Reflection et self-critique : comment les agents s'auto-corrigent
Les architectures d'agents IA ont considérablement progressé dans leur capacité à résoudre des problèmes complexes. Les patterns ReAct et Plan-and-Execute ont démontré comment un agent peut raisonner et agir de manière itérative. Pourtant, une limitation persistait : ces agents avancent sans jamais remettre en question la qualité de leur propre travail. Un agent ReAct qui produit une réponse incorrecte à l'étape 3 continuera à construire sur cette erreur jusqu'à la fin de son exécution.

Les architectures d'agents IA ont considérablement progressé dans leur capacité à résoudre des problèmes complexes. Les patterns ReAct et Plan-and-Execute ont démontré comment un agent peut raisonner et agir de manière itérative. Pourtant, une limitation persistait : ces agents avancent sans jamais remettre en question la qualité de leur propre travail. Un agent ReAct qui produit une réponse incorrecte à l'étape 3 continuera à construire sur cette erreur jusqu'à la fin de son exécution.
C'est précisément ce problème que les patterns de reflection et de self-critique cherchent à résoudre. L'idée fondamentale est simple mais puissante : plutôt que de considérer la première réponse générée comme définitive, l'agent prend du recul, évalue critiquement son propre output, identifie les faiblesses potentielles, puis révise sa réponse en conséquence. Ce mécanisme d'auto-correction reproduit un comportement naturel chez les experts humains, qui relisent et affinent systématiquement leur travail avant de le considérer comme terminé.
Cette capacité réflexive transforme la dynamique de génération des LLM. Au lieu d'un flux linéaire où chaque token est produit sans retour possible, l'agent entre dans une boucle d'amélioration continue. La première réponse devient un brouillon que l'agent critique et perfectionne, parfois sur plusieurs itérations, jusqu'à atteindre un niveau de qualité satisfaisant. Dans cet article, nous allons explorer les mécanismes qui permettent aux agents de s'auto-évaluer et de s'auto-corriger, les différentes stratégies d'implémentation de ces patterns, et les contextes où cette approche apporte une valeur ajoutée significative.
Comprendre les mécanismes de reflection et self-critique
La reflection dans les systèmes d'agents IA désigne la capacité d'un agent à examiner son propre raisonnement et ses outputs pour en évaluer la qualité. Ce processus s'inspire directement de la métacognition humaine : cette aptitude à "penser sur sa propre pensée" qui permet aux experts de détecter leurs erreurs et d'améliorer leurs productions.
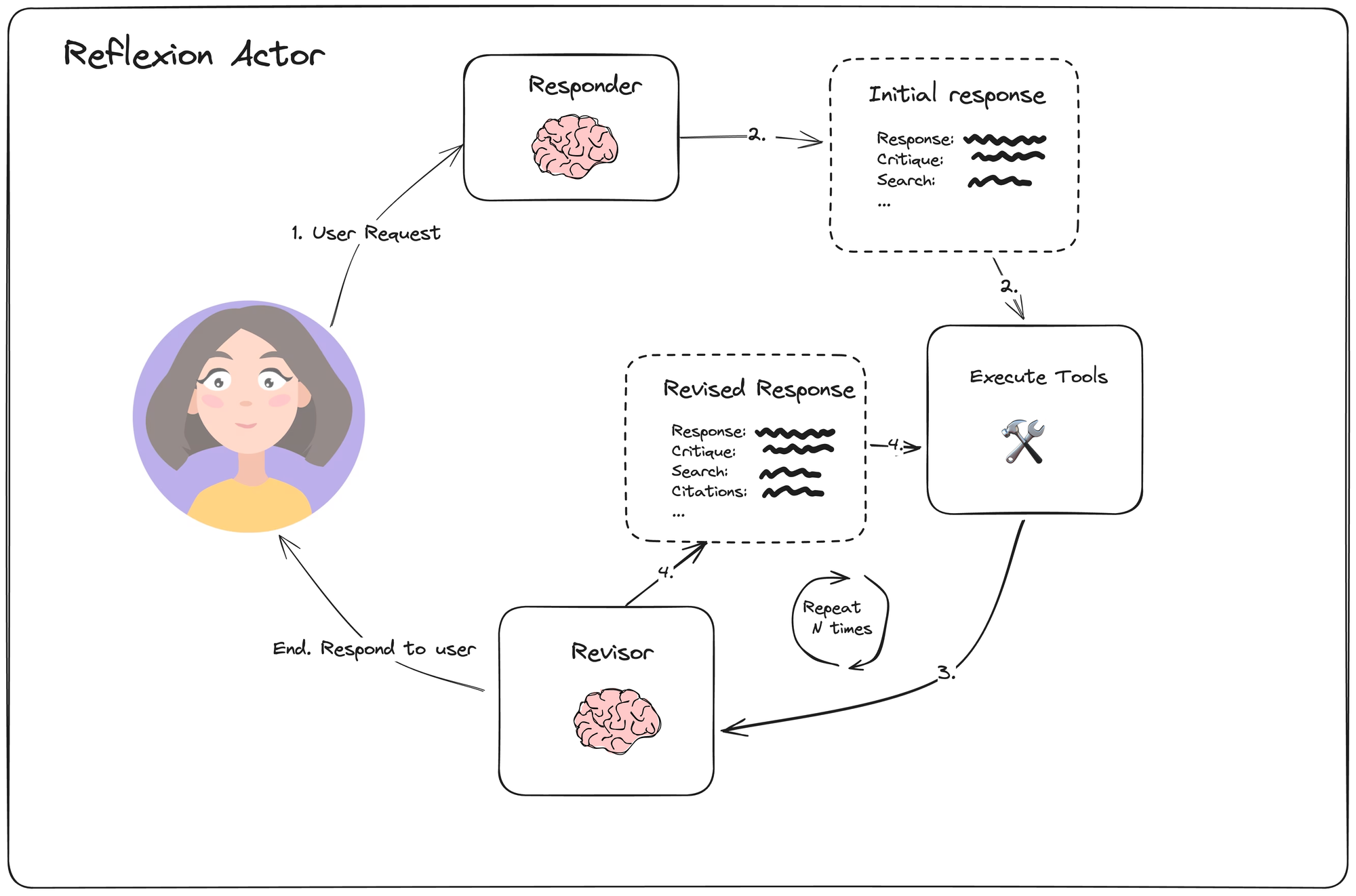
Le mécanisme de base fonctionne en plusieurs phases distinctes. L'agent génère d'abord une réponse initiale à la requête de l'utilisateur, en utilisant ses capacités standard (raisonnement, tool calling, accès à des connaissances). Cette réponse est ensuite soumise à un processus d'évaluation critique où l'agent, guidé par des critères explicites, analyse les forces et faiblesses de sa propre production. Sur la base de cette analyse, l'agent décide soit de valider la réponse, soit de la réviser en tenant compte des problèmes identifiés.
Exemple de flux de reflection :
Requête : "Explique les avantages du pattern Repository en programmation"
Réponse initiale : "Le pattern Repository permet de séparer la logique métier
de l'accès aux données. Il offre une interface abstraite pour les opérations CRUD."
Critique interne : "Cette réponse est correcte mais superficielle. Elle ne mentionne
pas les bénéfices pour les tests unitaires, ni la flexibilité pour changer de
source de données. Les exemples concrets sont absents."
Réponse révisée : "Le pattern Repository centralise la logique d'accès aux données
derrière une interface abstraite, ce qui apporte plusieurs avantages clés :
- Testabilité : les tests unitaires peuvent utiliser des implémentations mock
- Flexibilité : changer de base de données ne requiert que de modifier l'implémentation
- Séparation des responsabilités : la logique métier ignore les détails de persistance
Par exemple, une interface UserRepository avec les méthodes findById() et save()
peut avoir une implémentation PostgreSQL en production et une implémentation
en mémoire pour les tests."
plaintext
Ce processus peut être implémenté selon deux approches principales. Dans l'approche single-agent, le même LLM joue alternativement le rôle de générateur et de critique. Le prompt est structuré pour demander explicitement à l'agent d'évaluer sa réponse selon des critères définis. Dans l'approche multi-agent, des agents distincts se spécialisent : un agent générateur produit les réponses tandis qu'un agent critique les évalue, créant une dynamique de collaboration où les rôles sont clairement séparés.
| Approche | Avantages | Inconvénients |
|---|---|---|
| Single-agent | Simplicité, coût réduit, contexte unifié | Biais de confirmation potentiel |
| Multi-agent | Perspectives différenciées, critique plus objective | Coût doublé, complexité accrue |
Les critères d'évaluation utilisés lors de la phase critique varient selon le cas d'usage, mais incluent généralement :
- Exactitude factuelle : les informations présentées sont-elles correctes ?
- Complétude : tous les aspects importants de la question sont-ils couverts ?
- Clarté : la réponse est-elle compréhensible pour l'audience cible ?
- Pertinence : la réponse adresse-t-elle réellement la question posée ?
- Cohérence logique : le raisonnement est-il exempt de contradictions ?
La puissance de ce pattern réside dans sa capacité à capturer des erreurs que l'agent n'aurait pas détectées autrement. Un LLM générant du code peut produire une fonction syntaxiquement correcte mais logiquement erronée. En adoptant une posture critique, ce même LLM peut identifier que la fonction ne gère pas les cas limites ou contient une erreur de logique off-by-one.
Stratégies d'implémentation
Traduire le concept de reflection en système fonctionnel nécessite de choisir parmi plusieurs stratégies d'implémentation, chacune adaptée à des contextes et contraintes spécifiques.
Reflection itérative avec critères explicites
La stratégie la plus directe consiste à structurer le processus en itérations explicites. Après chaque génération, l'agent reçoit un prompt dédié à l'évaluation critique, puis un prompt de révision si des améliorations sont identifiées. Cette approche offre un contrôle fin sur le processus et une traçabilité complète des améliorations successives.
def reflective_generation(query: str, max_iterations: int = 3) -> str:
"""Génère une réponse avec boucle de reflection."""
# Génération initiale
response = llm.generate(f"Réponds à cette question : {query}")
for iteration in range(max_iterations):
# Phase de critique
critique_prompt = f"""
Évalue cette réponse selon les critères suivants :
- Exactitude des informations
- Complétude de la réponse
- Clarté de l'explication
Réponse à évaluer : {response}
Liste les problèmes identifiés et suggère des améliorations.
Si la réponse est satisfaisante, réponds "APPROVED".
"""
critique = llm.generate(critique_prompt)
if "APPROVED" in critique:
break
# Phase de révision
revision_prompt = f"""
Révise cette réponse en tenant compte des critiques suivantes :
Réponse originale : {response}
Critiques : {critique}
Produis une version améliorée.
"""
response = llm.generate(revision_prompt)
return response
python
Le paramètre max_iterations est crucial pour éviter les boucles infinies où l'agent ne serait jamais satisfait de sa réponse. En pratique, 2 à 4 itérations suffisent généralement à capturer les améliorations significatives sans engendrer de coûts excessifs.
Self-consistency et vote majoritaire
Une approche complémentaire consiste à générer plusieurs réponses indépendantes pour la même requête, puis à les comparer pour identifier la plus fiable. Cette stratégie, appelée self-consistency, exploite le fait que les erreurs aléatoires du LLM ne se reproduisent pas systématiquement. Si trois générations sur quatre convergent vers la même réponse, celle-ci est probablement correcte.
Cette méthode est particulièrement efficace pour les tâches ayant une réponse objective (calculs, questions factuelles, classification) où la cohérence entre générations est un signal fort de validité. Elle s'avère moins pertinente pour les tâches créatives où la diversité des réponses est attendue et souhaitable.
Critique externe et validation croisée
Dans les systèmes multi-agents, la critique peut provenir d'un agent distinct spécialisé dans l'évaluation. Cette séparation des rôles permet de configurer l'agent critique avec des instructions et une "personnalité" différentes de l'agent générateur, réduisant les biais de confirmation.
L'agent critique peut être configuré pour adopter une posture particulièrement exigeante, voire adversariale, cherchant activement les failles dans la réponse plutôt que de confirmer sa validité. Cette dynamique reproduit le processus de revue par les pairs dans la recherche académique ou la revue de code en développement logiciel.
Configuration d'un agent critique spécialisé :
Rôle : Tu es un évaluateur expert dont la mission est d'identifier
les faiblesses dans les réponses fournies.
Comportement :
- Adopte une posture sceptique mais constructive
- Cherche activement les erreurs factuelles, omissions et ambiguïtés
- Propose des améliorations concrètes plutôt que des critiques vagues
- Si la réponse est véritablement excellente, reconnais-le explicitement
plaintext
Intégration avec les patterns existants
La reflection s'intègre naturellement aux architectures d'agents existantes comme complément plutôt que comme remplacement. Dans un agent ReAct, une phase de reflection peut intervenir avant de finaliser la réponse, permettant à l'agent de vérifier que ses observations et son raisonnement sont cohérents. Dans un système Plan-and-Execute, la reflection peut s'appliquer au plan généré (est-il complet ? réaliste ?) comme aux résultats de chaque étape.
Cette modularité permet d'activer la reflection de manière sélective selon la criticité de la tâche. Une requête simple peut être traitée directement, tandis qu'une tâche à fort enjeu déclenche le processus complet d'évaluation et révision.
Cas d'usage et limites
Le pattern de reflection démontre sa valeur dans des contextes spécifiques où l'auto-correction apporte un bénéfice mesurable, mais il n'est pas adapté à toutes les situations.
Les tâches de génération de code illustrent parfaitement l'intérêt de la reflection. Un agent qui génère une fonction peut, en phase de critique, vérifier que le code gère les cas limites (entrées nulles, listes vides, valeurs négatives), respecte les conventions de nommage, et inclut une gestion d'erreurs appropriée. Des études ont montré que cette approche réflexive améliore significativement la qualité du code généré, particulièrement sur les problèmes algorithmiques complexes.
La rédaction de contenu bénéficie également de ce pattern. Un premier jet peut être critiqué pour sa structure, sa clarté, son ton ou sa complétude, puis révisé en conséquence. Cette approche reproduit le processus naturel d'écriture où les premières versions sont systématiquement retravaillées.
Les tâches de raisonnement complexe (résolution de problèmes mathématiques, analyse juridique, diagnostic technique) gagnent en fiabilité lorsque l'agent vérifie la cohérence de son raisonnement. La reflection permet de détecter les erreurs logiques, les hypothèses non justifiées ou les conclusions hâtives.
| Cas d'usage | Bénéfice de la reflection | Critères de critique pertinents |
|---|---|---|
| Génération de code | Détection bugs logiques, cas limites | Correction, complétude, lisibilité |
| Rédaction technique | Structure, clarté, exhaustivité | Précision, cohérence, accessibilité |
| Analyse de données | Validité des conclusions | Rigueur méthodologique, biais potentiels |
| Support client | Pertinence, ton approprié | Empathie, exactitude, résolution |
Cependant, le pattern présente des limites importantes qu'il convient d'anticiper :
-
Coût computationnel : chaque itération de reflection multiplie les appels au LLM. Pour des applications à fort volume, ce surcoût peut devenir prohibitif sans stratégie de caching appropriée.
-
Latence accrue : le temps de réponse augmente proportionnellement au nombre d'itérations. Pour des cas d'usage temps réel, cette latence peut être inacceptable.
-
Biais de confirmation : dans l'approche single-agent, le LLM peut avoir tendance à valider ses propres réponses plutôt qu'à les critiquer objectivement. La qualité des prompts de critique est déterminante pour contrer ce biais.
-
Critiques non constructives : l'agent critique peut identifier des problèmes sans fournir de pistes d'amélioration exploitables, conduisant à des révisions qui n'améliorent pas réellement la réponse.
-
Sur-correction : dans certains cas, la révision peut dégrader une réponse initialement correcte. Un mécanisme de validation finale ou de comparaison entre versions peut mitiger ce risque.
L'activation de la reflection devrait donc être conditionnelle et contextuelle. Les requêtes simples ou à faible enjeu peuvent être traitées directement, réservant le processus complet aux tâches où la qualité justifie le coût supplémentaire. Des heuristiques basées sur la complexité de la requête, le domaine concerné ou les préférences utilisateur permettent d'automatiser cette décision.
À découvrir : notre formation Agentic AI
Conclusion
Les patterns de reflection et self-critique représentent une évolution significative dans la conception des agents IA. En dotant les systèmes d'une capacité d'auto-évaluation et d'auto-correction, ces approches permettent de dépasser les limitations inhérentes à la génération en un seul passage. L'agent ne se contente plus de produire une réponse : il la questionne, l'analyse et l'améliore avant de la considérer comme finale.
Cette capacité réflexive complète naturellement les architectures existantes. Un agent ReAct équipé de reflection peut vérifier la cohérence de son raisonnement avant de conclure. Un système Plan-and-Execute peut valider la qualité de son plan et de ses résultats intermédiaires. La reflection s'intègre comme une couche d'assurance qualité applicable à différents niveaux de l'architecture.
Les stratégies d'implémentation varient selon les contraintes : approche single-agent pour la simplicité, multi-agent pour l'objectivité, itérative pour le contrôle fin, ou self-consistency pour les tâches à réponse objective. Le choix dépend du cas d'usage, des exigences de qualité et des contraintes de coût et de latence.
Pour les équipes développant des solutions d'Agentic AI, maîtriser ces patterns devient un levier de différenciation. Les systèmes capables de s'auto-corriger inspirent davantage confiance et produisent des résultats de meilleure qualité, particulièrement sur les tâches complexes où les erreurs ont des conséquences significatives. La reflection transforme l'agent d'un générateur de premières ébauches en un producteur de réponses réfléchies et affinées, plus proche du travail d'un expert humain consciencieux.


