Multi-Query Retriever dans un RAG : pourquoi l'utiliser ?
L'efficacité d'un système RAG repose en grande partie sur la qualité de la récupération de documents. Pourtant, une limitation fondamentale persiste : la requête initiale de l'utilisateur ne capture pas toujours l'ensemble des informations nécessaires pour obtenir une réponse complète. Un utilisateur qui demande 'Quels sont les avantages du télétravail ?' s'attend implicitement à des informations sur la productivité, l'équilibre vie professionnelle, les économies réalisées, ou encore l'impact environnemental, autant d'angles que sa question unique ne couvre pas explicitement.
L'efficacité d'un système RAG repose en grande partie sur la qualité de la récupération de documents. Pourtant, une limitation fondamentale persiste : la requête initiale de l'utilisateur ne capture pas toujours l'ensemble des informations nécessaires pour obtenir une réponse complète. Un utilisateur qui demande "Quels sont les avantages du télétravail ?" s'attend implicitement à des informations sur la productivité, l'équilibre vie professionnelle, les économies réalisées, ou encore l'impact environnemental, autant d'angles que sa question unique ne couvre pas explicitement.
C'est précisément ce problème que le Multi-Query Retriever vient résoudre. Cette technique consiste à utiliser un LLM pour générer automatiquement plusieurs reformulations ou sous-questions à partir de la requête originale, puis à exécuter la recherche sur chacune d'elles. En multipliant les perspectives de recherche, on augmente significativement les chances de récupérer l'ensemble des documents pertinents, même ceux qui n'auraient pas été capturés par la formulation initiale.
Cette approche s'inscrit dans une tendance plus large d'amélioration des systèmes RAG au-delà des implémentations naïves. Là où un RAG basique se contente d'encoder la question telle quelle et de récupérer les documents les plus proches sémantiquement, le Multi-Query Retriever ajoute une couche d'intelligence qui compense les limitations inhérentes à une recherche mono-requête.
Dans cet article, nous allons explorer le fonctionnement du Multi-Query Retriever, comprendre pourquoi cette technique améliore la qualité des systèmes RAG, et analyser ses avantages et inconvénients pour déterminer quand l'utiliser dans vos projets.
Le problème du RAG naïf
Un système RAG classique suit un flux simple : la question de l'utilisateur est transformée en vecteur d'embedding, puis comparée aux embeddings des documents indexés pour récupérer les plus similaires. Cette approche fonctionne bien lorsque la question est précise et que les documents pertinents utilisent un vocabulaire proche. Mais elle montre ses limites dans plusieurs situations courantes.
Le premier écueil concerne le vocabulary mismatch. L'utilisateur peut formuler sa question avec des termes différents de ceux présents dans les documents sources. Une question sur "la rémunération des salariés" pourrait manquer des documents parlant de "compensation", "package salarial" ou "avantages sociaux", même si ces documents contiennent exactement l'information recherchée.
Le deuxième problème tient à la complexité implicite des questions. Une question apparemment simple peut en réalité nécessiter des informations provenant de plusieurs angles distincts. "Comment améliorer la performance de mon application ?" implique potentiellement des aspects d'architecture, d'optimisation de code, de configuration serveur, de mise en cache : autant de sujets qui pourraient être traités dans des documents séparés utilisant des vocabulaires différents.
| Limitation du RAG naïf | Conséquence | Solution Multi-Query |
|---|---|---|
| Vocabulary mismatch | Documents pertinents non récupérés | Reformulations avec synonymes |
| Questions complexes | Couverture partielle du sujet | Décomposition en sous-questions |
| Ambiguïté de la requête | Résultats imprécis | Clarification via variantes |
| Perspective unique | Angle de recherche limité | Multiplication des perspectives |
Enfin, la formulation unique de la requête crée un biais de recherche. Les modèles d'embedding, aussi performants soient-ils, encodent une représentation particulière de la question. Certains documents pertinents mais formulés différemment peuvent se retrouver juste en dessous du seuil de similarité et être exclus des résultats.
Comment fonctionne le Multi-Query Retriever
Le Multi-Query Retriever introduit une étape intermédiaire entre la réception de la question et la recherche dans la base vectorielle. Cette étape utilise un LLM pour générer plusieurs variantes de la question originale, chacune explorant un angle ou une formulation différente.
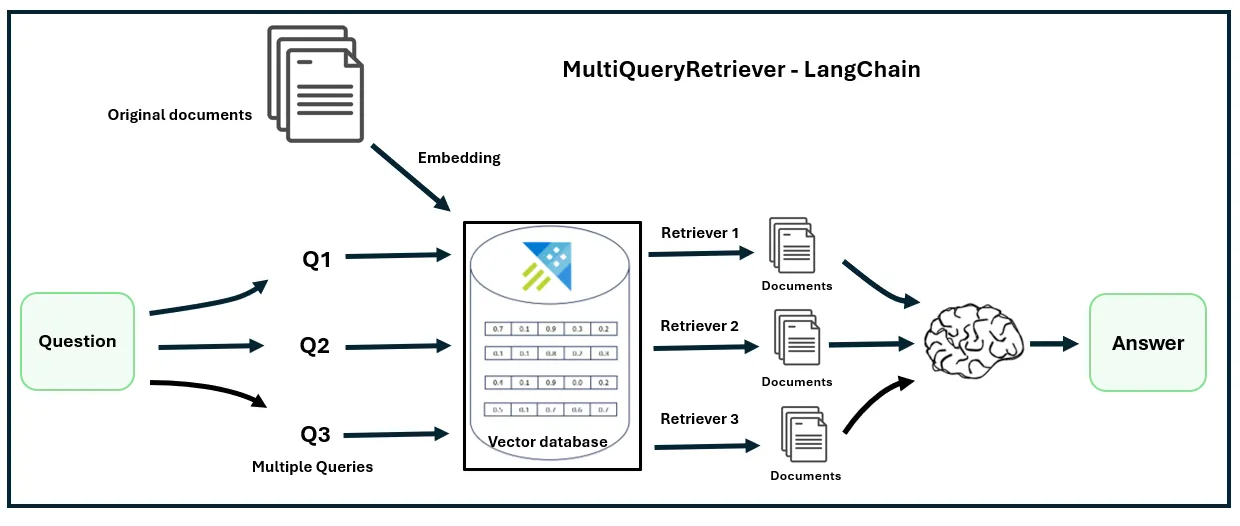
Le processus se déroule en quatre phases distinctes :
-
Génération des requêtes : le LLM reçoit la question initiale et produit plusieurs reformulations. Ces variantes peuvent être des paraphrases, des questions plus spécifiques, ou des sous-questions explorant différents aspects du sujet.
-
Exécution parallèle : chaque requête générée est utilisée pour interroger la base vectorielle. On obtient ainsi plusieurs ensembles de documents, potentiellement avec des recouvrements.
-
Fusion des résultats : les documents récupérés sont agrégés. Les techniques courantes incluent la simple union (tous les documents uniques), le ranking réciproque (Reciprocal Rank Fusion), ou la pondération par fréquence d'apparition.
-
Transmission au LLM : l'ensemble consolidé de documents est fourni au modèle de génération avec la question originale pour produire la réponse finale.
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_openai import ChatOpenAI
# Configuration du retriever multi-query
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
multi_query_retriever = MultiQueryRetriever.from_llm(
retriever=base_vectorstore.as_retriever(search_kwargs={"k": 4}),
llm=llm
)
# La requête unique génère automatiquement plusieurs variantes
docs = multi_query_retriever.invoke("Quels sont les avantages du télétravail ?")
# En interne, le LLM a pu générer :
# - "Quels bénéfices le travail à distance apporte-t-il aux employés ?"
# - "Comment le télétravail impacte-t-il la productivité ?"
# - "Quels sont les avantages économiques du travail depuis chez soi ?"
python
La qualité des requêtes générées dépend du prompt utilisé pour instruire le LLM. Un prompt bien conçu encourage la diversité des angles tout en maintenant la pertinence par rapport à la question originale. Les frameworks comme LangChain fournissent des implémentations prêtes à l'emploi avec des prompts optimisés, mais la personnalisation reste possible pour des cas d'usage spécifiques.
À découvrir : notre formation LLM Engineering
Avantages et cas d'usage
L'adoption du Multi-Query Retriever apporte des bénéfices mesurables dans plusieurs dimensions de la qualité d'un système RAG.
Le gain le plus immédiat concerne le recall : c'est la capacité à récupérer tous les documents pertinents. En multipliant les angles de recherche, on réduit drastiquement le risque de manquer des documents importants à cause d'une formulation malheureuse. Les tests empiriques montrent des améliorations de recall de 15 à 30% sur des benchmarks standards, particulièrement sur les questions complexes ou ambiguës.
La robustesse face aux variations linguistiques constitue un autre atout majeur. Les utilisateurs d'un système RAG ne sont pas des experts en formulation de requêtes. Certains posent des questions vagues, d'autres utilisent un jargon spécifique, d'autres encore formulent des demandes indirectes. Le Multi-Query Retriever compense ces variations en générant des reformulations standardisées qui couvrent le spectre sémantique de la question.
Les cas d'usage où cette technique excelle incluent :
- Bases de connaissances hétérogènes : quand les documents proviennent de sources variées avec des vocabulaires différents (documentation technique, FAQ, articles de blog)
- Questions exploratoires : quand l'utilisateur cherche une vue d'ensemble plutôt qu'une information précise
- Domaines spécialisés : quand le vocabulaire métier peut différer entre la question de l'utilisateur et les documents sources
- Support client : quand les questions sont souvent formulées de manière imprécise ou émotionnelle
La technique se marie particulièrement bien avec d'autres améliorations du RAG comme le reranking ou le RAG Fusion, permettant de construire des pipelines sophistiqués où chaque étape compense les faiblesses des autres.
Limites et considérations pratiques
Malgré ses avantages, le Multi-Query Retriever introduit des compromis qu'il convient d'évaluer avant adoption.
Le coût computationnel augmente mécaniquement. Chaque requête implique un appel au LLM pour la génération des variantes, puis plusieurs recherches vectorielles au lieu d'une seule. Pour un système à fort trafic, cette multiplication peut impacter significativement les coûts d'API et la latence. En pratique, la génération de 3 à 5 variantes représente un bon compromis entre diversité et coût.
La latence s'en trouve également affectée. L'appel LLM pour générer les sous-questions ajoute typiquement 200 à 500ms au temps de réponse. Les recherches vectorielles peuvent être parallélisées, mais l'étape de génération reste séquentielle. Pour des applications où la réactivité est critique, cette latence additionnelle peut être problématique.
| Aspect | Impact | Mitigation |
|---|---|---|
| Coût API | +1 appel LLM par requête | Utiliser un modèle léger pour la génération |
| Latence | +200-500ms typiquement | Paralléliser les recherches, cacher les patterns fréquents |
| Complexité | Pipeline plus sophistiqué | S'appuyer sur des frameworks éprouvés |
| Bruit potentiel | Requêtes générées hors sujet | Affiner le prompt de génération |
La qualité des requêtes générées n'est pas garantie. Un LLM peut occasionnellement produire des reformulations qui s'éloignent du sens original ou qui introduisent des biais. Un monitoring des requêtes générées et un ajustement du prompt de génération permettent de corriger ces dérives.
Enfin, le Multi-Query Retriever n'est pas toujours nécessaire. Pour des questions simples et factuelles ("Quel est le numéro de téléphone du support ?"), la complexité additionnelle n'apporte pas de valeur. L'idéal est de détecter dynamiquement les requêtes qui bénéficieraient de cette technique et de l'appliquer sélectivement.
Conclusion
Le Multi-Query Retriever représente une évolution naturelle des systèmes RAG vers plus d'intelligence dans la phase de récupération. En reconnaissant qu'une question unique ne capture pas toujours la richesse de l'intention utilisateur, cette technique exploite les capacités de reformulation des LLM pour multiplier les perspectives de recherche et maximiser le recall.
L'implémentation est aujourd'hui facilitée par des frameworks comme LangChain ou LlamaIndex qui proposent des abstractions prêtes à l'emploi. Pour les équipes qui constatent des limitations dans leur système RAG actuel (documents pertinents manqués, sensibilité excessive à la formulation des questions, couverture incomplète des sujets complexes) le Multi-Query Retriever offre une solution éprouvée avec un rapport effort/bénéfice favorable.
Comme toute amélioration, elle s'inscrit dans une stratégie d'optimisation globale du pipeline RAG. Combinée à un bon chunking des documents, à des embeddings de qualité, et éventuellement à une étape de reranking, le Multi-Query Retriever contribue à construire des systèmes de génération augmentée qui répondent véritablement aux attentes des utilisateurs (même lorsque leurs questions ne sont pas parfaitement formulées).


