Chain of Thought : faire raisonner les LLM étape par étape
Les modèles de langage impressionnent par leur capacité à générer du texte cohérent, à répondre à des questions variées et à accomplir des tâches créatives. Pourtant, face à des problèmes nécessitant un raisonnement en plusieurs étapes, ces mêmes modèles montrent souvent leurs limites. Demandez à un LLM de résoudre un problème de mathématiques ou d'analyser une situation logique complexe, et vous observerez fréquemment des réponses incorrectes ou des raccourcis de raisonnement qui mènent à des conclusions erronées.

Les modèles de langage impressionnent par leur capacité à générer du texte cohérent, à répondre à des questions variées et à accomplir des tâches créatives. Pourtant, face à des problèmes nécessitant un raisonnement en plusieurs étapes, ces mêmes modèles montrent souvent leurs limites. Demandez à un LLM de résoudre un problème de mathématiques ou d'analyser une situation logique complexe, et vous observerez fréquemment des réponses incorrectes ou des raccourcis de raisonnement qui mènent à des conclusions erronées.
Le Chain of Thought (CoT), ou chaîne de pensée, est une technique de prompting qui transforme la façon dont les modèles abordent ces problèmes complexes. Plutôt que de demander une réponse directe, cette approche incite le LLM à expliciter son raisonnement étape par étape, à la manière d'un humain qui pose ses réflexions sur papier avant de conclure. Cette simple modification dans la formulation des requêtes peut améliorer drastiquement les performances sur les tâches de raisonnement, de calcul et de logique.
Introduite par des chercheurs de Google en 2022, cette technique a rapidement été adoptée par la communauté et a ouvert la voie aux Reasoning Models actuels comme o1 ou DeepSeek R1. Comprendre le Chain of Thought, c'est saisir un mécanisme fondamental qui distingue une utilisation basique des LLM d'une exploitation véritablement efficace de leurs capacités.
Dans cet article, nous allons explorer le fonctionnement du Chain of Thought, comprendre ce qui le différencie d'autres techniques comme le few-shot prompting, et découvrir comment l'appliquer concrètement pour obtenir de meilleurs résultats de vos modèles de langage.
Le problème du raisonnement direct
Pour comprendre l'intérêt du Chain of Thought, il faut d'abord saisir pourquoi les LLM échouent sur certaines tâches apparemment simples. Un modèle de langage génère sa réponse token par token, chaque mot étant prédit en fonction du contexte précédent. Ce processus fonctionne remarquablement bien pour des tâches où la réponse découle naturellement du contexte : reformuler un texte, répondre à une question factuelle, ou générer du contenu créatif.
Le problème surgit lorsque la tâche requiert un raisonnement en plusieurs étapes. Prenons un exemple classique :
Question : Roger a 5 balles de tennis. Il achète 2 boîtes de 3 balles chacune.
Combien a-t-il de balles maintenant ?
plaintext
Un humain décomposerait naturellement ce problème : d'abord calculer combien de balles contiennent les 2 boîtes (2 × 3 = 6), puis ajouter ce résultat au nombre initial (5 + 6 = 11). Mais un LLM sollicité pour une réponse directe peut court-circuiter ce raisonnement et produire une réponse incorrecte, confondant les opérations ou omettant une étape.
Ce phénomène s'explique par la nature même des LLM. Ils ont été entraînés sur des textes où les réponses suivent souvent directement les questions, sans exposition systématique aux étapes intermédiaires du raisonnement. Sans guidance explicite, le modèle reproduit ce pattern et tente de prédire directement la réponse finale, même quand celle-ci nécessite des calculs ou déductions intermédiaires.
Les conséquences sont particulièrement visibles sur :
- Les problèmes arithmétiques multi-étapes
- Les puzzles logiques et les énigmes
- L'analyse de scénarios avec plusieurs variables
- Les questions nécessitant de combiner plusieurs informations
Le Chain of Thought : expliciter le raisonnement
Le Chain of Thought repose sur une idée simple mais puissante : demander au modèle de montrer son travail. Au lieu d'attendre une réponse directe, on incite le LLM à produire une séquence d'étapes de raisonnement qui mènent progressivement à la conclusion.
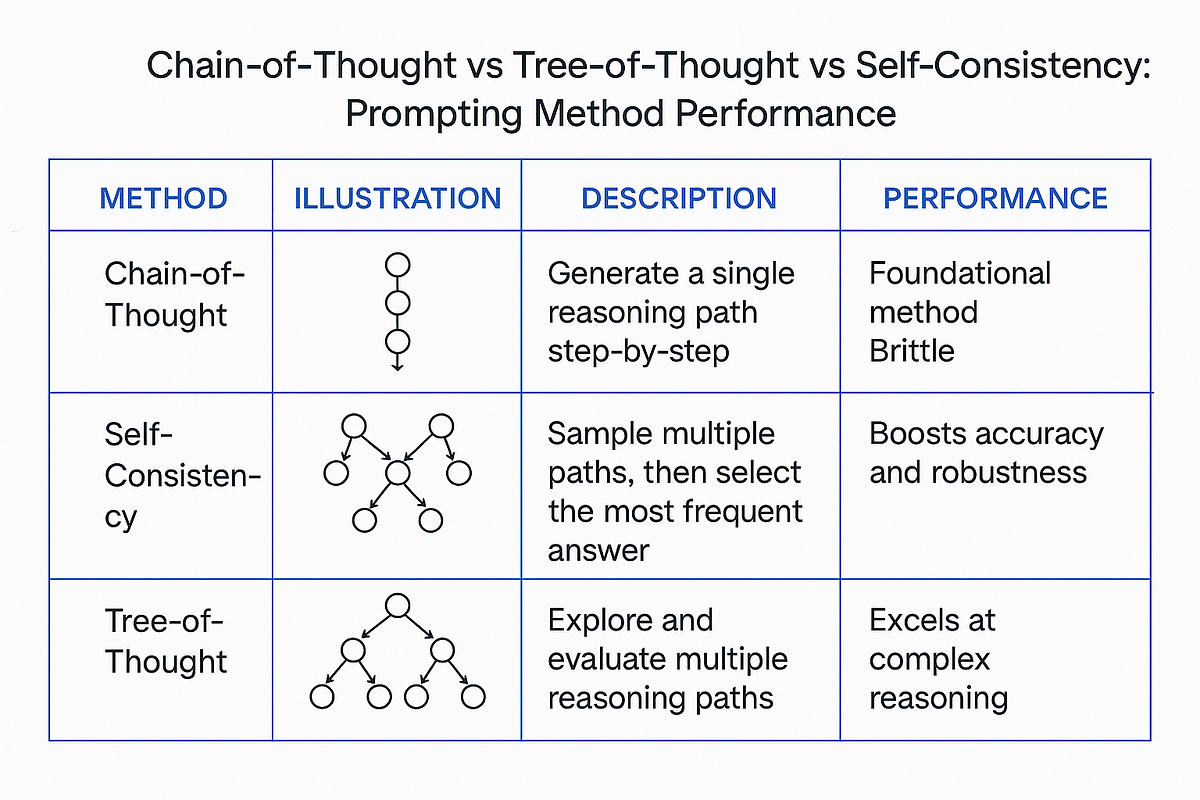
Cette approche peut être implémentée de deux manières principales. La première, appelée zero-shot CoT, consiste simplement à ajouter une instruction comme "Réfléchis étape par étape" ou "Explique ton raisonnement" à la fin du prompt. Cette formulation magique suffit souvent à transformer le comportement du modèle :
Question : Roger a 5 balles de tennis. Il achète 2 boîtes de 3 balles chacune.
Combien a-t-il de balles maintenant ?
Réfléchis étape par étape.
plaintext
Le modèle produira alors une réponse structurée :
1. Roger commence avec 5 balles de tennis.
2. Il achète 2 boîtes contenant chacune 3 balles.
3. Le nombre de balles dans les boîtes est : 2 × 3 = 6 balles.
4. Le total de balles est donc : 5 + 6 = 11 balles.
Roger a maintenant 11 balles de tennis.
plaintext
La seconde approche, le few-shot CoT, va plus loin en fournissant des exemples de raisonnements complets avant de poser la question cible. Le modèle apprend ainsi le format attendu et reproduit ce pattern de réflexion explicite.
| Approche | Description | Effort requis | Efficacité |
|---|---|---|---|
| Zero-shot CoT | Simple instruction "Réfléchis étape par étape" | Minimal | Bonne |
| Few-shot CoT | Exemples de raisonnements complets | Modéré | Excellente |
| Auto-CoT | Génération automatique des exemples | Variable | Très bonne |
Ce qui rend le Chain of Thought efficace, c'est qu'il exploite une propriété fondamentale des LLM : leur capacité à conditionner leur génération sur le contexte précédent. En forçant la production d'étapes intermédiaires, chaque nouvelle étape bénéficie du raisonnement déjà explicité. Le modèle ne saute plus directement à la conclusion mais construit sa réponse de manière incrémentale, réduisant les risques d'erreur.
Chain of Thought vs Few-Shot Prompting
Il est essentiel de distinguer le Chain of Thought du few-shot prompting classique, car ces deux techniques sont souvent confondues alors qu'elles adressent des problèmes différents.
Le few-shot prompting consiste à fournir quelques exemples de paires question-réponse avant de poser la question cible. L'objectif est de montrer au modèle le format de sortie attendu et le type de tâche à accomplir. Par exemple, pour une tâche de classification de sentiment :
Texte : "Ce film est absolument génial !" → Positif
Texte : "Je n'ai jamais vu quelque chose d'aussi ennuyeux." → Négatif
Texte : "Le service était correct mais sans plus." → Neutre
Texte : "Cette pizza était délicieuse, j'y retournerai !" → ?
plaintext
Ici, les exemples montrent la correspondance entre un texte et son sentiment, mais ils n'expliquent pas pourquoi cette classification est faite. Le modèle apprend le pattern de réponse sans comprendre le raisonnement sous-jacent.
Le Chain of Thought ajoute une dimension supplémentaire : il ne s'agit plus seulement de montrer quoi répondre, mais comment y parvenir. Les exemples incluent explicitement les étapes de réflexion :
Question : Un train parcourt 120 km en 2 heures. Quelle est sa vitesse moyenne ?
Raisonnement : La vitesse moyenne se calcule en divisant la distance par le temps.
Distance = 120 km, Temps = 2 heures.
Vitesse = 120 ÷ 2 = 60 km/h.
Réponse : 60 km/h
Question : Une voiture consomme 8 litres aux 100 km. Combien consomme-t-elle pour 250 km ?
Raisonnement : ...
plaintext
La différence fondamentale réside dans ce que le modèle apprend à reproduire. Avec le few-shot classique, il apprend un mapping entrée-sortie. Avec le Chain of Thought, il apprend un processus de résolution. Cette distinction devient cruciale pour les tâches où le chemin vers la réponse n'est pas trivial.
En pratique, les deux techniques peuvent se combiner efficacement. Le few-shot fournit le cadre et le format, tandis que le Chain of Thought structure le raisonnement au sein de ce cadre. Cette combinaison (few-shot CoT) représente souvent l'approche la plus performante pour les tâches complexes.
À découvrir : notre formation LLM Engineering
Applications et bonnes pratiques
Le Chain of Thought trouve des applications dans de nombreux domaines où le raisonnement structuré apporte une valeur ajoutée. Les cas d'usage les plus évidents concernent les problèmes mathématiques et scientifiques, où chaque étape de calcul peut être vérifiée. Mais la technique s'étend bien au-delà.
En programmation, demander au modèle d'expliciter sa logique avant d'écrire le code produit souvent des solutions plus robustes. Le raisonnement préalable permet d'identifier les cas limites, de structurer l'algorithme, et de justifier les choix d'implémentation. Cette approche est d'ailleurs au cœur de la méthode CRAFT pour la rédaction de prompts efficaces.
Pour l'analyse de documents complexes, le Chain of Thought guide le modèle dans l'extraction et la synthèse d'informations. Plutôt que de demander directement une conclusion, on peut structurer l'analyse : identifier les points clés, les mettre en relation, évaluer leur pertinence, puis formuler une synthèse.
Quelques bonnes pratiques pour maximiser l'efficacité du Chain of Thought :
- Adapter la granularité : pour des problèmes simples, quelques étapes suffisent ; pour des tâches complexes, décomposer finement
- Demander la vérification : inclure une étape où le modèle vérifie la cohérence de son raisonnement
- Structurer les exemples : dans le few-shot CoT, utiliser un format cohérent (numérotation, marqueurs explicites)
- Combiner avec d'autres techniques : le CoT s'associe bien avec le context engineering et les systèmes RAG
Il faut également reconnaître les limites de cette approche. Le Chain of Thought augmente la consommation de tokens puisque le modèle génère plus de texte. Pour des applications à fort volume ou sensibles à la latence, ce coût supplémentaire doit être pris en compte. De plus, expliciter le raisonnement ne garantit pas sa justesse : un modèle peut produire une chaîne de pensée parfaitement structurée mais fondée sur des prémisses erronées.
Les frameworks comme LangChain facilitent l'implémentation du Chain of Thought dans des pipelines de production. Des templates de prompts optimisés, combinés à des mécanismes de parsing des réponses structurées, permettent d'exploiter cette technique à grande échelle tout en maintenant un contrôle sur la qualité des sorties.
Conclusion
Le Chain of Thought représente une avancée majeure dans notre compréhension de l'interaction avec les modèles de langage. En incitant les LLM à expliciter leur raisonnement plutôt qu'à produire des réponses directes, cette technique débloque des capacités qui restaient inexploitées avec des approches de prompting plus naïves.
Ce qui rend le CoT particulièrement précieux, c'est sa simplicité de mise en œuvre. Quelques mots ajoutés à un prompt peuvent transformer un modèle qui échoue sur des problèmes arithmétiques basiques en un solveur capable de raisonnements multi-étapes sophistiqués. Cette accessibilité en fait une technique que tout utilisateur de LLM devrait maîtriser.
Le Chain of Thought a également ouvert la voie à des développements plus avancés. Les Reasoning Models actuels, comme o1 d'OpenAI ou R1 de DeepSeek, internalisent et optimisent ce processus de réflexion étape par étape. Ce qui était une technique de prompting est devenu un principe d'architecture intégré directement dans l'entraînement des modèles les plus performants.
Pour les développeurs et les équipes qui construisent des applications d'IA, le Chain of Thought reste un outil fondamental du toolkit. Que ce soit pour améliorer la fiabilité d'un assistant technique, structurer l'analyse de documents complexes, ou simplement obtenir des réponses plus précises sur des questions nécessitant de la réflexion, cette technique permet d'exploiter pleinement le potentiel des modèles de langage modernes.