j, Amazon Neptune) modélisent naturellement les relations complexes entre entités. Pour un agent devant naviguer dans un réseau de connaissances interconnectées, clients liés à des produits, eux-mêmes liés à des catégories et des fournisseurs, cette structure offre une expressivité inégalée.
Exemple de modélisation graphe pour un agent commercial :
(Client:Jean) --[A_ACHETÉ]--> (Produit:LaptopPro)
(Produit:LaptopPro) --[APPARTIENT_À]--> (Catégorie:Informatique)
(Client:Jean) --[PRÉFÈRE]--> (Canal:Email)
(Client:Jean) --[TRAVAILLE_POUR]--> (Entreprise:TechCorp)
(Entreprise:TechCorp) --[SEGMENT]--> (Premium)
plaintext
Cette représentation permet à l'agent de traverser les relations pour construire une compréhension riche du contexte. Une requête comme "Trouve des produits susceptibles d'intéresser les collègues de Jean" devient naturelle à exprimer et à résoudre.
| Type de store | Forces | Cas d'usage privilégié |
|---|---|---|
| Base vectorielle | Recherche sémantique, similarité | Mémoire épisodique, RAG |
| Base relationnelle | Structure, cohérence, requêtes précises | Préférences, états, métadonnées |
| Base graphe | Relations complexes, navigation | Réseaux de connaissances, ontologies |
En pratique, les architectures de production combinent souvent plusieurs types de stores. Un agent sophistiqué pourrait utiliser une base vectorielle pour sa mémoire épisodique, PostgreSQL pour les états de workflow et les préférences utilisateur, et Neo4j pour naviguer dans le graphe de connaissances métier. L'enjeu devient alors d'orchestrer ces différentes sources de manière cohérente.
Event sourcing : tracer l'histoire de l'agent
L'event sourcing représente un paradigme architectural particulièrement adapté à la gestion d'état des agents IA. Plutôt que de stocker uniquement l'état courant, cette approche consiste à persister la séquence complète des événements qui ont conduit à cet état. L'état actuel peut alors être reconstruit en rejouant ces événements.
Pour un agent IA, les événements peuvent inclure les requêtes reçues, les actions exécutées, les observations obtenues, les décisions prises et les réponses générées. Cette granularité offre plusieurs avantages majeurs :
- Audit complet : chaque décision de l'agent peut être retracée jusqu'à son origine
- Debugging facilité : reproduire un comportement problématique devient possible en rejouant les événements
- Reprise après incident : l'état peut être reconstruit à n'importe quel point de l'historique
- Analyse comportementale : les patterns d'action de l'agent peuvent être étudiés a posteriori
# Structure d'événements pour un agent
events = [
{"type": "REQUEST_RECEIVED", "timestamp": "...", "content": "Réserve une salle pour demain"},
{"type": "THOUGHT", "timestamp": "...", "content": "Je dois vérifier les disponibilités"},
{"type": "ACTION_INVOKED", "timestamp": "...", "tool": "check_availability", "params": {...}},
{"type": "OBSERVATION", "timestamp": "...", "result": {"available_rooms": ["Einstein", "Curie"]}},
{"type": "THOUGHT", "timestamp": "...", "content": "Einstein est disponible, je vais la réserver"},
{"type": "ACTION_INVOKED", "timestamp": "...", "tool": "book_room", "params": {"room": "Einstein"}},
{"type": "OBSERVATION", "timestamp": "...", "result": {"success": True, "booking_id": "B123"}},
{"type": "RESPONSE_SENT", "timestamp": "...", "content": "La salle Einstein a été réservée..."}
]
python
L'implémentation de l'event sourcing pour les agents IA se marie naturellement avec les capacités de checkpointing offertes par des frameworks comme LangGraph. Chaque étape du graphe d'exécution peut être persistée comme un événement, permettant non seulement la reprise après interruption mais aussi l'analyse détaillée des trajectoires de l'agent.
Cette approche implique cependant des considérations de volumétrie. Un agent actif génère rapidement des millions d'événements, nécessitant des stratégies de rétention et d'archivage. Les événements récents restent en stockage rapide pour la reconstruction d'état, tandis que l'historique plus ancien est archivé vers des solutions de stockage économiques, accessible pour l'audit mais pas pour le fonctionnement quotidien.
L'event sourcing facilite également l'implémentation de patterns avancés comme le temporal querying, permettant de répondre à des questions du type "Quel était l'état de la conversation hier à 15h ?" ou "Combien d'actions l'agent a-t-il exécutées cette semaine ?". Ces capacités s'avèrent précieuses pour le monitoring, l'évaluation des performances et l'amélioration continue des agents.
Conversation memory vs task memory : deux finalités distinctes
Au-delà des considérations temporelles et architecturales, la gestion de l'état doit distinguer deux finalités fondamentalement différentes : la mémoire conversationnelle et la mémoire de tâche. Cette distinction, souvent négligée, impacte pourtant significativement la conception des agents.
La mémoire conversationnelle capture le fil du dialogue avec l'utilisateur. Elle inclut les messages échangés, le ton de la conversation, les préférences de communication exprimées, les clarifications demandées. Son objectif est de maintenir une interaction fluide et personnalisée, où l'agent "se souvient" de ce qui a été dit et adapte ses réponses en conséquence.
La mémoire de tâche se concentre sur l'avancement vers un objectif. Elle trace les étapes accomplies, les résultats intermédiaires obtenus, les ressources mobilisées, les obstacles rencontrés. Son objectif est d'assurer la progression efficace vers la complétion de la mission confiée à l'agent.
| Aspect | Mémoire conversationnelle | Mémoire de tâche |
|---|---|---|
| Contenu | Messages, ton, préférences | Actions, résultats, état d'avancement |
| Portée | Relation utilisateur-agent | Mission spécifique |
| Persistance | Souvent long terme | Durée de vie de la tâche |
| Utilisation | Personnalisation, cohérence | Progression, reprise |
Cette distinction devient critique dans les architectures multi-agents. Un superviseur coordonnant plusieurs agents workers doit maintenir une mémoire de tâche globale tout en permettant à chaque worker de gérer sa propre mémoire conversationnelle avec l'utilisateur. La séparation claire de ces deux types de mémoire évite les confusions et facilite le debugging.
class AgentState:
def __init__(self):
# Mémoire conversationnelle
self.conversation_history = []
self.user_preferences = {}
self.communication_style = "formal"
# Mémoire de tâche
self.current_task = None
self.completed_steps = []
self.pending_actions = []
self.intermediate_results = {}
self.task_start_time = None
python
En pratique, un agent efficace sait basculer dynamiquement entre ces deux mémoires. Lors d'une clarification avec l'utilisateur, la mémoire conversationnelle prime. Lors de l'exécution d'une action, la mémoire de tâche guide les décisions. Les frameworks modernes comme LangGraph permettent de modéliser explicitement ces deux dimensions dans l'état partagé du graphe d'exécution.
La gestion des transitions entre conversations et tâches mérite une attention particulière. Lorsqu'un utilisateur initie une nouvelle demande alors qu'une tâche précédente est en cours, l'agent doit décider s'il suspend la tâche courante, l'abandonne, ou tente de la paralléliser avec la nouvelle requête. Ces décisions s'appuient sur une lecture conjointe des deux types de mémoire.
À découvrir : notre formation Agentic AI
Conclusion
La gestion de l'état constitue un pilier fondamental des architectures d'agents IA performantes. Sans elle, les agents restent des systèmes amnésiques, incapables de capitaliser sur leurs expériences passées ou de maintenir une cohérence dans leurs interactions. Avec une gestion d'état bien conçue, ils deviennent des assistants véritablement intelligents, capables de continuité, d'apprentissage et d'adaptation.
L'arbitrage entre mémoire court terme et long terme, le choix des memory stores adaptés aux différents types d'information, l'adoption de patterns comme l'event sourcing, et la distinction entre mémoire conversationnelle et mémoire de tâche forment un cadre conceptuel essentiel pour les architectes de systèmes agentiques. Ces dimensions ne sont pas indépendantes : elles s'articulent pour former une infrastructure cohérente au service des objectifs de l'agent.
Les outils disponibles, des bases vectorielles aux frameworks comme LangGraph avec leurs capacités de checkpointing, simplifient considérablement l'implémentation. Cependant, le succès en production repose sur une architecture réfléchie qui anticipe les besoins de persistance, les patterns d'accès aux données et les exigences de traçabilité.
À mesure que les agents IA se déploient dans des contextes toujours plus exigeants, la maîtrise de ces mécanismes de gestion d'état devient un avantage compétitif pour les équipes de développement. Les organisations capables de concevoir des agents qui retiennent, apprennent et évoluent construiront les solutions d'Agentic AI qui transformeront durablement les usages en entreprise.


