Langfuse : monitorer des LLM
Langfuse est une plateforme d'observabilité et de monitoring spécialement conçue pour les applications utilisant des LLM. Développée en open source, elle permet aux équipes de développement de suivre, analyser et améliorer leurs systèmes d'IA générative tout au long de leur cycle de vie.

Le déploiement de LLM et d'agents IA en production soulève un défi majeur : comment s'assurer que ces systèmes fonctionnent correctement une fois en conditions réelles ? Contrairement aux applications traditionnelles où les logs et métriques suffisent généralement, les applications basées sur l'IA générative présentent des comportements complexes et parfois imprévisibles qui nécessitent des outils de monitoring adaptés.
C'est dans ce contexte que Langfuse s'est imposé comme une solution de référence pour l'observabilité des applications LLM. Cette plateforme open source permet de tracer, évaluer et optimiser les interactions avec les modèles de langage, offrant aux équipes une visibilité complète sur le comportement de leurs systèmes d'IA.
Que vous développiez un simple chatbot ou une architecture Agentic AI complexe, la capacité à comprendre ce qui se passe "sous le capot" devient rapidement indispensable. Dans cet article, nous allons explorer Langfuse en détail, de ses fonctionnalités d'observabilité à sa gestion des prompts, en passant par ses capacités d'évaluation.
Qu'est-ce que Langfuse ?
Langfuse est une plateforme d'observabilité et de monitoring spécialement conçue pour les applications utilisant des LLM. Développée en open source, elle permet aux équipes de développement de suivre, analyser et améliorer leurs systèmes d'IA générative tout au long de leur cycle de vie.
L'outil répond à une problématique centrale : les applications LLM sont fondamentalement différentes des logiciels classiques. Une même requête peut produire des résultats variables, les coûts dépendent directement du nombre de tokens consommés, et la qualité des réponses est souvent difficile à évaluer de manière automatique. Langfuse adresse ces défis en proposant une suite complète de fonctionnalités.
- Traçabilité complète : chaque appel au LLM est enregistré avec son contexte, ses entrées, ses sorties et ses métadonnées.
- Analyse des coûts : suivi précis de la consommation de tokens et des coûts associés par modèle, par fonctionnalité ou par utilisateur.
- Évaluation de la qualité : mécanismes pour noter et évaluer les réponses, que ce soit manuellement ou automatiquement.
- Gestion des prompts : versioning et déploiement centralisé des prompts utilisés par l'application.
Langfuse s'intègre facilement avec les frameworks populaires comme LangChain, LlamaIndex ou le SDK OpenAI, et peut être déployé en self-hosted ou utilisé via leur offre cloud. Cette flexibilité en fait un choix adapté aussi bien aux startups qu'aux grandes entreprises soucieuses de la confidentialité de leurs données.
from langfuse import Langfuse
# Initialisation du client Langfuse
langfuse = Langfuse(
public_key="pk-...",
secret_key="sk-...",
host="https://cloud.langfuse.com"
)
# Création d'une trace pour suivre une interaction
trace = langfuse.trace(
name="chat-completion",
user_id="user-123",
metadata={"feature": "customer-support"}
)
python
Observabilité des applications LLM
L'observabilité constitue le cœur de Langfuse et répond à une question fondamentale : que se passe-t-il réellement lorsqu'un utilisateur interagit avec votre application IA ?
Traces et spans
Le concept central de Langfuse est la trace, qui représente une exécution complète d'une requête utilisateur. Une trace peut contenir plusieurs spans (ou générations), correspondant aux différentes étapes du traitement. Cette structure hiérarchique est particulièrement utile pour les architectures complexes où une requête déclenche plusieurs appels au LLM.
Pour une application de type agent IA, une trace pourrait par exemple contenir :
- Un span pour l'analyse initiale de la requête
- Plusieurs spans pour les appels aux outils externes
- Un span pour chaque itération de la boucle de raisonnement
- Un span final pour la génération de la réponse
Cette granularité permet d'identifier précisément où se situent les problèmes : latence excessive sur un appel particulier, erreur dans l'utilisation d'un outil, ou réponse de mauvaise qualité à une étape intermédiaire.
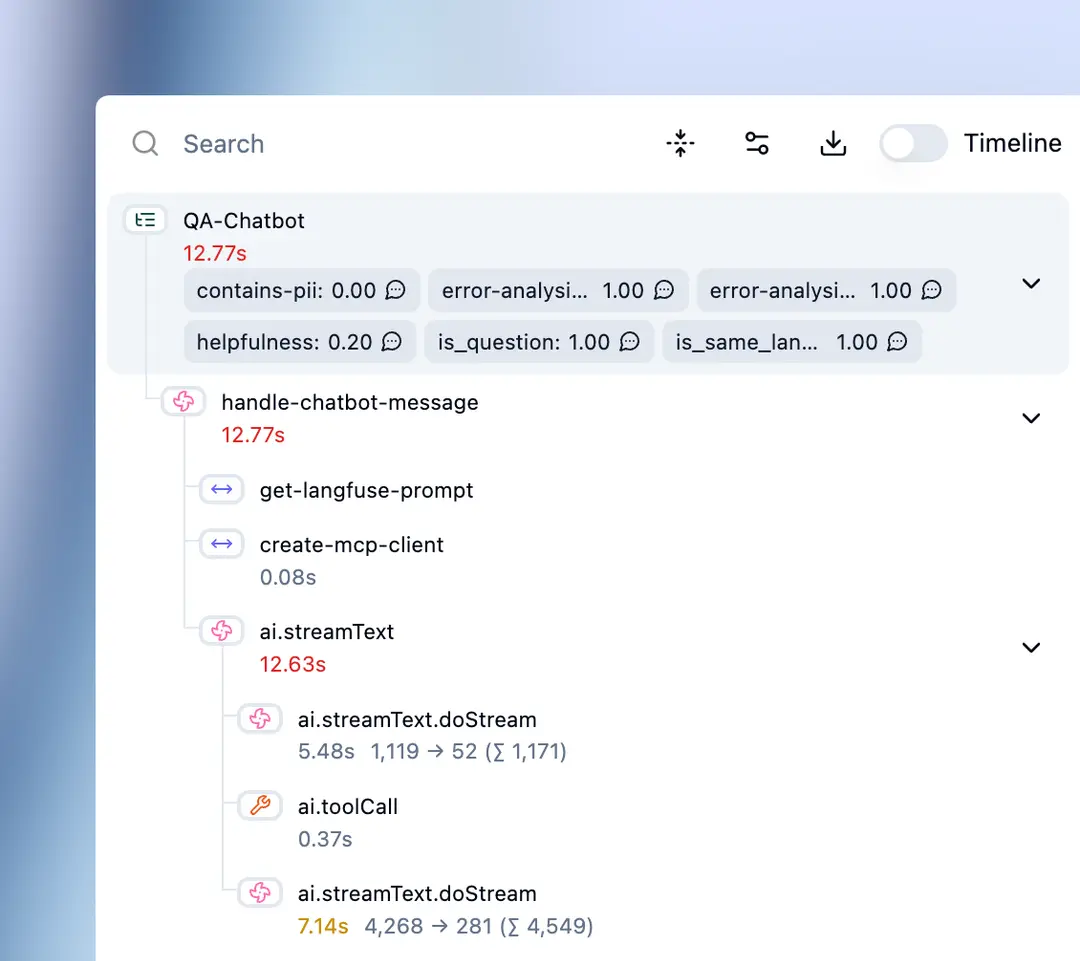
Sessions et contexte utilisateur
Langfuse permet également de regrouper les traces en sessions, ce qui est essentiel pour comprendre le parcours complet d'un utilisateur. Une session peut regrouper toutes les interactions d'une conversation, permettant d'analyser :
- Le nombre moyen d'échanges avant résolution d'une demande
- Les points de friction où les utilisateurs abandonnent
- L'évolution de la qualité des réponses au fil de la conversation
| Métrique | Description | Utilité |
|---|---|---|
| Latence | Temps de réponse de chaque span | Identifier les goulots d'étranglement |
| Tokens | Nombre de tokens en entrée/sortie | Optimiser les coûts |
| Coût | Coût monétaire par trace | Budget et facturation |
| Taux d'erreur | Pourcentage d'appels échoués | Fiabilité du système |
À découvrir : notre formation Agentic AI
Debugging en production
L'un des avantages majeurs de Langfuse réside dans sa capacité à reproduire et analyser les problèmes rencontrés en production. Lorsqu'un utilisateur signale une réponse inappropriée ou incorrecte, il suffit de retrouver la trace correspondante pour examiner :
- Le prompt exact envoyé au modèle
- Les paramètres utilisés (température, max_tokens, etc.)
- La réponse brute du LLM avant tout post-traitement
- Les éventuelles erreurs ou timeouts
Cette transparence accélère considérablement le debugging et permet d'identifier des patterns problématiques qui ne seraient pas visibles autrement.
Évaluation et qualité des réponses
Monitorer les métriques techniques ne suffit pas : il faut également évaluer la qualité des réponses générées. Langfuse propose plusieurs approches complémentaires pour répondre à ce besoin.
Scores et annotations manuelles
La méthode la plus directe consiste à permettre aux humains d'évaluer les réponses. Langfuse offre une interface pour annoter les traces avec des scores personnalisables. Ces annotations peuvent provenir de différentes sources :
- Feedback utilisateur : boutons "pouce en haut/bas" intégrés à l'interface de votre application
- Revue par des experts : évaluation qualitative par des membres de l'équipe
- Quality Assurance : audits réguliers sur un échantillon de traces
Les scores peuvent être numériques (de 1 à 5), binaires (correct/incorrect) ou catégoriels (pertinent, partiellement pertinent, hors sujet). Cette flexibilité permet d'adapter l'évaluation aux spécificités de chaque cas d'usage.
LLM as a Judge
Pour automatiser l'évaluation à grande échelle, Langfuse supporte l'approche LLM as a Judge, où un modèle de langage est utilisé pour évaluer les réponses d'un autre modèle. Cette technique permet de :
- Évaluer automatiquement 100% des traces en production
- Détecter rapidement les dégradations de qualité
- Comparer objectivement différentes versions de prompts
# Exemple d'évaluation automatique avec LLM as a Judge
evaluation_prompt = """
Évalue la réponse suivante sur une échelle de 1 à 5 :
- 5 : Réponse parfaitement pertinente et complète
- 3 : Réponse acceptable mais améliorable
- 1 : Réponse incorrecte ou hors sujet
Question : {question}
Réponse : {response}
Score (1-5) :
"""
python
L'évaluation automatique présente toutefois des limites : le LLM évaluateur peut lui-même faire des erreurs, et certains aspects qualitatifs (ton, style, nuances culturelles) restent difficiles à capturer. Une approche hybride combinant évaluation automatique et revue humaine sur les cas ambigus offre généralement le meilleur compromis.
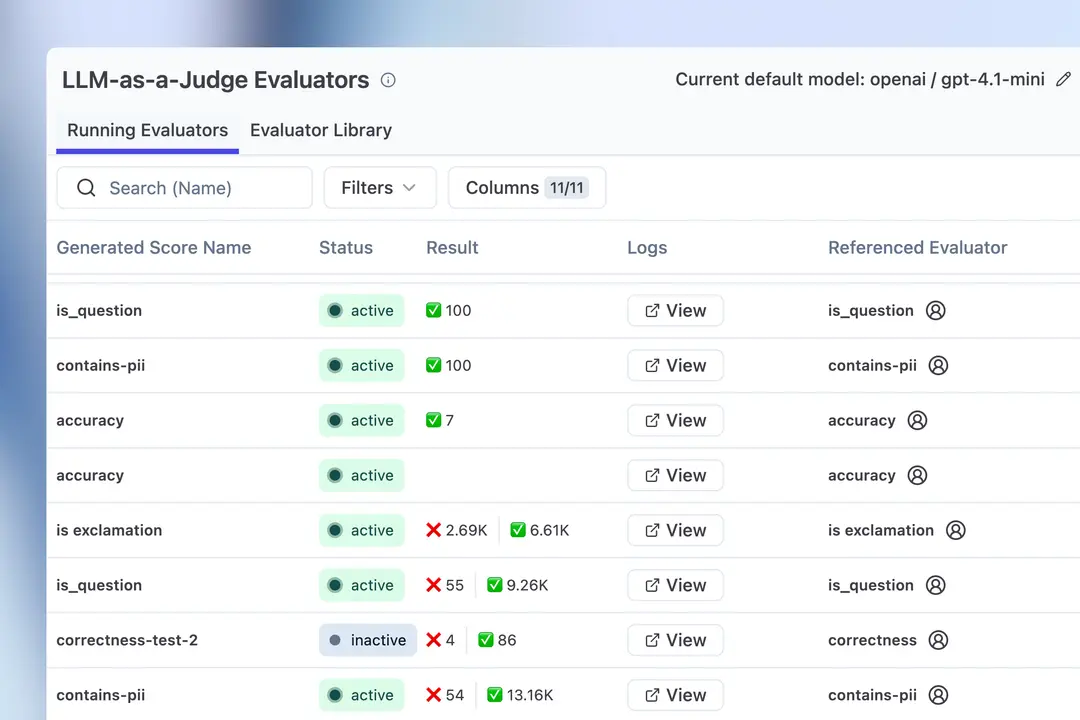
Datasets et benchmarking
Langfuse permet de constituer des datasets de test à partir de traces réelles ou de cas créés manuellement. Ces datasets servent de référence pour :
- Tester les nouvelles versions de prompts avant déploiement
- Comparer les performances de différents modèles
- Détecter les régressions lors des mises à jour
Cette approche de benchmarking continu est essentielle pour maintenir la qualité dans le temps et prendre des décisions éclairées sur les évolutions de l'application.
Gestion et versioning des prompts
Le prompt est souvent considéré comme le code source des applications LLM. Sa gestion rigoureuse est donc cruciale, et Langfuse propose des fonctionnalités dédiées à cet effet.
Versioning et historique
Chaque modification d'un prompt peut être versionnée dans Langfuse, créant un historique complet des évolutions. Cette traçabilité permet de :
- Revenir à une version précédente en cas de régression
- Comprendre l'impact de chaque modification sur les performances
- Documenter les raisons des changements
Le versioning s'accompagne d'un système de labels (production, staging, development) qui facilite la gestion des environnements et le déploiement progressif des modifications.
Composabilité et templates
Pour les applications complexes utilisant plusieurs prompts, Langfuse permet de gérer des templates composables. Un prompt peut référencer des variables, des fragments réutilisables ou des instructions conditionnelles, réduisant la duplication et facilitant la maintenance.
À lire : découvrez notre formation Agentic AI
A/B Testing
La fonctionnalité d'A/B testing permet de comparer différentes versions de prompts sur le trafic réel. En répartissant les utilisateurs entre plusieurs variantes, il devient possible de mesurer objectivement l'impact des modifications sur les métriques clés (satisfaction utilisateur, taux de résolution, coût par interaction).
Cette approche data-driven évite les décisions basées sur l'intuition et permet d'itérer rapidement vers des prompts optimaux. Les résultats des tests sont directement visibles dans le dashboard Langfuse, avec des statistiques de significativité pour guider la prise de décision.
Conclusion
Langfuse répond à un besoin devenu incontournable pour toute équipe déployant des applications LLM en production : comprendre, évaluer et améliorer le comportement de ces systèmes complexes. En combinant observabilité fine, évaluation multi-dimensionnelle et gestion rigoureuse des prompts, la plateforme offre une vision complète du cycle de vie des applications d'IA générative.
L'adoption d'un outil comme Langfuse s'inscrit dans une démarche de professionnalisation du développement IA. Au-delà du simple debugging, il permet d'instaurer des pratiques d'amélioration continue basées sur des données concrètes plutôt que sur des intuitions. Cette approche devient particulièrement critique lorsque les applications gagnent en complexité, notamment avec les architectures multi-agents où les interactions entre composants multiplient les points de défaillance potentiels.
Que vous débutiez avec un prototype ou que vous opériez une application LLM à grande échelle, investir dans l'observabilité dès les premières étapes vous évitera bien des difficultés par la suite. Langfuse, par sa nature open source et sa facilité d'intégration, constitue un excellent point de départ pour structurer cette démarche de monitoring et d'amélioration continue.


