Vision Language Model (VLM) : définition et exemples
Un Vision Language Model est un modèle d'IA capable de traiter simultanément du texte et des images pour générer des réponses textuelles. Contrairement aux modèles de vision par ordinateur traditionnels qui se limitent à classifier ou détecter des objets, les VLM peuvent raisonner sur le contenu visuel et répondre à des questions ouvertes en langage naturel.

Les modèles de langage ont révolutionné notre manière d'interagir avec l'IA, mais ils souffrent d'une limitation fondamentale : ils ne voient pas le monde. Demandez à un LLM classique de décrire une image, d'analyser un graphique ou d'identifier un produit sur une photo, et il sera incapable de vous répondre. Cette frontière entre le texte et le visuel est précisément ce que les Vision Language Models (VLM) viennent abolir.
Les VLM représentent une évolution majeure des modèles de langage en leur ajoutant la capacité de comprendre et raisonner sur des images. Plutôt que de traiter texte et vision comme deux mondes séparés, ces modèles unifient les deux modalités dans une architecture commune, permettant des interactions naturelles où l'on peut pointer une image et poser des questions dessus, exactement comme on le ferait avec un humain.
Dans cet article, nous allons explorer ce que sont les Vision Language Models, comprendre comment ils fonctionnent sous le capot, découvrir les principaux modèles disponibles, et surtout identifier les cas d'usage concrets où ils apportent une valeur significative.
Qu'est-ce qu'un Vision Language Model ?
Un Vision Language Model est un modèle d'IA capable de traiter simultanément du texte et des images pour générer des réponses textuelles. Contrairement aux modèles de vision par ordinateur traditionnels qui se limitent à classifier ou détecter des objets, les VLM peuvent raisonner sur le contenu visuel et répondre à des questions ouvertes en langage naturel.
La différence fondamentale avec un LLM classique réside dans l'entrée du modèle. Là où GPT ou Llama n'acceptent que du texte, un VLM peut recevoir une combinaison d'images et de texte. Vous pouvez par exemple lui soumettre une photo de votre écran avec la question "Que montre ce graphique ?" et obtenir une analyse détaillée des tendances représentées.
Cette capacité multimodale ouvre des possibilités que le texte seul ne permettait pas :
- Description d'images : générer automatiquement des légendes ou des descriptions détaillées
- Question-réponse visuelle : répondre à des questions spécifiques sur le contenu d'une image
- Analyse de documents : extraire et interpréter des informations de documents scannés, factures, formulaires
- Raisonnement visuel : résoudre des problèmes qui nécessitent de comprendre des diagrammes, des schémas ou des graphiques
- Assistance contextuelle : comprendre une capture d'écran pour aider à résoudre un problème technique
| Caractéristique | LLM classique | Vision Language Model |
|---|---|---|
| Entrées acceptées | Texte uniquement | Texte + Images |
| Compréhension visuelle | ❌ Aucune | ✅ Native |
| Description d'images | ❌ Impossible | ✅ Détaillée |
| Analyse de documents visuels | ❌ Requiert OCR externe | ✅ Intégrée |
| Raisonnement sur graphiques | ❌ Non | ✅ Oui |
Les VLM ne remplacent pas les LLM textuels pour les tâches purement linguistiques, mais ils étendent considérablement le champ des applications possibles en brisant la barrière entre compréhension textuelle et visuelle.
Comment fonctionnent les VLM sous le capot
L'architecture d'un Vision Language Model repose sur l'idée de traduire les images dans un langage que le LLM peut comprendre. Plutôt que de reconstruire entièrement un modèle de langage, les VLM s'appuient généralement sur des LLM existants et performants, auxquels ils ajoutent une capacité de perception visuelle.
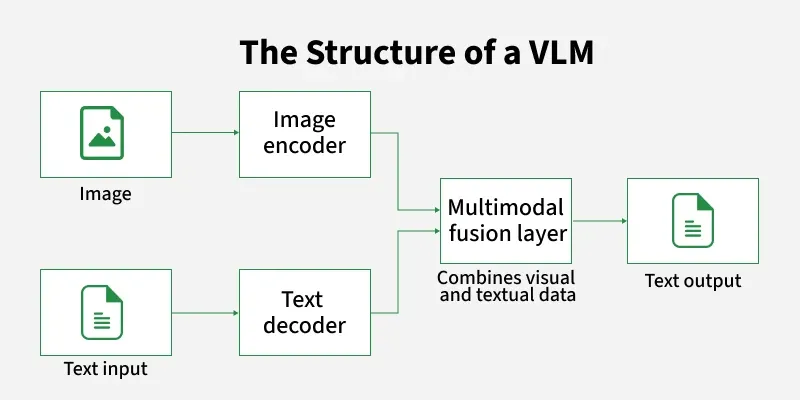
Le fonctionnement se décompose en trois composants principaux :
L'encodeur visuel constitue la première brique. Il s'agit généralement d'un modèle de type Vision Transformer (ViT) pré-entraîné sur de vastes corpus d'images. Cet encodeur découpe l'image en patches (petites zones carrées), les traite comme une séquence, et produit une représentation vectorielle dense capturant le contenu sémantique de l'image. Des architectures comme CLIP, SigLIP ou EVA ont été spécifiquement conçues pour produire des représentations visuelles alignées avec le langage.
Le module de projection (ou connecteur) joue un rôle crucial : il transforme les représentations visuelles de l'encodeur en "tokens visuels" compatibles avec l'espace d'embedding du LLM. Ce composant peut être aussi simple qu'une couche linéaire, ou plus sophistiqué comme un Perceiver Resampler qui compresse l'information visuelle en un nombre fixe de tokens. C'est ce module qui permet au LLM de "voir" l'image comme s'il s'agissait d'une séquence de tokens textuels.
Le LLM backbone traite ensuite la séquence combinée de tokens visuels et textuels. Le modèle de langage n'a pas besoin de modifications architecturales majeures : il reçoit simplement une entrée enrichie où certains tokens représentent du contenu visuel plutôt que des mots. Le fine-tuning sur des données image-texte permet au LLM d'apprendre à interpréter ces tokens visuels et à générer des réponses pertinentes.
L'entraînement d'un VLM suit généralement plusieurs phases. Une première phase d'alignement utilise des paires image-légende pour apprendre au modèle à connecter vision et langage. Une seconde phase de fine-tuning sur des tâches de conversation visuelle affine la capacité du modèle à répondre à des questions complexes. Certains modèles ajoutent une phase d'alignement avec les préférences humaines (RLHF) pour améliorer la qualité et la sécurité des réponses.
À découvrir : notre formation LLM Engineering
Panorama des principaux VLM disponibles
L'écosystème des Vision Language Models s'est considérablement enrichi, avec des offres couvrant tous les segments : modèles propriétaires ultra-performants, modèles open source accessibles, et modèles compacts pour l'exécution locale.
Modèles propriétaires
GPT-4o et GPT-4 Vision d'OpenAI ont marqué l'entrée des VLM dans le mainstream. Capables d'analyser des images avec une précision remarquable, ils excellent dans la compréhension de documents complexes, l'analyse de graphiques et le raisonnement visuel. L'intégration native dans ChatGPT a démocratisé l'usage auprès du grand public.
Claude 3.5 Sonnet d'Anthropic propose des capacités visuelles particulièrement fortes pour l'analyse de documents et de code. Sa fenêtre de contexte généreuse permet de traiter plusieurs images simultanément, facilitant les comparaisons ou l'analyse de séquences.
Gemini de Google, disponible en versions Pro et Ultra, se distingue par ses capacités multimodales natives. Conçu dès le départ comme un modèle multimodal, il gère efficacement les interactions complexes entre texte, images et même vidéos.
Modèles open source
LLaVA (Large Language and Vision Assistant) a été l'un des premiers VLM open source performants, démontrant qu'il était possible d'atteindre des performances compétitives avec une architecture relativement simple. Ses successeurs (LLaVA-1.5, LLaVA-NeXT) ont progressivement comblé l'écart avec les modèles propriétaires.
Qwen2-VL d'Alibaba représente l'état de l'art open source actuel. Disponible en plusieurs tailles (2B, 7B, 72B paramètres), il excelle particulièrement dans la compréhension de documents et le support multilingue, avec des performances comparables aux meilleurs modèles propriétaires sur de nombreux benchmarks.
PaliGemma de Google offre un modèle compact mais performant, idéal pour les déploiements avec contraintes de ressources. Pixtral de Mistral apporte une option européenne avec un bon équilibre performance/efficacité.
| Modèle | Type | Tailles disponibles | Points forts |
|---|---|---|---|
| GPT-4o | Propriétaire | - | Polyvalence, qualité globale |
| Claude 3.5 Sonnet | Propriétaire | - | Analyse de documents, code |
| Gemini Pro | Propriétaire | - | Multimodal natif, vidéo |
| Qwen2-VL | Open source | 2B, 7B, 72B | État de l'art open source |
| LLaVA-NeXT | Open source | 7B, 13B, 34B | Communauté active, bien documenté |
| PaliGemma | Open source | 3B | Compact, efficace |
Pour l'exécution locale avec Ollama, des modèles comme LLaVA ou BakLLaVA sont directement disponibles et permettent d'expérimenter avec la vision sans dépendre d'API cloud, préservant ainsi la confidentialité des images analysées.
Cas d'usage concrets des VLM
Les Vision Language Models trouvent des applications dans de nombreux domaines où la compréhension visuelle combinée au raisonnement linguistique apporte une valeur significative.
Analyse et extraction de documents
L'un des cas d'usage les plus matures concerne le traitement intelligent de documents. Les VLM peuvent analyser des factures, des formulaires, des contrats ou des rapports scannés pour en extraire les informations structurées. Contrairement aux solutions OCR traditionnelles qui se contentent de reconnaître le texte, les VLM comprennent la mise en page, les relations entre éléments, et peuvent répondre à des questions spécifiques sur le contenu.
Un système de RAG enrichi par un VLM peut ainsi ingérer des documents visuellement riches (présentations PowerPoint, rapports avec graphiques, documentations techniques illustrées) et permettre des recherches qui prennent en compte à la fois le texte et les éléments visuels.
Assistance au développement et debugging
Les VLM transforment l'assistance technique en permettant de partager des captures d'écran plutôt que de décrire laborieusement un problème. Un développeur peut soumettre une capture d'écran d'un message d'erreur, d'une interface mal rendue, ou d'un comportement inattendu, et obtenir une analyse contextuelle avec des suggestions de résolution.
Cette capacité s'intègre naturellement dans les outils d'assistance au code comme Continue ou dans des agents de développement capables d'interagir avec des interfaces graphiques.
E-commerce et retail
Le secteur du commerce électronique bénéficie largement des VLM pour :
- Catalogage automatique : générer des descriptions de produits à partir de photos
- Recherche visuelle : permettre aux clients de chercher des produits en soumettant une image
- Contrôle qualité : détecter des défauts ou des non-conformités sur les photos de produits
- Modération de contenu : vérifier que les images soumises par les vendeurs respectent les guidelines
Accessibilité
Les VLM améliorent significativement l'accessibilité numérique en générant des descriptions alternatives pour les images. Un utilisateur malvoyant peut ainsi obtenir une description détaillée de n'importe quelle image, qu'il s'agisse d'un meme sur les réseaux sociaux, d'un graphique dans un article, ou d'une photo partagée par un proche.
Médical et scientifique
Dans des domaines spécialisés comme la médecine ou la recherche scientifique, les VLM fine-tunés peuvent assister les professionnels dans l'analyse d'imagerie médicale, l'interprétation de résultats de laboratoire visuels, ou la compréhension de figures scientifiques complexes. Ces applications nécessitent généralement des modèles spécifiquement entraînés et validés pour le domaine concerné.
Conclusion
Les Vision Language Models représentent une extension naturelle et puissante des capacités des LLM. En unifiant compréhension textuelle et visuelle dans une architecture commune, ils ouvrent des possibilités que ni les modèles de langage purs ni les modèles de vision traditionnels ne pouvaient adresser seuls.
L'écosystème a atteint une maturité remarquable en peu de temps. Les modèles propriétaires comme GPT-4o ou Claude 3.5 Sonnet offrent des performances de pointe accessibles via API, tandis que des alternatives open source comme Qwen2-VL ou LLaVA permettent des déploiements sur infrastructure propre, préservant la confidentialité des données visuelles traitées.
Pour les équipes qui construisent des applications d'IA générative, les VLM deviennent un composant incontournable dès que le cas d'usage implique des images : analyse de documents, assistance visuelle, catalogage de produits, ou création de systèmes RAG multimodaux. La capacité à poser des questions en langage naturel sur du contenu visuel transforme des workflows auparavant complexes en interactions simples et intuitives.
L'évolution des VLM ne fait que commencer. Les prochaines générations étendront probablement leurs capacités à la vidéo de manière plus native, affineront leur compréhension spatiale et temporelle, et verront l'émergence de modèles spécialisés pour des domaines verticaux. Maîtriser ces modèles dès aujourd'hui, c'est se préparer à exploiter pleinement le potentiel de l'IA multimodale de demain.


