Reasoning models : comment ça fonctionne
Les Reasoning Models (modèles de raisonnement) représentent une nouvelle génération de LLM conçus pour surmonter cette limitation. OpenAI a ouvert la voie avec o1 en septembre 2024, suivi par o3 et o4-mini. DeepSeek a marqué les esprits avec R1, tandis que Google a introduit ses propres modèles de raisonnement dans la famille Gemini. Ces modèles partagent une caractéristique commune : ils "réfléchissent" avant de répondre, en générant une chaîne de pensée interne qui peut durer plusieurs secondes, voire plusieurs minutes pour les problèmes complexes.

Les modèles de langage ont connu une évolution spectaculaire depuis l'arrivée de ChatGPT fin 2022. Pourtant, une limitation fondamentale persistait : ces modèles généraient leurs réponses de manière quasi instantanée, sans véritable phase de réflexion. Un LLM classique prédit le token suivant en une fraction de seconde, ce qui fonctionne remarquablement bien pour de nombreuses tâches, mais atteint ses limites face à des problèmes nécessitant un raisonnement en plusieurs étapes.
Les Reasoning Models (modèles de raisonnement) représentent une nouvelle génération de LLM conçus pour surmonter cette limitation. OpenAI a ouvert la voie avec o1 en septembre 2024, suivi par o3 et o4-mini. DeepSeek a marqué les esprits avec R1, tandis que Google a introduit ses propres modèles de raisonnement dans la famille Gemini. Ces modèles partagent une caractéristique commune : ils "réfléchissent" avant de répondre, en générant une chaîne de pensée interne qui peut durer plusieurs secondes, voire plusieurs minutes pour les problèmes complexes.
Cette capacité de raisonnement prolongé change fondamentalement ce que l'on peut attendre d'un LLM. Des problèmes de mathématiques avancées, de programmation compétitive ou de logique complexe, qui mettaient en échec les modèles classiques, deviennent accessibles. Le compromis est évident : plus de temps de calcul, plus de tokens consommés, mais des résultats qualitativement supérieurs sur les tâches exigeantes.
Dans cet article, nous allons explorer ce qui distingue les Reasoning Models des LLM traditionnels, comprendre les mécanismes qui leur permettent de raisonner, et analyser quand et comment les utiliser efficacement dans vos projets.
Ce qui distingue les Reasoning Models des LLM classiques
Pour comprendre l'innovation que représentent les Reasoning Models, il faut d'abord saisir comment fonctionne un LLM standard. Un modèle comme GPT-4o ou Claude 3.5 Sonnet génère sa réponse token par token, chaque token étant prédit en fonction du contexte précédent. Ce processus est rapide (quelques millisecondes par token) mais ne laisse pas de place à la "réflexion" : le modèle ne peut pas revenir en arrière, explorer différentes pistes, ou vérifier la cohérence de son raisonnement en cours de route.
Cette architecture produit un phénomène que les chercheurs appellent le "System 1 thinking" (en référence aux travaux du psychologue Daniel Kahneman) : des réponses intuitives et rapides, mais parfois superficielles ou erronées face à des problèmes complexes. Demandez à un LLM classique de résoudre un problème de mathématiques en plusieurs étapes, et il peut facilement se tromper à mi-chemin sans possibilité de correction.
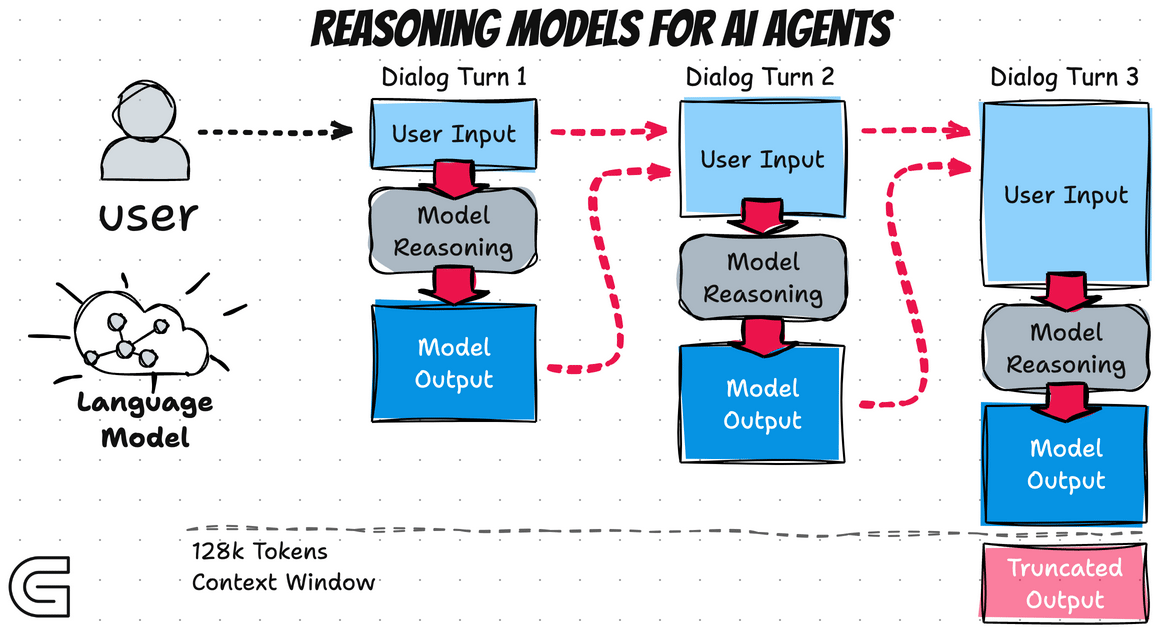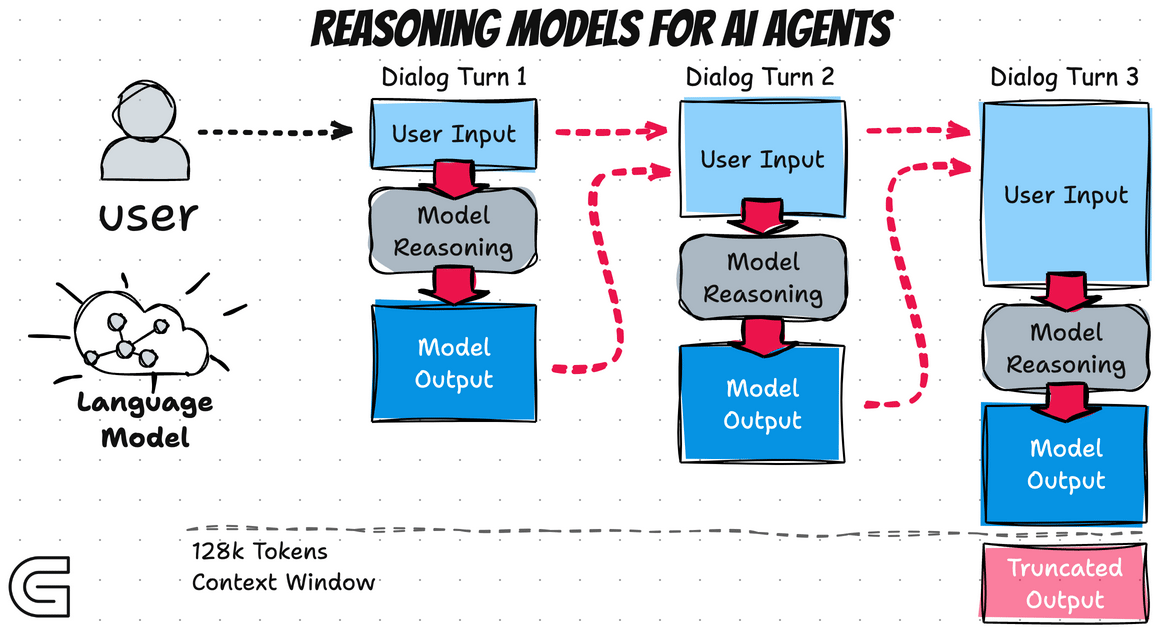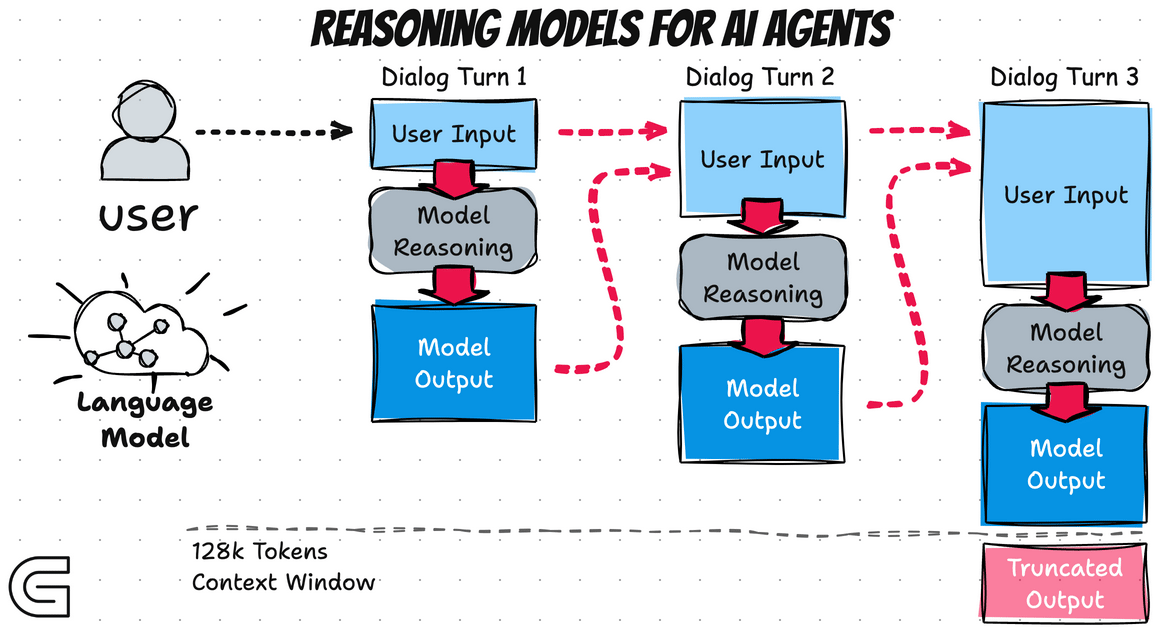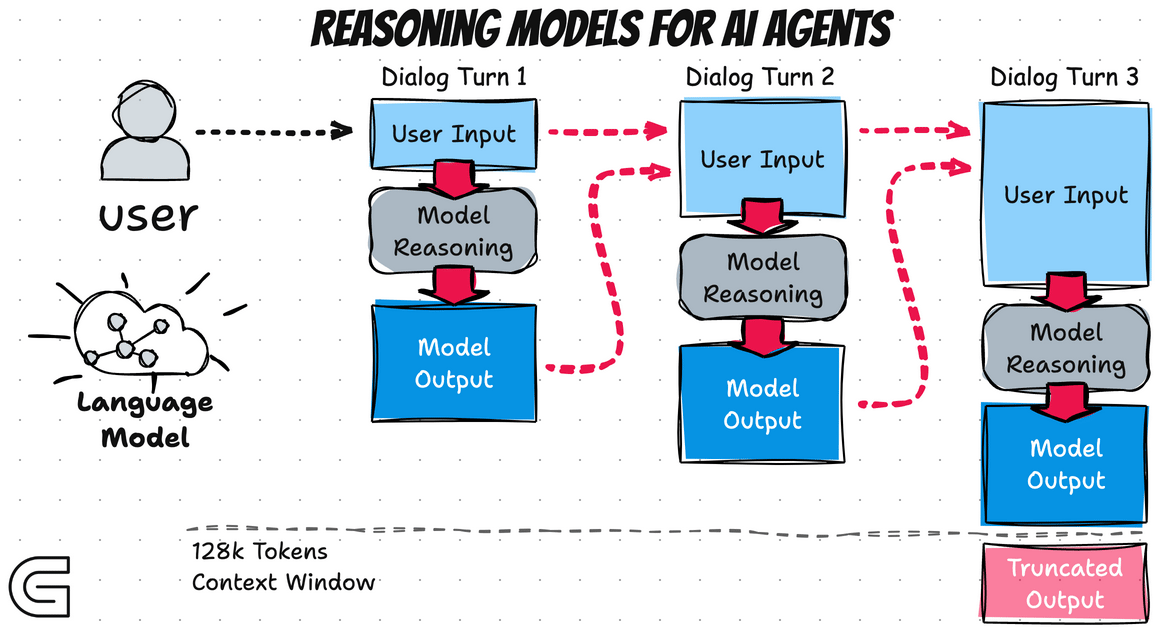
Les Reasoning Models introduisent ce que l'on pourrait appeler un "System 2 thinking" : une réflexion délibérée, méthodique, qui prend le temps d'explorer le problème avant de formuler une réponse. Concrètement, cela se manifeste par une phase de "thinking" visible (ou parfois cachée) où le modèle génère une longue chaîne de raisonnement interne :
- Il décompose le problème en sous-problèmes
- Il explore différentes approches possibles
- Il vérifie la cohérence de ses raisonnements intermédiaires
- Il peut revenir en arrière et corriger ses erreurs
- Il synthétise finalement une réponse après cette exploration
| Caractéristique | LLM classique | Reasoning Model |
|---|---|---|
| Temps de réponse | Quasi instantané | Quelques secondes à plusieurs minutes |
| Tokens générés | Réponse directe | Chaîne de pensée + réponse |
| Vérification interne | Aucune | Auto-correction possible |
| Coût par requête | Modéré | Élevé (plus de tokens) |
| Cas d'usage optimal | Tâches générales, créativité | Problèmes logiques, maths, code complexe |
Cette différence de fonctionnement explique pourquoi les Reasoning Models excellent sur des benchmarks comme les compétitions de mathématiques (AIME, Math Olympiad) ou de programmation (Codeforces), où les LLM classiques plafonnaient. Sur ces tâches, la capacité à "réfléchir plus longtemps" se traduit directement en meilleurs résultats.
Les mécanismes du raisonnement
Le fonctionnement interne des Reasoning Models repose sur plusieurs innovations techniques qui leur permettent d'aller au-delà de la simple prédiction du token suivant.
Le Chain-of-Thought à grande échelle
La technique du Chain-of-Thought (CoT) n'est pas nouvelle : elle consiste à demander au modèle de raisonner étape par étape avant de donner sa réponse finale. Ce qui change avec les Reasoning Models, c'est que ce raisonnement est internalisé et optimisé lors de l'entraînement, plutôt que simplement induit par le prompt.
Les modèles comme o1 ou DeepSeek R1 ont été entraînés avec des techniques de reinforcement learning (RL) qui récompensent non seulement la justesse de la réponse finale, mais aussi la qualité du raisonnement intermédiaire. Le modèle apprend ainsi à produire des chaînes de pensée efficaces, à identifier ses erreurs, et à explorer méthodiquement l'espace des solutions.
La chaîne de pensée générée peut être considérable. Pour un problème de mathématiques complexe, un Reasoning Model peut générer plusieurs milliers de tokens de raisonnement interne avant de produire une réponse de quelques lignes. Cette "réflexion" n'est pas du remplissage : chaque étape contribue à affiner la compréhension du problème et à valider les hypothèses intermédiaires.
Le concept de Test-Time Compute
Une innovation majeure des Reasoning Models est l'utilisation intensive du Test-Time Compute (calcul au moment de l'inférence). Traditionnellement, la puissance d'un LLM était déterminée principalement par son entraînement : plus de données, plus de paramètres, plus de compute à l'entraînement. Les Reasoning Models ajoutent une nouvelle dimension en permettant d'investir plus de calcul au moment de la requête.
Cette approche s'inscrit dans une tendance identifiée par les chercheurs : à partir d'un certain niveau de performance, il devient plus efficace d'augmenter le temps de réflexion que d'augmenter la taille du modèle. Un modèle de taille moyenne qui "réfléchit" pendant 30 secondes peut surpasser un modèle bien plus gros qui répond instantanément.
Les implications sont significatives pour l'utilisation pratique :
- Le coût d'une requête devient variable et potentiellement élevé
- Le temps de réponse n'est plus prévisible
- La qualité du résultat peut être ajustée en permettant plus ou moins de "réflexion"
Certains providers exposent d'ailleurs des paramètres pour contrôler cet arbitrage. Avec les modèles o3 ou o4-mini d'OpenAI, on peut par exemple choisir entre différents niveaux de "reasoning effort" qui influencent directement le temps de calcul et la qualité des résultats.
L'entraînement par renforcement
L'utilisation du reinforcement learning (RL) constitue un ingrédient clé dans la création des Reasoning Models. Contrairement au pre-training classique qui apprend à prédire le token suivant sur de vastes corpus, le RL permet d'optimiser directement pour des objectifs complexes comme "résoudre correctement ce problème de mathématiques".
DeepSeek a publié des détails techniques sur l'entraînement de R1 qui illustrent cette approche. Le modèle est d'abord pré-entraîné de manière classique, puis affiné via RL sur des tâches de raisonnement. Les récompenses sont attribuées en fonction de la justesse des réponses finales, mais aussi de la qualité des étapes intermédiaires. Le modèle apprend ainsi à :
- Générer des chaînes de pensée structurées et vérifiables
- Identifier et corriger ses propres erreurs en cours de raisonnement
- Explorer efficacement différentes approches avant de converger
- Savoir quand il a suffisamment réfléchi pour répondre avec confiance
À découvrir : notre formation LLM Engineering
Quand utiliser les Reasoning Models
Les Reasoning Models ne sont pas destinés à remplacer les LLM classiques pour toutes les tâches. Leur utilisation optimale dépend de la nature du problème à résoudre et des contraintes de votre application.
Les cas d'usage où les Reasoning Models excellent incluent :
- Mathématiques et sciences : résolution de problèmes complexes en plusieurs étapes, démonstrations, calculs avancés
- Programmation difficile : algorithmes complexes, optimisation, debugging de problèmes subtils
- Raisonnement logique : puzzles, problèmes de contraintes, analyse de scénarios
- Analyse approfondie : évaluation de documents complexes, comparaison de multiples options avec critères croisés
- Planification : élaboration de stratégies en plusieurs étapes avec anticipation des conséquences
En revanche, les LLM classiques restent plus appropriés pour :
- Tâches conversationnelles : chatbots, assistants, où la réactivité prime
- Génération créative : rédaction, brainstorming, où la réflexion prolongée n'apporte pas de valeur ajoutée
- Requêtes simples : questions factuelles, reformulations, traductions
- Applications à fort volume : quand le coût et la latence sont des contraintes fortes
L'arbitrage se résume souvent à une question simple : le problème bénéficie-t-il réellement d'une réflexion prolongée ? Si la réponse peut être donnée correctement par un modèle classique en une fraction de seconde, utiliser un Reasoning Model ne fait qu'augmenter les coûts et la latence sans améliorer le résultat.
Dans la pratique, de nombreuses applications combinent les deux types de modèles. Un système peut utiliser un LLM classique pour la majorité des interactions, et basculer vers un Reasoning Model uniquement pour les requêtes identifiées comme nécessitant un raisonnement approfondi. Cette approche hybride optimise le rapport qualité/coût tout en garantissant des performances optimales sur les tâches exigeantes.
Les frameworks comme LangChain facilitent cette orchestration en permettant de router dynamiquement les requêtes vers différents modèles selon leur nature. Un classifier léger peut analyser la requête entrante et décider si elle justifie l'utilisation d'un Reasoning Model, permettant une allocation intelligente des ressources.
Conclusion
Les Reasoning Models représentent une évolution majeure dans les capacités des LLM, ouvrant la voie à des applications qui étaient hors de portée des modèles classiques. En introduisant une véritable phase de réflexion avant la génération de la réponse, ces modèles peuvent s'attaquer à des problèmes complexes de mathématiques, de logique ou de programmation avec une efficacité sans précédent.
Cette avancée ne vient pas sans contreparties. Le temps de réponse augmenté, la consommation de tokens démultipliée, et les coûts associés imposent une utilisation réfléchie. Les Reasoning Models ne sont pas des remplaçants universels des LLM classiques, mais plutôt des outils spécialisés à déployer sur les tâches qui justifient leur puissance de raisonnement.
Pour les équipes qui développent des applications d'IA, la disponibilité de ces modèles élargit considérablement le champ des possibles. Des assistants capables de résoudre des problèmes techniques complexes, des systèmes d'analyse approfondie, ou des agents autonomes capables de planification sophistiquée deviennent réalisables. L'enjeu est désormais de savoir identifier les cas d'usage où cette capacité de raisonnement crée véritablement de la valeur, et d'architecturer des systèmes qui combinent intelligemment différents types de modèles selon les besoins.