Modèles multimodaux : au-delà du VLM
Les modèles de langage ont révolutionné notre façon d'interagir avec l'intelligence artificielle, mais ils restent fondamentalement limités au texte. Or, le monde réel est intrinsèquement multimodal : nous percevons simultanément des images, des sons, des mouvements, et notre compréhension émerge de la fusion de ces différentes sources d'information. Les modèles multimodaux visent précisément à combler ce fossé en permettant aux systèmes d'IA de traiter et de combiner plusieurs types de données.

Les modèles de langage ont révolutionné notre façon d'interagir avec l'intelligence artificielle, mais ils restent fondamentalement limités au texte. Or, le monde réel est intrinsèquement multimodal : nous percevons simultanément des images, des sons, des mouvements, et notre compréhension émerge de la fusion de ces différentes sources d'information. Les modèles multimodaux visent précisément à combler ce fossé en permettant aux systèmes d'IA de traiter et de combiner plusieurs types de données.
L'émergence des VLM (Vision-Language Models) a constitué une première étape majeure dans cette direction. Des modèles comme GPT-4 Vision, Claude 3.5 Sonnet ou LLaVA permettent désormais de poser des questions sur des images, d'analyser des documents visuels ou de décrire des scènes complexes. Mais la multimodalité ne s'arrête pas à la vision. Une nouvelle génération de modèles étend ces capacités à l'audio, à la vidéo, et même à des modalités plus exotiques comme les données 3D ou les séquences temporelles.
Cette évolution répond à des besoins concrets. Un assistant capable de comprendre simultanément ce qu'on lui dit vocalement, ce qu'il voit via une caméra et le contexte textuel d'une conversation devient infiniment plus utile qu'un système limité au texte. Les applications vont de l'accessibilité (description audio d'environnements pour personnes malvoyantes) à l'industrie (analyse de défauts sur chaîne de production) en passant par la créativité (génération de contenus cohérents à travers plusieurs médias).
Dans cet article, nous allons explorer l'écosystème des modèles multimodaux au-delà des seuls VLM, comprendre les architectures qui permettent cette fusion des modalités, et analyser les cas d'usage qui émergent de ces nouvelles capacités.
Des VLM aux modèles truly multimodaux
Les Vision-Language Models ont ouvert la voie en démontrant qu'un LLM pouvait être étendu pour comprendre les images. L'architecture typique d'un VLM combine un encodeur visuel (souvent basé sur CLIP ou SigLIP) qui transforme l'image en une séquence de tokens visuels, avec un LLM qui traite ces tokens aux côtés des tokens textuels. Cette approche a produit des résultats impressionnants : GPT-4V peut analyser des graphiques complexes, Claude 3.5 excelle dans la compréhension de documents, et des modèles open source comme LLaVA ou Qwen-VL démocratisent ces capacités.
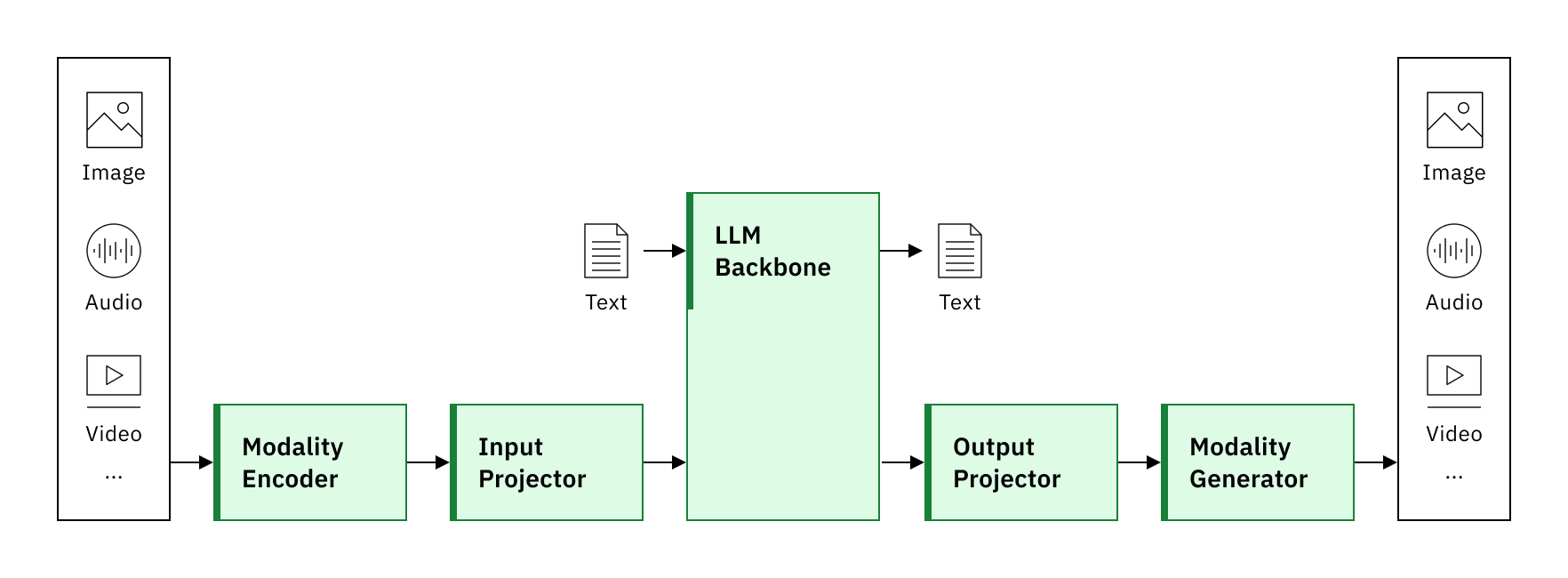
Mais les VLM restent fondamentalement des modèles bimodaux (texte + image). La véritable multimodalité implique d'aller plus loin en intégrant d'autres sources d'information de manière native. Plusieurs directions émergent actuellement :
- Audio et parole : comprendre la voix humaine, la musique, les sons environnementaux, et générer des réponses vocales naturelles
- Vidéo : analyser des séquences temporelles, comprendre des actions, suivre des objets dans le temps
- Données structurées : intégrer des tableaux, des graphiques, des schémas techniques
- Modalités spécialisées : données médicales (imagerie, signaux physiologiques), données 3D, séries temporelles
| Modalité | Exemples de modèles | Capacités typiques |
|---|---|---|
| Texte + Image | GPT-4V, Claude 3.5, LLaVA | Description, OCR, analyse visuelle |
| Texte + Audio | Gemini Pro, Whisper + LLM | Transcription, compréhension vocale |
| Texte + Vidéo | Gemini 1.5, Video-LLaMA | Résumé vidéo, Q&A temporel |
| Omnimodal | GPT-4o, Gemini Ultra | Entrées/sorties multiples simultanées |
La tendance actuelle va vers des modèles omnimodaux capables de traiter nativement plusieurs modalités en entrée et en sortie. GPT-4o (le "o" signifiant "omni") illustre cette évolution : le modèle peut recevoir du texte, des images et de l'audio, et répondre dans ces mêmes modalités de manière fluide et naturelle. Cette capacité native (par opposition à un pipeline assemblant plusieurs modèles spécialisés) permet des interactions plus naturelles où le modèle peut, par exemple, réagir au ton de la voix tout en analysant une image partagée.
Architectures et mécanismes de fusion
La construction d'un modèle véritablement multimodal pose des défis architecturaux significatifs. Comment représenter des données aussi différentes que du texte, des pixels et des ondes sonores dans un espace commun où elles peuvent interagir ?
L'approche dominante repose sur la tokenisation universelle. Chaque modalité est d'abord traitée par un encodeur spécialisé qui la transforme en une séquence de représentations vectorielles (tokens). Un encodeur visuel comme ViT découpe l'image en patches et les encode, un encodeur audio comme Whisper transforme le spectrogramme en embeddings, et ainsi de suite. Ces tokens hétérogènes sont ensuite projetés dans un espace commun où le transformer principal peut les traiter de manière unifiée.

Cette architecture modulaire présente plusieurs avantages. Elle permet de réutiliser des encodeurs pré-entraînés performants pour chaque modalité, de fine-tuner sélectivement certaines parties du système, et d'ajouter de nouvelles modalités sans repartir de zéro. Le projecteur (souvent un simple MLP ou un module d'attention croisée) joue un rôle crucial en alignant les représentations des différentes modalités dans l'espace sémantique du LLM.
Les mécanismes d'attention permettent ensuite au modèle de fusionner intelligemment les informations. Quand on pose une question textuelle sur une image, l'attention peut se focaliser sur les régions visuelles pertinentes. Quand on analyse une vidéo avec une bande sonore, le modèle peut corréler les événements visuels et auditifs. Cette fusion par attention, plutôt qu'une simple concaténation, permet des interactions riches entre modalités.
Les modèles les plus récents comme Gemini 1.5 ou GPT-4o poussent cette intégration encore plus loin avec des architectures entraînées de manière native sur des données multimodales, plutôt que d'assembler des composants pré-entraînés séparément. Cette approche "native" produit une compréhension plus fluide des relations inter-modalités, au prix d'un entraînement considérablement plus coûteux.
À découvrir : notre formation LLM Engineering
Au-delà de la vision : audio, vidéo et nouvelles frontières
Si les VLM dominent actuellement l'écosystème, les autres modalités progressent rapidement et ouvrent des possibilités inédites.
Modèles audio et parole
L'intégration de l'audio va bien au-delà de la simple transcription. Les modèles comme GPT-4o ou Gemini Pro peuvent comprendre les nuances de la voix (ton, émotion, hésitations), identifier des locuteurs, analyser de la musique, ou reconnaître des sons environnementaux. Cette compréhension audio riche permet des interactions véritablement conversationnelles où le modèle ne répond pas seulement au contenu verbal mais aussi à la manière dont les choses sont dites.
La génération audio progresse également. Au-delà des systèmes text-to-speech classiques, des modèles comme AudioLM ou MusicGen peuvent générer de la musique, des effets sonores, ou des voix expressives qui maintiennent une cohérence sur de longues durées. Combinées aux capacités de compréhension, ces technologies permettent d'envisager des assistants vocaux d'un nouveau genre, capables de conversations naturelles avec des réponses vocales expressives et contextuellement appropriées.
Compréhension vidéo
La vidéo représente une modalité particulièrement exigeante car elle combine la complexité spatiale des images avec une dimension temporelle. Comprendre une vidéo implique de :
- Reconnaître les objets et les personnes, et suivre leur évolution
- Comprendre les actions et les interactions (quelqu'un verse de l'eau dans un verre)
- Saisir la narration et la causalité (pourquoi cet événement suit-il cet autre ?)
- Intégrer éventuellement la bande sonore pour une compréhension complète
Des modèles comme Gemini 1.5 Pro, avec sa fenêtre de contexte massive, peuvent ingérer des vidéos de plusieurs heures et répondre à des questions précises sur leur contenu. Video-LLaMA et ses successeurs open source permettent d'expérimenter avec ces capacités sur infrastructure propre. Les applications vont de l'analyse automatique de contenus vidéo (modération, indexation) à l'assistance en temps réel (un technicien filmant un équipement défaillant pour obtenir un diagnostic).
Modalités émergentes
Au-delà du trio texte-image-audio, des travaux explorent l'intégration de modalités plus spécialisées :
- Données 3D : les point clouds, meshes et représentations volumétriques trouvent des applications en robotique, en architecture et en réalité augmentée
- Séries temporelles : signaux physiologiques (ECG, EEG), données de capteurs IoT, métriques financières
- Données tactiles et proprioceptives : particulièrement pertinentes pour la robotique et les interfaces haptiques
- Graphes et structures relationnelles : réseaux sociaux, molécules, knowledge graphs
Ces modalités restent pour l'instant moins matures que la vision ou l'audio, mais leur intégration progressive élargira considérablement le champ d'application des systèmes d'IA.
Applications et considérations pratiques
L'adoption des modèles multimodaux en production soulève des questions spécifiques qu'il convient d'anticiper.
Du point de vue des cas d'usage, les applications les plus matures concernent l'analyse de documents (combinant OCR, compréhension de mise en page, et analyse visuelle des graphiques), l'accessibilité (description d'images, transcription enrichie), et les assistants conversationnels avancés. Les applications vidéo et audio temps réel progressent rapidement mais restent plus exigeantes en termes d'infrastructure.
Le coût computationnel augmente significativement avec la multimodalité. Une image de 1024×1024 pixels peut se traduire en plusieurs centaines de tokens visuels, chacun consommant de la capacité d'attention. Une vidéo de quelques minutes peut générer des dizaines de milliers de tokens. Cette inflation a des conséquences directes sur les coûts d'API (facturation au token) et sur la latence. Les stratégies d'optimisation incluent la compression des représentations visuelles, l'échantillonnage intelligent des frames vidéo, et le routage vers des modèles plus légers quand la multimodalité n'est pas nécessaire.
La qualité des données devient également plus critique. Un système RAG multimodal doit indexer efficacement des images, des schémas, des tableaux, ce qui pose des défis d'extraction et de représentation. Les pipelines de préparation de données se complexifient, nécessitant des outils spécialisés pour chaque modalité.
Pour les équipes qui développent des applications multimodales, les frameworks comme LangChain intègrent progressivement le support de ces nouvelles modalités, mais l'écosystème reste moins mature que pour le texte pur. L'utilisation d'interfaces comme OpenWebUI avec support multimodal facilite le prototypage et les tests avant un développement plus poussé.
Conclusion
Les modèles multimodaux représentent une évolution naturelle et nécessaire de l'IA générative. En permettant aux systèmes de percevoir et de comprendre le monde à travers plusieurs sens, ils se rapprochent d'une intelligence plus générale et plus utile. Les VLM ont démontré le potentiel de cette approche pour la vision ; les modèles omnimodaux actuels étendent ces capacités à l'audio, à la vidéo, et au-delà.
Cette évolution n'est pas sans défis. La complexité architecturale, les coûts computationnels et la maturité inégale des différentes modalités imposent une approche réfléchie. Pour de nombreux cas d'usage, un VLM bien maîtrisé reste suffisant et plus économique qu'un modèle omnimodal. Mais pour les applications nécessitant une compréhension riche du contexte (assistants intelligents, analyse de contenus complexes, interfaces naturelles), la multimodalité devient un avantage décisif.
Pour les équipes techniques, l'enjeu est d'anticiper cette évolution sans se précipiter. Comprendre les capacités et les limites actuelles des modèles multimodaux, expérimenter avec les cas d'usage pertinents pour son domaine, et architecturer des systèmes suffisamment flexibles pour intégrer de nouvelles modalités à mesure qu'elles deviennent matures : c'est cette approche pragmatique qui permettra de tirer le meilleur parti de ces avancées technologiques majeures.


