Surapprentissage : comment l’éviter ?
L’un des obstacles les plus délicats dans l’apprentissage automatique est le surapprentissage ou le overfitting en anglais. Un modèle de Machine Learning doit être capable de généraliser, c'est-à-dire qu'il doit pouvoir prendre de nouvelles observations et prédire avec une certaine précision la variable cible associée.

L’un des obstacles les plus délicats dans l’apprentissage automatique est le surapprentissage ou le overfitting en anglais. Un modèle de Machine Learning doit être capable de généraliser, c'est-à-dire qu'il doit pouvoir prendre de nouvelles observations et prédire avec une certaine précision la variable cible associée. Parfois ce n'est pas le cas, car le modèle est trop simple et ne tient pas compte de certains facteurs importants, ou à l'inverse, il est trop complexe et commence à surapprendre (ou overtiffter) les données. Il existe plusieurs méthodes pour détecter et éviter un surapprentissage dont la validation croisée, ajustement des hyperparamètres, etc.
Dans cet article nous aller détailler la notion du surapprentissage, ses causes, comment le détecter et surtout, comment l'éviter.
Qu'est-ce que le surapprentissage ?
Lorsque des algorithmes d’apprentissage automatique sont construits, ils utilisent un échantillon de données pour entraîner le modèle. Cependant, lorsque le modèle s’entraîne trop longtemps sur des données d’échantillon ou lorsque le modèle est trop complexe, il peut commencer à apprendre le « bruit » ou des renseignements non pertinents dans l’ensemble de données. Lorsque le modèle mémorise le bruit et s’adapte trop étroitement à l’ensemble d'entraînement, il devient « surabondant » et il est incapable de bien généraliser aux nouvelles données. Si un modèle ne peut pas bien généraliser à de nouvelles données, il ne sera pas en mesure d’exécuter les tâches de classification ou de prévision auxquelles il était destiné.
Idéalement, le cas où le modèle fait les prédictions avec pratiquement zéro erreur, est dit avoir un bon ajustement sur les données. Cette situation est réalisable à un endroit entre le sur-ajustement et le sous-ajustement. Pour mieux comprendre, on va prendre l'exemple suivant d'un modèle de régression linéaire avec des caractéristiques polynomiales.
À lire aussi : découvrez notre formation MLOps
Tout d'abord, on va générer des données randomisées à partir d'une fonction de cosinus, sur lesquelles on entrainera un modèle de régression linéaire.
import numpy as np
def true_fun(X):
return np.cos(1.3 * np.pi * X)
python
représente les ordonnées des points du jeu de données et représente les abscisses.
np.random.seed(0)
n_samples = 20
X = np.sort(np.random.rand(n_samples))
y = true_fun(X) + np.random.randn(n_samples) * 0.1
python
Si on visualise les données obtenues à l'aide de la bibliothèque matplotlib, on se trouve avec le nuage de points suivant.
import matplotlib.pyplot as plt
plt.plot(X, y, color = 'red', label="Actual")
plt.scatter(X, y, edgecolor='b', s=20, label="Samples")
plt.xlabel("x")
plt.ylabel("y")
plt.legend(loc="best")
plt.show()
python

On souhaite ensuite trouver une fonction mathématique de mappage de l’entrée à la sortie, où le résultat d'une observation correspond à la réponse la prédiction du modèle. On va essayer d’entraîner ce modèle sur les données qu'on a générées et à chaque fois, on varie le degré de la fonction polynomiale et on visualise les résultats.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
plt.figure(figsize=(14, 5))
for i in range(len(degrees)):
ax = plt.subplot(1, len(degrees), i + 1)
plt.setp(ax, xticks=(), yticks=())
polynomial_features=PolynomialFeatures(degree=degrees[i],include_bias=False)
linear_regression = LinearRegression()
pipeline = Pipeline([("polynomial_features", polynomial_features("linear_regression", linear_regression)])
pipeline.fit(X[:, np.newaxis], y)
X_test = np.linspace(0, 1, 100)
y_poly_pred = pipeline.predict(X_test[:, np.newaxis])
plt.plot(X_test, y_poly_pred, label="Model")
plt.plot(X_test, true_fun(X_test), label="True function")
plt.scatter(X, y, edgecolor='b', s=20, label="Samples")
plt.xlabel("x")
plt.ylabel("y")
plt.xlim((0, 1))
plt.ylim((-2, 2))
plt.legend(loc="best")
plt.title("Degree {}".format(degrees[i]))
plt.show()
python

On peut voir qu’une fonction linéaire (polynôme avec degré 1) n’est pas suffisante pour s’adapter aux échantillons d’entraînement. Ceci est appelé sous-ajustement.
Un polynôme de degré 3 se rapproche de la vraie fonction presque parfaitement. Ceci est appelé bon ajustement. Dans ce cas, le modèle ne représente ni un underfitting, ni un overfitting.
Cependant, pour les degrés supérieurs (avec le degré 12), le modèle débordera l’ensemble de données d'entrainement, c'est-à-dire qu’il apprend le bruit des données d'entrainement. Il s'agit d'un surapprentissage, le modèle dans ce cas apprend les éléments du jeu de données par cœur et prend en considération tous les points extrêmes. Il ne sera pas capable de généraliser.
Comment détecter un surapprentissage ?
Un surapprentissage et quasiment impossible à détecter avant de tester le modèle avec les données de teste. Pour ce faire, on peut séparer le jeu de données en deux sous-échantillons :
- Un ensemble d'entraînement (train set), sur lequel le modèle va apprendre.
- Un ensemble de test (test set), sur lequel on va évaluer les performances du modèle.

On peut détecter un overfitting en surveillant les performances du modèle sur les données d'entraînement et de test au fil du temps. Si les performances du modèle sur les données d'entraînement continuent de s'améliorer tandis que celles sur les données de test diminuent, cela indique un surapprentissage.
Par exemple, si le modèle fonctionnait avec une précision de 99 % sur l’ensemble de données d'entrainement, mais seulement de 50 à 55 % sur l’ensemble de données de test. L'écart significatif entre ces deux scores indique qu'un overfitting a eu lieu.
Habituellement, on considère que l'ensemble de test contient environ 30% du jeu de données et le reste pour l'ensemble d'entraînement (sous réserve de disposer d'assez de données). On entendra éventuellement parler d'ensemble de validation, moins utilisé dans la pratique, mais qui permet de tester plusieurs modèles selon le même échantillon.
Une autre façon simple de détecter cela est d’utiliser la validation croisée. Il existe plusieurs méthodes de validation croisée qui permettent de mesurer efficacement la performance du modèle sur des observations inconnues et par suite juger s'il le modèle est débordé ou pas. Ces méthodes partagent les mêmes principes fondamentaux, mais chacune est adaptée à des situations bien précises. On peut citer, par exemple, la K-Fold, le Shuffle Split ou le Leave-One-Out
Quelles sont les raisons possibles du surapprentissage ?
Il y a plusieurs raisons possibles du surapprentissage, parmi ces derniers, on peut citer :
- Lorsque le modèle est trop complexe par rapport à la quantité et à la qualité des données d'entraînement, il peut apprendre les détails et les bruits des données d'entraînement au lieu de généraliser des relations importantes.
- Si les données d'entraînement ne sont pas représentatives de la population cible, le modèle peut apprendre les particularités des données d'entraînement au lieu de généraliser à la population cible.
- Les modèles peuvent sur-ajuster lorsqu'ils ont trop d'hyperparamètres par rapport à la quantité de données d'entraînement.
- Une autre raison, peut-être que le jeu de donnée d'entrainement n'est pas suffisant pour entrainer le modèle, du coup, on a besoin de plus de données.
Comment éviter un surapprentissage ?
Il existe plusieurs méthodes pour éviter le surapprentissage en Machine Learning. Voici quelques exemples :
Feature Enginering
Si on n’a qu’une quantité limitée d’échantillons d'entrainement, chacun avec un grand nombre de fonctionnalités, on doit seulement sélectionner les fonctionnalités les plus importantes pour la formation afin que son modèle n’ait pas besoin d’apprendre pour autant de fonctionnalités et finalement déborder. On peut simplement tester différentes fonctionnalités, former des modèles individuels pour ces fonctionnalités, et évaluer les capacités de généralisation, ou utiliser l’une des diverses méthodes de sélection des fonctionnalités largement utilisées.
À lire aussi : découvrez notre formation MLOps
L'ingénierie des composantes peut aussi aider à éviter que le modèle d'apprentissage automatique à éviter l'overfitting, par exemple, on peut traiter les valeurs aberrantes, imputer les valeurs manquantes et normaliser ses données.
De cette façon, on simplifie au maximum ses données, on améliore les performances du modèle et on réduit au passage les risques de surapprentissage.
Early Stopping (arrêt précoce)
Cette méthode consiste tout simplement à arrêter l’entraînement quand les performances du modèle sur l’ensemble de validation commencent à décliner.
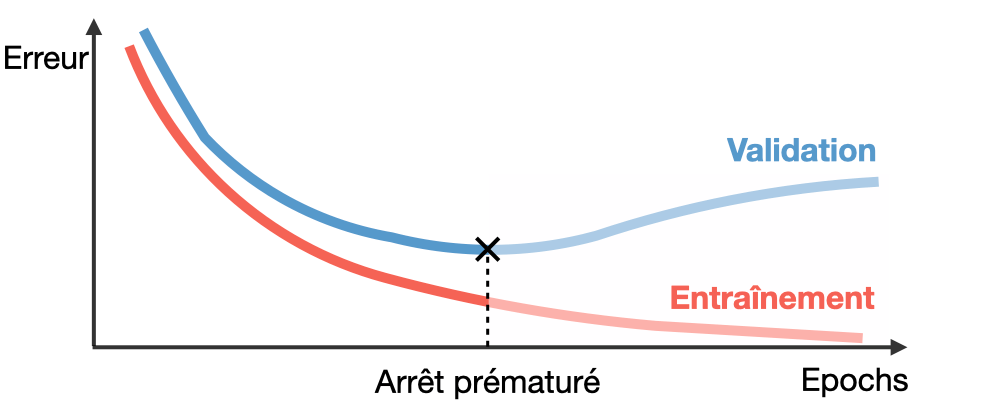
Cette technique permet aussi de détecter lorsque le modèle utilisé n’est pas adaptée, si on voit que le modèle commence à overfitter alors que les performances sont trop faibles, c’est qu’on doit changer de méthode.
Choix des hyperparamètres
Il est important de choisir les hyperparamètres de manière à ce qu'ils soient en accord avec les données d'entrée et les objectifs de l'apprentissage. De mauvais hyperparamètres peuvent entraîner un sur-ajustement des données d'entraînement.
Par exemple, dans le cas des modèles non paramétriques, comme l'arbre de décision, le risque du surapprentissage est important. Mais cela peut etre eviter par exemple en limitant la taille des arbres à travers l'hyberparametre ( max_depth).
Ajouter des données d’entraînements
Un plus grand ensemble de données réduirait le débordement. Si on ne peut pas recueillir plus de données et qu'on est limités aux données qu'on possède, on peut augmenter artificiellement la taille de l'ensemble de données. Par exemple, dans le cas où on s'entraîne un modèle pour une tâche de classification d’image, on peut effectuer diverses transformations d’image à l'ensemble de données d’image (basculement, rotation, redimensionnement, déplacement).

L'apprentissage d'ensemble
L'apprentissage d'ensemble (ou Ensemble Learning) est un concept de Machine Learning dans lequel l’idée est de former plusieurs modèles utilisant le même algorithme d’apprentissage. Le terme ensemble fait référence à une combinaison de modèles individuels créant un modèle plus fort et plus puissant. Il s'agit de centaines ou de milliers d’apprenants avec un objectif commun fusionnés pour résoudre un problème. Cette méthode permet d'éviter le sur ajustement des modèles et d'améliorer leur performance et leur capacité à généraliser.
Deux des méthodes les plus courantes de l'apprentissage d'ensemble sont Le Boosting et le Bagging. PLusieurs modeles de Machines Learning se basent sur ce type d'apprentissage, on peut citer en guise d'exemple XGBoost, LightGBM, GradientBoost...
Méthodes de régularisations
Les méthodes de régularisations sont des techniques qui permettent de réduire la complexité globale d’un modèle de machine learning. Un des exemples les plus populaires de ces méthodes est la régression pénalisée (par exemple la régularisation de type L1/Lasso et L2/Ridge). C'est un type de régularisation qui force le modèle à atteindre un équilibre entre performance et nombre de dimensions retenues. Ce sont des méthodes de sélection de variable intégrées dans les modèles de Machine Learning qui permettent d’effectuer la sélection de variable selon les résultats d'une fonction de pénalité qui attribue un poids à chaque variable.
Le Dropout
Dans un cas d'un réseau de neurones, on peut appliquer le Dropout, qui est une forme de régularisation, aux couches du modèle. Il s'agit d'ignorer un sous-ensemble d’unités du réseau. En utilisant le dropout, on peut réduire l’apprentissage interdépendant entre les unités du réseau, ce qui a peut-être mené à un débordement. Cependant, avec le dropout, on aura besoin de plus d’itérations pour que le modèle converge.
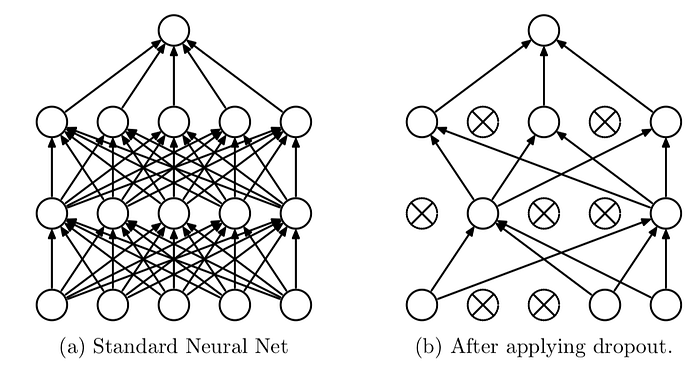
On peut également réduire la complexité du modèle en supprimant des couches et en réduisant sa taille en diminuant le nombre de neurones dans les couches entièrement connectées.
Conclusion
Même si ces différentes techniques fonctionnent bien, avoir une bonne compréhension du fonctionnement des modèles utilisés reste le moyen le plus sûr. Il faut toujours commencer par des modèles simples et convenable au type des données d'entrainement avant d'essayer ces méthodes.


