Évaluation d'agents IA : comment faire ?
L'évaluation d'un agent IA s'articule autour de plusieurs familles de métriques qui, ensemble, fournissent une vision complète de sa performance opérationnelle.

L'évaluation des systèmes d'IA a considérablement évolué avec l'émergence de l'Agentic AI. Si mesurer la performance d'un LLM classique se concentre principalement sur la qualité des réponses générées, évaluer un agent IA requiert une approche fondamentalement différente. Un agent ne se contente pas de produire du texte : il raisonne, planifie, exécute des actions, interagit avec des outils externes et s'adapte en fonction des résultats obtenus.
Cette complexité supplémentaire rend les métriques traditionnelles insuffisantes. Un agent peut générer des réponses linguistiquement parfaites tout en échouant systématiquement à accomplir les tâches qui lui sont confiées. À l'inverse, un agent efficace peut atteindre ses objectifs avec des formulations moins élégantes mais des actions parfaitement orchestrées. L'évaluation doit donc capturer cette dimension opérationnelle qui distingue les agents des simples modèles génératifs.
Dans cet article, nous allons explorer les métriques spécifiques à l'évaluation des agents IA, comprendre ce qui les différencie des approches utilisées pour les LLM et les systèmes RAG, et découvrir les méthodologies pour construire des évaluations robustes et représentatives.
Pourquoi l'évaluation des agents diffère-t-elle ?
Avant d'aborder les métriques spécifiques, il est essentiel de comprendre pourquoi les agents IA nécessitent une approche d'évaluation distincte de celle appliquée aux LLM classiques ou aux systèmes RAG.
Un LLM standard est évalué sur sa capacité à produire des réponses pertinentes, cohérentes et factuellement correctes. Les métriques classiques comme la perplexité, les scores BLEU/ROUGE ou les évaluations humaines de qualité suffisent généralement à caractériser sa performance. Un système RAG ajoute une dimension de récupération d'information, nécessitant des métriques supplémentaires sur la pertinence des documents récupérés et la fidélité de la réponse aux sources.
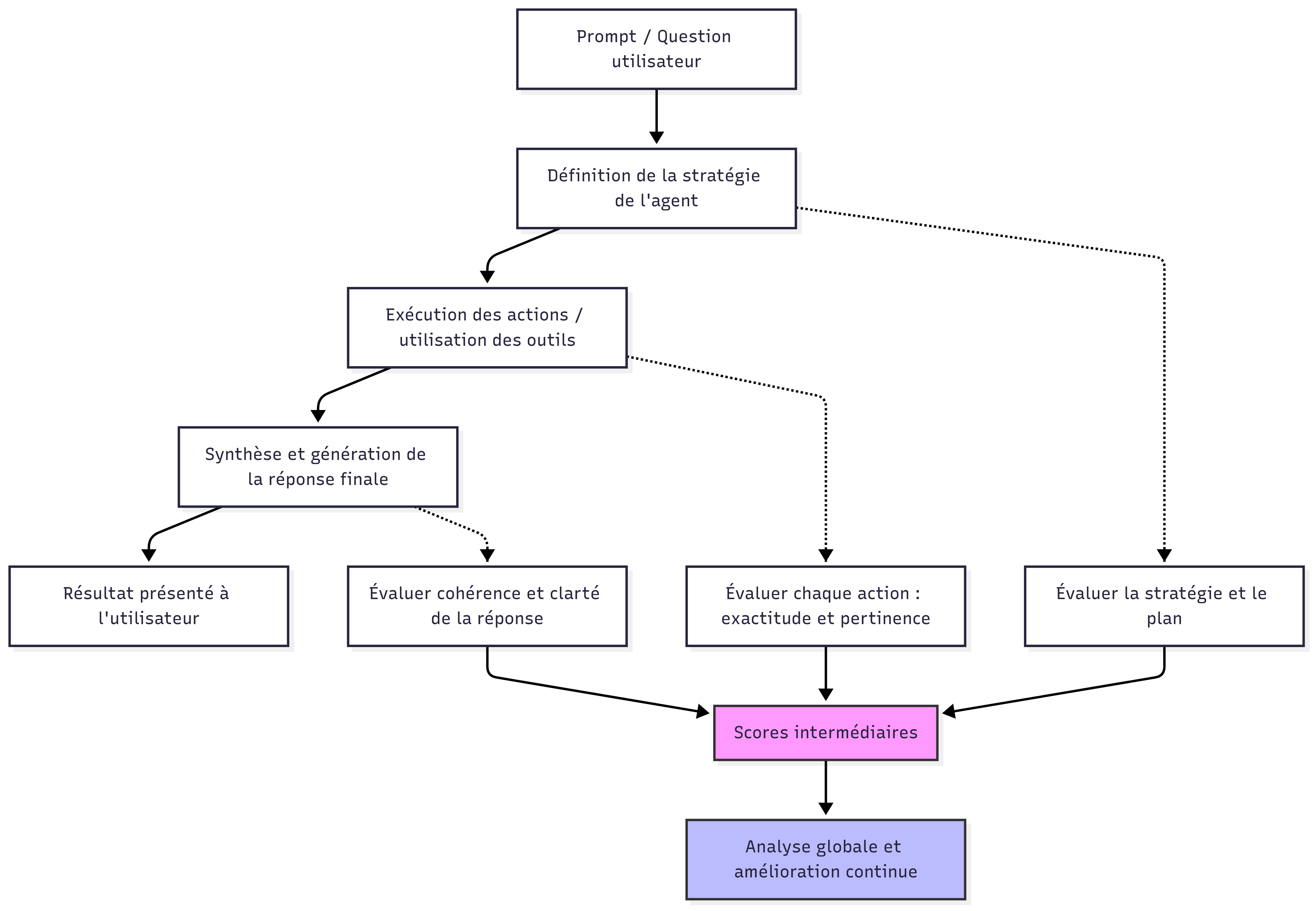
Un agent IA, en revanche, opère dans une boucle d'interaction avec son environnement. Qu'il s'agisse d'un agent ReAct qui alterne réflexion et action, ou d'une architecture plus complexe avec superviseur, l'agent doit être jugé sur sa capacité à atteindre des objectifs concrets, pas uniquement sur la qualité de ses outputs textuels.
| Dimension | LLM classique | Système RAG | Agent IA |
|---|---|---|---|
| Focus principal | Qualité du texte généré | Pertinence de la récupération + génération | Accomplissement de tâches |
| Nature de l'évaluation | Statique (entrée → sortie) | Semi-dynamique (requête → recherche → réponse) | Dynamique (boucle itérative) |
| Métriques clés | Perplexité, BLEU, cohérence | Recall, précision, faithfulness | Taux de succès, efficacité, autonomie |
| Complexité | Faible | Moyenne | Élevée |
Cette différence fondamentale implique que l'évaluation d'un agent doit capturer non seulement ce qu'il produit, mais aussi comment il y parvient : le chemin emprunté, les ressources consommées et le degré d'autonomie démontré.
Les métriques essentielles pour évaluer un agent
L'évaluation d'un agent IA s'articule autour de plusieurs familles de métriques qui, ensemble, fournissent une vision complète de sa performance opérationnelle.

Taux de succès et complétion
Le Agent Success Rate (taux de succès de l'agent) constitue la métrique la plus fondamentale. Elle mesure le pourcentage de tâches correctement accomplies par rapport au nombre total de tâches tentées. Une tâche est considérée comme réussie lorsque l'agent atteint l'objectif défini selon des critères préétablis.
Par exemple, sur 100 demandes de type "Réserve une salle de réunion pour demain à 14h", si l'agent effectue correctement la réservation 87 fois, son taux de succès est de 87%. Cette métrique simple mais puissante révèle immédiatement la fiabilité opérationnelle de l'agent.
Le Task Completion Rate (taux de complétion) apporte une nuance importante en mesurant la proportion de tâches qui arrivent à leur terme, indépendamment de leur réussite. Un agent peut échouer à accomplir une tâche tout en la complétant (mauvais résultat), ou abandonner en cours de route (tâche non complétée). Si un agent abandonne 15 fois sur 100 tentatives, son taux de complétion est de 85%, même si parmi les 85 tâches complétées, certaines peuvent avoir échoué.
La distinction entre ces deux métriques est cruciale :
- Un faible taux de succès avec un haut taux de complétion suggère des problèmes de raisonnement ou de choix d'actions
- Un faible taux de complétion indique des problèmes de robustesse : boucles infinies, erreurs non gérées, timeouts
Efficacité et économie d'actions
Le Steps per Task (nombre d'étapes par tâche) mesure l'efficacité de l'agent en comptabilisant le nombre d'actions nécessaires pour accomplir une tâche. Un agent efficace minimise les étapes superflues tout en atteignant son objectif.
Considérons un agent devant récupérer la météo d'une ville :
- Agent A : interroge directement l'API météo → 1 étape
- Agent B : recherche d'abord des informations sur la ville, puis le fuseau horaire, puis appelle l'API météo, vérifie le résultat, reformate la réponse → 5 étapes
Les deux agents peuvent réussir la tâche, mais l'Agent A démontre une efficacité supérieure. Cette métrique impacte directement les coûts opérationnels (appels LLM, appels API) et la latence perçue par l'utilisateur.
Il est pertinent de calculer cette métrique en distinguant :
- Étapes moyennes pour les succès : efficacité dans le cas nominal
- Étapes moyennes pour les échecs : permet d'identifier si les échecs surviennent après de longues séquences d'actions (agent qui s'entête) ou rapidement (agent qui abandonne prématurément)
Autonomie et interactions humaines
Le Number of Human Requests (nombre de requêtes à l'humain) quantifie les fois où l'agent sollicite une clarification ou une intervention de l'utilisateur. Cette métrique reflète le degré d'autonomie de l'agent et son impact sur l'expérience utilisateur.
Certaines demandes de clarification sont légitimes et même souhaitables. Face à une requête ambiguë comme "Envoie les chiffres à Marie", un agent avisé demandera "Quels chiffres souhaitez-vous envoyer ?" plutôt que de faire des suppositions risquées. En revanche, un agent qui sollicite constamment l'utilisateur pour des détails qu'il devrait pouvoir inférer ou trouver par lui-même dégrade l'expérience.
L'analyse de cette métrique doit donc être qualitative :
- Clarifications pertinentes : requêtes sur des informations réellement ambiguës ou manquantes
- Clarifications évitables : questions dont la réponse était accessible via les outils disponibles
- Clarifications excessives : sollicitations répétées qui auraient pu être regroupées
À découvrir : notre formation Agentic AI
Synthèse des métriques principales
| Métrique | Description | Interprétation |
|---|---|---|
| Agent Success Rate | % de tâches réussies | Fiabilité globale de l'agent |
| Task Completion Rate | % de tâches terminées (succès ou échec) | Robustesse et stabilité |
| Steps per Task | Nombre moyen d'actions par tâche | Efficacité opérationnelle |
| Human Requests | Nombre de sollicitations utilisateur | Autonomie et expérience utilisateur |
Ces métriques gagnent en pertinence lorsqu'elles sont analysées conjointement. Un agent avec un excellent taux de succès mais un nombre d'étapes élevé pourrait être optimisé. Un agent très autonome (peu de requêtes humaines) mais avec un faible taux de succès prend probablement trop de risques dans ses interprétations.
Construire un Golden Dataset pour l'évaluation
Les métriques décrites précédemment n'ont de valeur que si elles sont mesurées sur un ensemble de tests représentatif et rigoureux. C'est le rôle du Golden Dataset, un jeu de données de référence conçu spécifiquement pour évaluer la performance de l'agent.
Un Golden Dataset pour agents IA se distingue des datasets classiques par sa structure. Au-delà de paires entrée/sortie attendue, il doit capturer :
- La tâche à accomplir : description claire de l'objectif
- Le contexte initial : état du système, informations disponibles
- Les critères de succès : conditions précises définissant la réussite
- Les trajectoires acceptables : pour certaines tâches, plusieurs chemins peuvent mener au succès
- Les cas limites : situations ambiguës, erreurs à gérer gracieusement
La construction d'un Golden Dataset robuste suit généralement ces étapes :
- Identification des cas d'usage : cartographier les types de tâches que l'agent doit accomplir en production
- Échantillonnage représentatif : sélectionner des exemples couvrant la diversité des situations rencontrées
- Définition des critères : pour chaque exemple, spécifier précisément ce qui constitue un succès
- Validation humaine : faire vérifier le dataset par des experts du domaine
- Enrichissement continu : ajouter régulièrement de nouveaux cas, notamment ceux ayant posé problème en production
# Structure type d'un exemple dans un Golden Dataset pour agent
golden_example = {
"task_id": "booking_001",
"instruction": "Réserve la salle Einstein pour une réunion de 2h demain à 14h avec 5 participants",
"context": {
"available_rooms": ["Einstein", "Curie", "Newton"],
"user_calendar": {...},
"current_datetime": "2025-01-14T10:00:00"
},
"success_criteria": {
"room_booked": "Einstein",
"date": "2025-01-15",
"start_time": "14:00",
"duration_hours": 2,
"participants_notified": True
},
"max_acceptable_steps": 4,
"difficulty": "standard"
}
python
La taille du Golden Dataset dépend de la complexité de l'agent et de la diversité des tâches. Un minimum de 100 à 200 exemples par catégorie de tâche permet généralement d'obtenir des métriques statistiquement significatives. Pour des agents critiques, des datasets de plusieurs milliers d'exemples ne sont pas rares.
Outillage et suivi en production
L'évaluation ne s'arrête pas au développement. En production, le suivi continu des performances permet de détecter les dérives et d'identifier les axes d'amélioration. Des outils comme Langfuse offrent les capacités nécessaires pour instrumenter et monitorer les agents IA.
L'instrumentation d'un agent en production implique de tracer :
- Chaque invocation de l'agent avec ses paramètres d'entrée
- Les étapes intermédiaires du raisonnement (thoughts, actions, observations)
- Les appels aux outils externes avec leurs latences et résultats
- Le résultat final et son évaluation (succès/échec si déterminable automatiquement)
Ces traces permettent de calculer les métriques d'évaluation en continu et d'alerter lorsque les performances se dégradent. Une chute soudaine du taux de succès peut signaler un problème avec un outil externe, une modification non anticipée dans les données, ou une régression suite à une mise à jour du modèle.
L'analyse des traces d'échec est particulièrement précieuse. En examinant les trajectoires des tâches échouées, on peut identifier des patterns récurrents :
- L'agent s'engage-t-il dans des boucles improductives ?
- Certains outils échouent-ils plus souvent que d'autres ?
- Les échecs sont-ils concentrés sur certains types de requêtes ?
Ces insights guident les efforts d'optimisation et l'enrichissement du Golden Dataset avec de nouveaux cas problématiques.
À lire : découvrez notre formation Agentic AI
Conclusion
L'évaluation des agents IA représente un défi méthodologique distinct de l'évaluation des LLM ou des systèmes RAG traditionnels. La nature dynamique et orientée action des agents exige des métriques capturant non seulement la qualité des outputs, mais aussi l'efficacité des trajectoires empruntées et le degré d'autonomie démontré.
Les quatre métriques fondamentales présentées, le taux de succès, le taux de complétion, le nombre d'étapes par tâche et le nombre de requêtes humaines, constituent le socle d'une évaluation rigoureuse. Leur interprétation conjointe révèle les forces et faiblesses d'un agent bien plus finement qu'une métrique isolée.
La construction d'un Golden Dataset adapté et l'instrumentation en production via des outils comme Langfuse complètent ce dispositif d'évaluation. Ensemble, ces éléments permettent non seulement de mesurer la performance actuelle, mais aussi de piloter l'amélioration continue des agents IA.
À mesure que les architectures agentiques se complexifient, avec des systèmes multi-agents, des superviseurs et des workflows sophistiqués, les approches d'évaluation devront elles aussi évoluer. Maîtriser ces fondamentaux constitue un prérequis essentiel pour les équipes qui construisent des agents IA destinés à opérer de manière fiable dans des environnements de production exigeants.


