
Par Équipe Blent
Data Scientist
Publié le 24 mai 2022
Catégorie Machine Learning
Modèles de Machine Learning les plus populaires
Si vous comptez suivre une carrière en Data Science ou si vous compter tout simplement vous former en Machine Learning, il est utile de parcourir les principaux algorithmes sur le terrain pour avoir une idée des méthodes disponibles. Il y a tellement d’algorithmes qu’on peut se sentir confuse quand les noms d’algorithmes sont jetés autour et vous êtes censé savoir ce qu’ils sont et où ils s’adaptent.
Ces modèles de Machine Learning sont tout à fait essentiels pour effectuer la classification et la prédiction. Certain de ces algorithmes sont plus utiles et plus utilisés que d'autres. Cette popularité est due essentiellement à leur robustesse, performance et même parfois leur rapidité .
Dans cet article, nous allons expliquer ce que sont les algorithmes d’apprentissage automatique, leurs types et nous allons présenter les modèles les plus populaires.
Quels sont les modèles d’apprentissage automatique ?
L’apprentissage automatique est une application de l’IA qui permet aux systèmes d’apprendre et de s’améliorer à partir de l’expérience sans être explicitement programmés. En effet, il s'agit de développer des modèles prédictifs qui peuvent accéder aux données et les utiliser pour apprendre par eux-mêmes.
Ces modèles sont représentés comme une fonction mathématique qui prend les demandes sous forme de données d’entrée, fait des prédictions sur les données d’entrée, puis fournit un résultat en réponse. Tout d’abord, ces modèles sont entrainés sur un ensemble de données à l'aide d'un algorithme pour comprendre les entités, les domaines et les liens entre eux et apprendre de ces données. Une fois le modèle est entrainé, il pourra être mis en production avec des données qu’il n’a jamais vues auparavant.
À lire aussi : découvrez notre formation MLOps
Un algorithme est une procédure qui fonctionne sur des données et est utilisé pour construire un modèle d’apprentissage automatique prêt à la production. Un algorithme d’apprentissage automatique peut être lié à n’importe quel autre algorithme en informatique. Le type d’algorithme d’apprentissage automatique qui fonctionne le mieux dépend du problème opérationnel que vous résolvez, de la nature de l’ensemble de données et des ressources disponibles.
Les modèles Machine Learning peuvent généralement être classifiés dans trois classes selon le type d'apprentissage :
L'apprentissage supervisé : Le but de ce type d'apprentissage est d’apprendre une fonction qui, compte tenu d’un échantillon de données et de résultats souhaités, se rapproche le mieux de la relation entre les entrées et les sorties observables dans les données. Dans ce cas, on a une connaissance préalable de ce que les valeurs de sortie pour nos échantillons devraient être.
L'apprentissage non supervisé : Les algorithmes sont utilisés lorsque l’information utilisée pour entraîner le modèle n’est ni classifiée ni étiquetée. Le modèle en question étudie ses données d'entrainement dans le but de déduire une fonction pour décrire une structure cachée à partir ces données.
L'apprentissage par renforcement : L'apprentissage par renforcement est une méthode qui consiste à optimiser de manière itérative un algorithme uniquement à partir des actions qu'il entreprend et de la réponse associée de l'environnement dans lequel il évolue.
Le choix du modèle selon le type d'apprentissage dépend du problème traité et des données en question.
Quels sont les types des algorithmes de Machine Learning ?
Une autre façon d’organiser les algorithmes d’apprentissage automatique est selon leurs similitudes. Organiser les modèles Machine Learning selon différents critères est utile parce que cela nous oblige à réfléchir au processus de préparation des données d’entrée et aux rôles de ces modèles et et à en choisir un qui convient le mieux au problème afin d’obtenir les meilleurs résultats.
Les algorithmes de régression
Le point commun entre les algorithmes de régression, c'est qu'ils cherchent à prédire une valeur continue, une quantité. Ce type de modèles relève de l’apprentissage supervisé, l’algorithme est entraîné avec les caractéristiques d’entrée et les caractéristiques de sortie. Il aide à établir une relation entre les variables en estimant comment une variable affecte l’autre.
Parmi les algorithmes de régression les plus populaires, on a :
- La régression linéaire.
- La régression logistique.
- La régression pas à pas (Stepwise regression)
Les algorithmes à arbres de décision
Les méthodes de l’arbre de décision construisent un modèle de décisions fondées sur les valeurs réelles des attributs dans les données.
Les décisions se prennent dans une structure arborescente descendante qui possède des nœuds et des branches. À chaque nœud, une condition va nous permettre de nous diriger dans l'arbre, jusqu'à arriver à la fin (nœud terminal) et une décision prédictive soit prise pour un enregistrement donné. Les arbres de décision peuvent être utilisés pour les problèmes de classification et de régression. Ils sont souvent rapides et précis et un grand favori dans l’apprentissage automatique.
Parmi les algorithmes à arbres de décision les plus populaires, on a :
- L'arbre de décision pour la classification ou la régression.
- Random forest
- XGBoost
Les algorithmes de regroupement
Ce genre d'algorithmes cherchent à séparer les données en groupes pour les comprendre. Dans le cas de l'apprentissage supervisé, il s'agit d'une classification, et les données sont regroupées selon leurs étiquettes (ou labels). Dans le cas de l'apprentissage non supervisé, il s'agit d'un regroupement (clustering). Le principe, c'est de séparer les données en groupes homogènes ayant des caractéristiques communes.
À lire aussi : découvrez notre formation MLOps
Parmi les algorithmes de regroupement les plus populaires, on a :
- k-Means
- k-Medians
- Regroupement hiérarchique (Hierarchical Clustering)
Les algorithmes à base d'instance
Ces méthodes permettent généralement de constituer une base de données d’exemples de données et de comparer de nouvelles données à la base de données à l’aide d’une mesure de similarité afin de trouver la meilleure correspondance et de faire une prédiction.
C'est un apprentissage basé sur la mémoire. L’accent est mis sur la représentation des instances stockées et les mesures de similarité utilisées entre les instances.
Parmi les algorithmes de regroupement les plus populaires, on a :
- KNN (k-Nearest Neighbor)
- SVM (Support Vector Machines)
- LVK (Learning Vector Quantization)
Les algorithmes bayésiens
Le but du Machine Learning bayésien est d’estimer la distribution postérieure compte tenu de la probabilité et de la distribution antérieure. Concrètement, nous effectuons l’estimation du maximum de vraisemblance, ensuite un processus itératif qui met à jour les paramètres du modèle dans le but de maximiser la probabilité de voir les données d'entrainement ayant déjà vu les paramètres du modèle.
Parmi les algorithmes de regroupement les plus populaires, on a :
- Naïve Bayes
- Bayesian Belief Network (BBN)
- Bayesian Network (BN)
Les algorithmes à apprentissage d'ensemble
L'apprentissage d'ensemble dont l’idée est de former plusieurs modèles utilisant le même algorithme d’apprentissage. Le terme ensemble fait référence à une combinaison de modèles individuels créant un modèle plus fort et plus puissant. Ces modèles individuels peuvent être entraînés simultanément (méthode ensembliste parallèle : Bagging) ou bien ils peuvent être entraînés itérativement (méthode ensembliste séquentielle : Boosting)
Parmi les algorithmes d'apprentissage d'ensemble les plus populaires, on a :
Les modèles de Machine Learning les plus populaires :
Il existe de nombreux modèles machine learning, mais certains sont plus populaires que d'autres. Voici quelques-uns des modèles les plus populaires :
K-means
C’est un algorithme d’apprentissage non supervisé qui résout les problèmes de regroupement. Les ensembles de données sont classés en un nombre particulier de groupes de sorte que tous les points de données d’un groupe sont homogènes et hétérogènes par rapport aux données d’autres grappes.
Comment K-means forme des groupes :
- Nous commençons par spécifier manuellement la valeur de k, le nombre de groupes qui seront générés par l'algorithme.
- Ensuite, nous choisissons k points de données prototypes s'appellent des centroïdes et représentent les centres des groupes. Au début, ils seront choisis et placés aléatoirement
- L’algorithme passe par les points de données un par un, en mesurant la distance entre chaque point par rapport aux k centroïdes. L’algorithme regroupe ensuite le point de données avec le centroïde le plus proche.
- Puisque l'on vient d'affecter chaque point à un des k groupes, les centres ne sont plus les mêmes. Il faut donc recalculer les nouveaux k centroïdes qui seront les centres de gravité de chaque groupe calculé dans l'étape précédente.
- On répète ces étapes jusqu’à ce que les nouveaux centroïdes soient stabilités, et ne changent plus de groupe. Ces groupes serviront après pour classifier de nouveau éléments.

K-means ne peut être exécuté qu'avec des données numériques. Il est donc déconseillé de l'utiliser avec des données d'autres types. Il est préférable de l'utiliser avec un jeu de données est de grande dimension, C'est-à-dire lorsque le nombre de variables ou d’attributs est beaucoup plus élevé que le nombre d’observations.
Random Forest
Le Random Forest (qui signifie forêt aléatoire) est un ensemble d'arbres de décision utilisés pour prédire une quantité ou une probabilité.
1 - La première étape consiste à appliquer le principe du bagging, c'est-à-dire créer de nombreux sous-échantillons aléatoires de notre ensemble de données avec possibilité de sélectionner la même valeur plusieurs fois.
2 - Des arbres de décision individuels sont ensuite construits pour chaque échantillon. Chaque arbre est entraîné sur une portion aléatoire afin de recréer une prédiction et chaque arbre fonctionne individuellement et indépendamment des autres.
3 - Enfin, chaque arbre va prédire un résultat. Le résultat avec le plus de votes (le plus fréquent) devient le résultat final de notre modèle. Dans le cas de régression, on prendra la moyenne des votes de tous les arbres
À lire aussi : découvrez notre formation MLOps

Cet algorithme est excellent à utiliser avec des données tabulaires, mais il n'est pas optimale pour les données sont éparses ou lorsqu'il y a plusieurs valeurs manquantes.
SVM
Le principe des SVM consiste à ramener un problème de classification ou de discrimination à un hyperplan dans lequel les données sont séparées en plusieurs classes dont la frontière est la plus éloignée possible des points de données .
On commence tout d'abord par projeter chaque élément de données dans l’espace n-dimensionnel (où n représente le nombre de caractéristiques présentes dans le jeu de données) avec la valeur de chaque caractéristique étant la valeur d’une coordonnée particulière.
Ensuite, on effectue la classification en trouvant l’hyperplan qui différencie très bien les deux classes. On choisi l meilleur hyperplan selon la distance minimale de la frontière par rapport a l'élément de la population le plus proche ou cet élément peut appartenir à n’importe quelle classe.
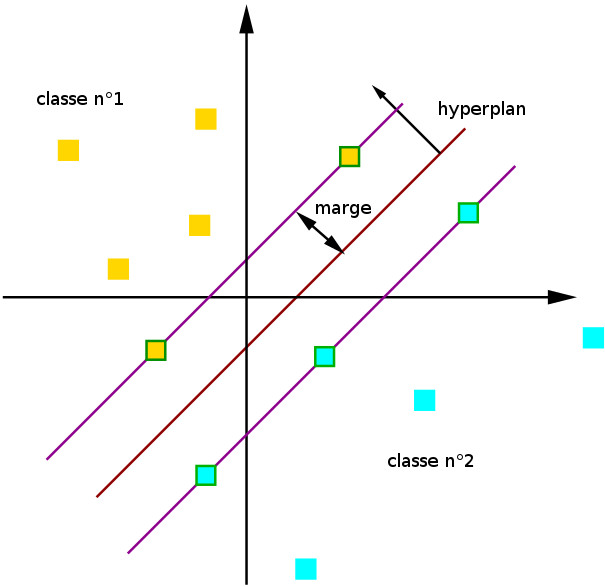
Le SVM est l'un des modèles Machine Learning non seulement les plus simples, mais aussi l'un des plus performants. Il est généralement utilisée avec des jeux de données présentant un grand nombre de classes. Il est fréquemment utilisé aussi pour la reconnaissance faciale, la classification de texte (NLP) et la classification d'image.
XGBoost
XGBoost (ou contraction de eXtreme Gradient Boosting) est un modèle de machine Learning basé sur l'apprentissage d'ensemble séquentiel et les arbres de décision.
Il utilise une technique d'optimisation appelée le boosting de gradient. La première étape consiste à créer un premier modèle, un arbre de décision. Il est entraîné sur les données. Au début, on attribue des poids égaux à toutes les observations. À partir des résultats obtenus de ce modèle, si une observation est mal classée, cela augmente son poids.
Ensuite, un second arbre est construit pour tenter de corriger les erreurs présentes dans le premier modèle. Il est entraîné à l'aide des données pondérées obtenues dans la première étape. Cette procédure se poursuit et des modèles sont ajoutés jusqu’à ce que l’ensemble complet des données de formation soit prédit correctement ou que le nombre maximal de modèles, soit ajouté.
Les prédictions du dernier modèle ajouté seront les prédictions globales pondérées fournies par les anciens modèles d’arbres.
XGBoost est capable d'apprendre des modèles avec des données hétérogènes, telles que des données numériques et catégoriques. Il est également capable de gérer des données manquantes.
Les réseaux de neurones
Les réseaux neuronaux sont un sous-ensemble des modèles Machine Learning de et sont également connus sous le nom de réseaux neuronaux artificiels. Les réseaux neuronaux sont composés de neurones artificiels et conçus d’une manière qui ressemble à la structure et au fonctionnement du cerveau humain. Chaque neurone artificiel se connecte à de nombreux autres neurones dans un réseau neuronal, et ces millions de neurones connectés créent une structure cognitive sophistiquée.
Les réseaux neuronaux se composent d’une structure multicouche, contenant une couche d’entrée, une ou plusieurs couches cachées et une couche de sortie. Comme chaque neurone est connecté à un autre neurone, il transfère des données d’une couche à l’autre neurone des couches suivantes. Enfin, les données atteignent la dernière couche ou couche de sortie du réseau neuronal et génèrent des sorties.
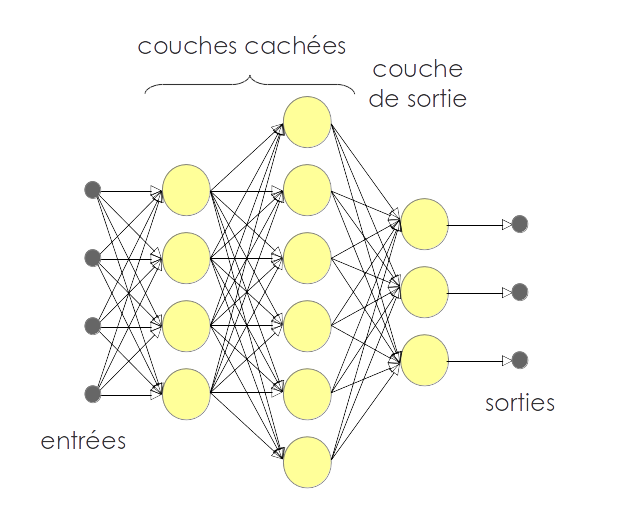
Les réseaux de neurones sont généralement utilisés pour des problématiques complexes. Ils peuvent être utilisés pour résoudre les problèmes de classification, de détection, de reconnaissance de formes, de vision par ordinateur, de NLP, etc.
Conclusion
Il existe plusieurs autres modèles de Machine Learning adéquats pour plusieurs cas et chaque jour plusieurs autre sont inventés. Aujourd'hui les réseaux de neurone, XGBoost , SVM et K-means sont les plus populaires. Si vous voulez suivre une carrière en Machine Learning, il faut commencer par maîtriser leur utilisation avant de passer à d'autres modèles.
Vous souhaitez vous former au MLOps ?
Articles similaires

20 sept. 2022
Hugging Face est une startup française qui s'est fait connaître grâce à l'infrastructure NLP qu'ils ont développée. Aujourd'hui, elle est sur le point de révolutionner le domaine du Machine Learning et traitement automatique du langage naturel. Dans cet article, nous allons présenter Hugging Face et détailler les taches de base que cette librairie permet de réaliser. Nous allons également énumérer ses avantages et ses alternatifs.
Équipe Blent
Data Scientist
Lire l'article

12 juil. 2022
spaCy est une bibliothèque open-source pour le traitement avancé du langage naturel. Elle est conçue spécifiquement pour une utilisation en production et permet de construire des applications qui traitent et comprennent de grands volumes de texte.
Équipe Blent
Data Scientist
Lire l'article

4 juil. 2022
Un auto-encodeur est une structure de réseaux neuronaux profonds qui s'entraîne pour réduire la quantité de données nécessaires pour représenter une donnée d'entrée. Ils sont couramment utilisés en apprentissage automatique pour effectuer des tâches de compression de données, d'apprentissage de représentations et de détection de motifs.
Équipe Blent
Data Scientist
Lire l'article
60 rue François 1er
75008 Paris
Blent est une plateforme 100% en ligne pour se former aux métiers Tech & Data.
Organisme de formation n°11755985075.

Data Engineering
IA Générative
MLOps
Cloud & DevOps
À propos
Gestion des cookies
© 2025 Blent.ai | Tous droits réservés