OpenMetadata : catalogue de données open source
Dans un contexte où les entreprises accumulent des données provenant de sources toujours plus nombreuses, une question cruciale émerge : comment permettre aux équipes de découvrir, comprendre et faire confiance aux données qu'elles utilisent ? Entre les tables dispersées dans plusieurs Data Warehouses, les pipelines de transformation complexes et les métriques métiers dont les définitions varient selon les équipes, le besoin d'un point d'entrée unique pour naviguer dans le patrimoine data devient pressant.

Dans un contexte où les entreprises accumulent des données provenant de sources toujours plus nombreuses, une question cruciale émerge : comment permettre aux équipes de découvrir, comprendre et faire confiance aux données qu'elles utilisent ? Entre les tables dispersées dans plusieurs Data Warehouses, les pipelines de transformation complexes et les métriques métiers dont les définitions varient selon les équipes, le besoin d'un point d'entrée unique pour naviguer dans le patrimoine data devient pressant.
C'est précisément pour répondre à ce besoin qu'a émergé OpenMetadata, une plateforme de catalogue de données open source lancée en 2021. Conçu par d'anciens ingénieurs d'Uber ayant travaillé sur des problématiques de gouvernance à grande échelle, OpenMetadata propose une alternative crédible aux solutions propriétaires comme Atlan, Alation ou Collibra. En offrant des fonctionnalités de découverte, de documentation, de lignage et de qualité des données dans une solution entièrement open source, OpenMetadata permet aux organisations de reprendre le contrôle sur leur gouvernance data sans dépendre d'un éditeur ou exploser leur budget.
Qu'est-ce qu'OpenMetadata ?
OpenMetadata est une plateforme centralisée de gestion des métadonnées qui permet aux équipes data de découvrir, documenter et gouverner l'ensemble de leurs actifs de données. Contrairement à un simple inventaire de tables, OpenMetadata ambitionne de devenir le point de référence unique où convergent toutes les informations sur les données d'une organisation : schémas, propriétaires, documentation métier, métriques de qualité et relations de lignage.

La plateforme s'articule autour de plusieurs fonctionnalités clés :
-
Découverte des données : un moteur de recherche puissant permet de trouver rapidement des tables, dashboards, pipelines ou modèles ML en utilisant des mots-clés, des filtres par domaine métier ou des tags. Les utilisateurs peuvent explorer le catalogue comme ils le feraient avec un moteur de recherche web.
-
Documentation collaborative : chaque actif peut être enrichi avec des descriptions, des définitions métier et des annotations. OpenMetadata encourage une approche collaborative où les équipes techniques et métiers contribuent ensemble à documenter le patrimoine data.
-
Data Lineage automatique : la plateforme trace automatiquement les relations entre les sources, les transformations et les consommations de données, offrant une visibilité complète sur le parcours des données à travers les systèmes.
-
Profiling et qualité des données : OpenMetadata peut analyser automatiquement les données pour générer des statistiques (distribution, valeurs nulles, cardinalité) et détecter des anomalies, permettant aux équipes de surveiller la santé de leurs datasets.
-
Glossaire métier : un glossaire centralisé permet de définir les termes métiers de l'organisation et de les associer aux actifs techniques, créant ainsi un pont entre le vocabulaire des équipes business et les structures techniques sous-jacentes.
OpenMetadata supporte nativement une large gamme de connecteurs pour les principales technologies du Modern Data Stack : Data Warehouses (Snowflake, BigQuery, Redshift), bases de données (PostgreSQL, MySQL, MongoDB), outils de BI (Tableau, Looker, Metabase), orchestrateurs (Airflow), et outils de transformation comme dbt.
Fonctionnalités principales et architecture
Pour comprendre la valeur d'OpenMetadata, il est essentiel de saisir comment la plateforme collecte, organise et expose les métadonnées.
Collecte et connecteurs
OpenMetadata utilise un système de connecteurs (appelés "ingestion pipelines") pour extraire automatiquement les métadonnées depuis les sources de données. Ces connecteurs peuvent être exécutés de manière planifiée pour maintenir le catalogue à jour. Le processus d'ingestion capture les schémas des tables, les relations entre objets, les statistiques d'usage et, lorsque c'est possible, les informations de lignage.
L'architecture d'ingestion est conçue pour être extensible. Si un connecteur n'existe pas pour une source spécifique, le framework permet d'en développer de nouveaux en Python. Cette ouverture garantit qu'OpenMetadata peut s'adapter à des environnements techniques variés, y compris des systèmes legacy ou des solutions maison.
# Exemple de configuration d'ingestion pour Snowflake
source:
type: snowflake
serviceName: production-warehouse
serviceConnection:
config:
type: Snowflake
username: ${SNOWFLAKE_USER}
password: ${SNOWFLAKE_PASSWORD}
account: xy12345.eu-west-1
warehouse: COMPUTE_WH
sourceConfig:
config:
type: DatabaseMetadata
includeTables: true
includeViews: true
yaml
Lignage et impact analysis
L'une des forces d'OpenMetadata réside dans sa capacité à construire automatiquement le Data Lineage à partir des métadonnées collectées. En analysant les requêtes SQL, les configurations dbt ou les logs des orchestrateurs, la plateforme reconstitue les dépendances entre les différents actifs.
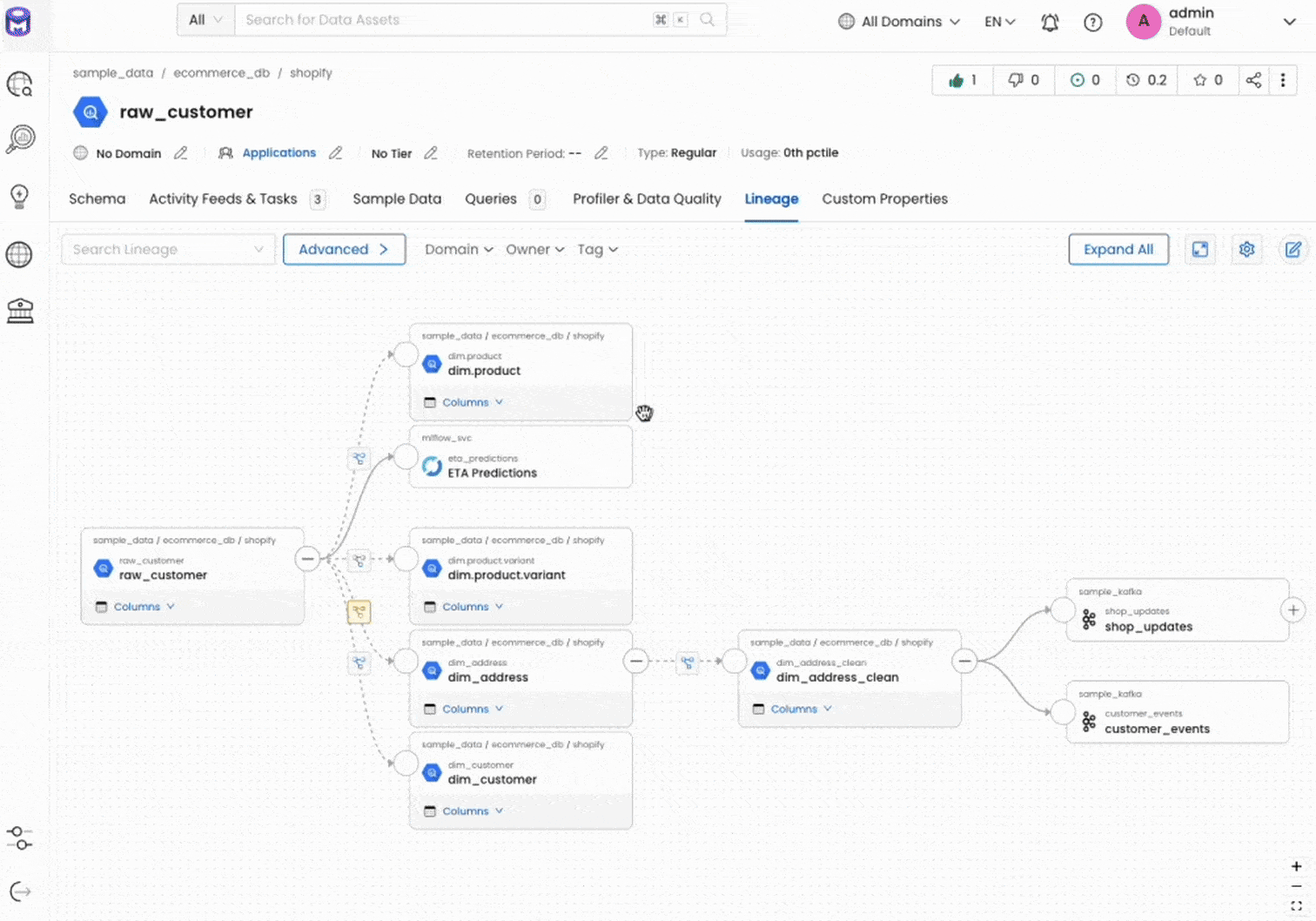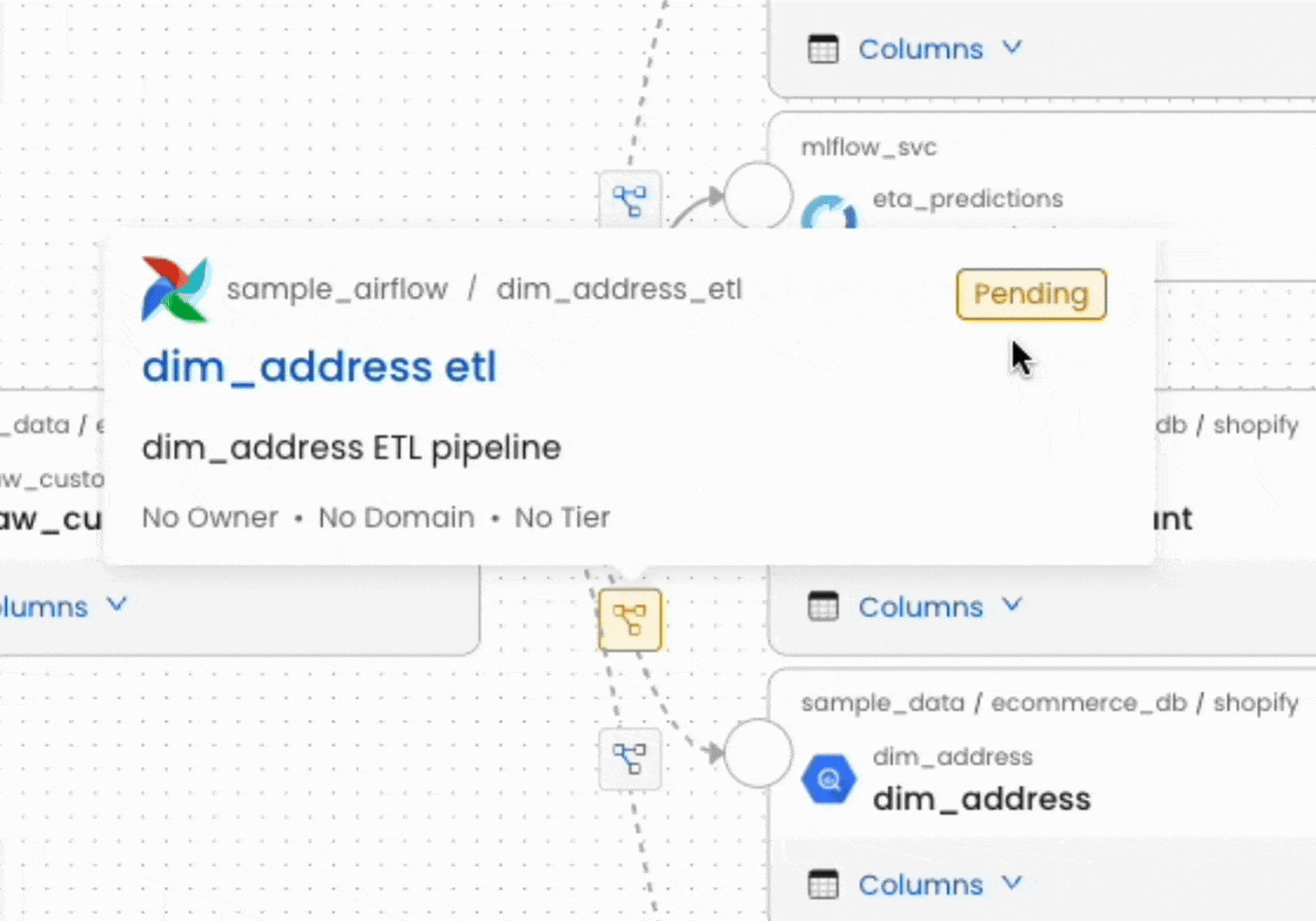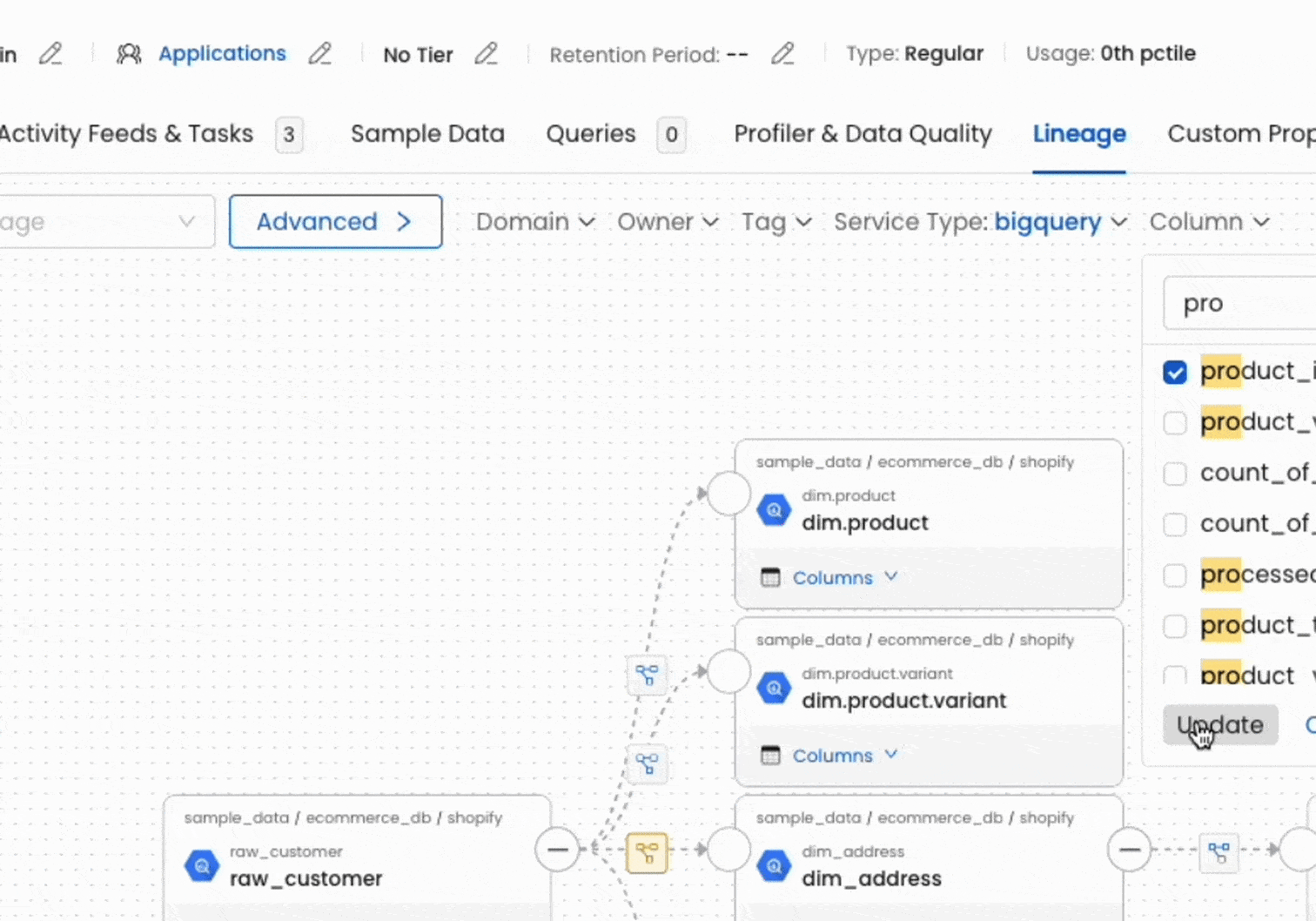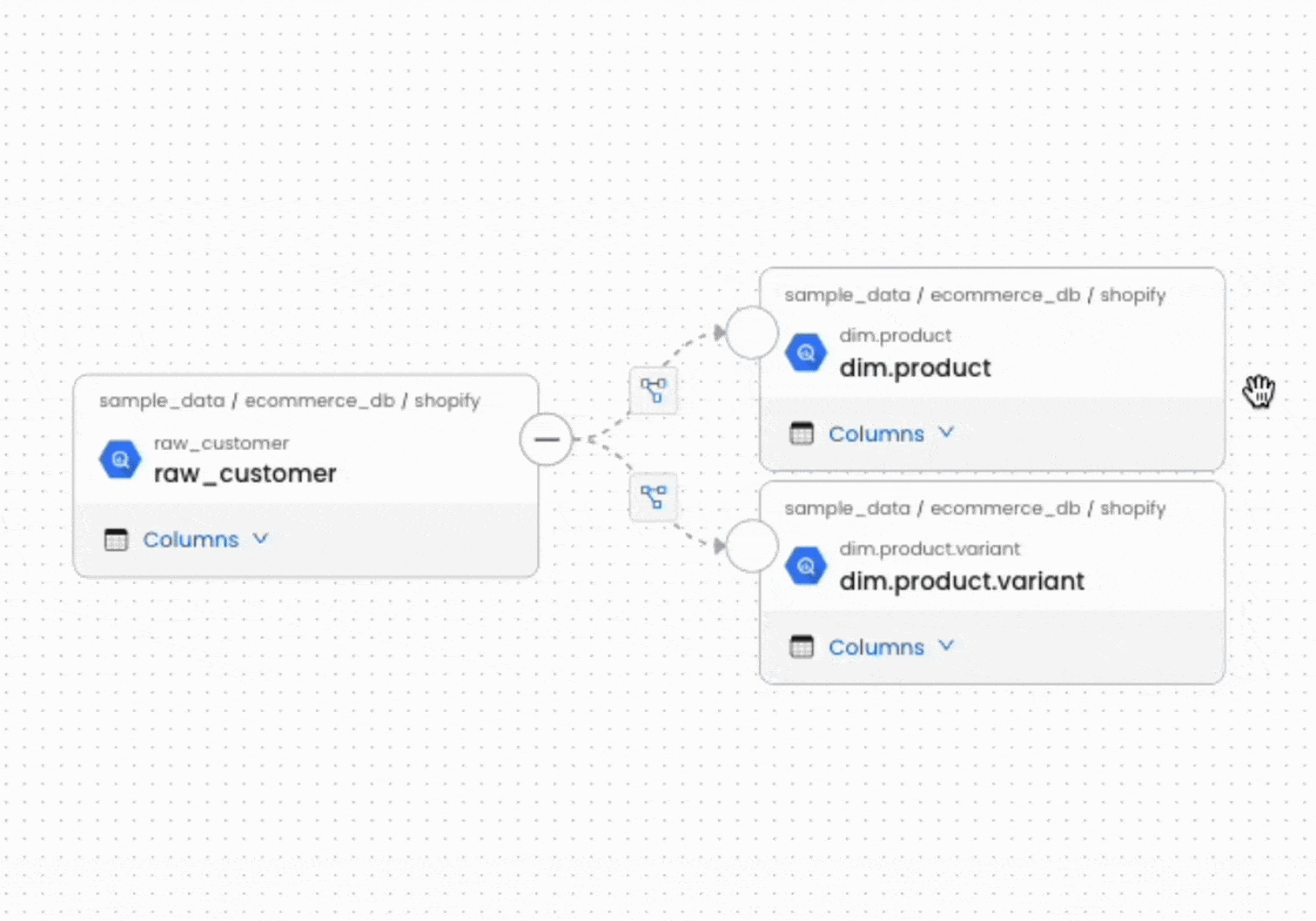
Cette visibilité sur le lignage permet deux usages critiques. D'une part, les utilisateurs peuvent remonter à l'origine d'une donnée pour comprendre comment elle a été calculée (lignage ascendant). D'autre part, avant de modifier une table source, les équipes peuvent identifier tous les actifs impactés en aval (lignage descendant ou impact analysis), évitant ainsi les effets de bord non anticipés.
| Fonctionnalité | Description | Bénéfice |
|---|---|---|
| Découverte | Recherche full-text avec filtres | Trouver rapidement les données pertinentes |
| Documentation | Descriptions, tags, ownership | Comprendre le contexte et la fiabilité |
| Lignage | Graphe des dépendances | Analyser l'impact des changements |
| Profiling | Statistiques automatiques | Détecter les anomalies de qualité |
| Glossaire | Termes métiers centralisés | Aligner vocabulaire technique et business |
| Alertes | Notifications sur changements | Réagir aux évolutions du catalogue |
Collaboration et gouvernance
OpenMetadata intègre des mécanismes de collaboration qui transforment le catalogue d'un simple référentiel technique en un outil de travail quotidien. Les utilisateurs peuvent laisser des commentaires sur les actifs, mentionner des collègues, et suivre des datasets pour être notifiés des changements. Un système de tâches permet de demander des mises à jour de documentation ou de signaler des problèmes de qualité.
La gouvernance est renforcée par la notion d'ownership (propriété des données). Chaque actif peut être assigné à un propriétaire (équipe ou individu) responsable de sa qualité et de sa documentation. Cette responsabilisation favorise une culture data où chacun contribue à maintenir la fiabilité du patrimoine informationnel.
OpenMetadata face aux solutions propriétaires
Le marché des catalogues de données est dominé par des solutions propriétaires comme Atlan, Alation, Collibra ou DataHub (partiellement open source). OpenMetadata se positionne comme une alternative viable pour les organisations souhaitant éviter les coûts de licence souvent prohibitifs de ces plateformes.
Les solutions commerciales comme Atlan ou Alation proposent des interfaces très abouties, des intégrations clé en main avec de nombreux outils, et un support professionnel. Cependant, leurs tarifications (souvent basées sur le nombre d'utilisateurs ou le volume de métadonnées) peuvent représenter plusieurs centaines de milliers d'euros annuels pour les grandes organisations. Ces coûts limitent parfois l'adoption à quelques équipes, là où la gouvernance des données devrait concerner l'ensemble de l'entreprise.
OpenMetadata adopte une approche radicalement différente en proposant l'intégralité de ses fonctionnalités en open source, sans version "enterprise" bridée. Cette philosophie présente plusieurs avantages :
- Coût prévisible : les seuls coûts sont l'infrastructure d'hébergement et le temps d'administration, éliminant les surprises budgétaires liées aux licences.
- Personnalisation totale : le code source ouvert permet d'adapter la plateforme aux besoins spécifiques de l'organisation.
- Pas de vendor lock-in : les métadonnées restent sous le contrôle total de l'organisation, exportables et portables.
- Contribution communautaire : la roadmap est influencée par les besoins réels des utilisateurs, et les entreprises peuvent contribuer directement aux fonctionnalités.
En contrepartie, le choix d'OpenMetadata implique d'assumer la responsabilité du déploiement, de la maintenance et des mises à jour. Les organisations doivent disposer des compétences internes (ou faire appel à des partenaires) pour opérer la plateforme. Pour les entreprises ayant des équipes DevOps ou Platform Engineering, cet investissement reste généralement modeste comparé aux économies réalisées sur les licences.
| Critère | OpenMetadata | Solutions propriétaires |
|---|---|---|
| Coût de licence | Gratuit | Élevé (100k€+ / an) |
| Fonctionnalités | Complètes | Complètes |
| Support | Communauté + consulting | Éditeur |
| Déploiement | Self-hosted ou Cloud | Généralement SaaS |
| Personnalisation | Totale (code source) | Limitée |
| Maturité | En forte croissance | Établie |
Mise en œuvre et bonnes pratiques
Le déploiement d'OpenMetadata peut se faire de plusieurs manières selon les contraintes et préférences de l'organisation. La plateforme fournit des images Docker officielles et des charts Helm pour Kubernetes, facilitant l'installation dans des environnements conteneurisés. Une option de déploiement managé est également disponible via OpenMetadata SaaS pour les organisations préférant éviter la gestion de l'infrastructure.
L'architecture d'OpenMetadata comprend plusieurs composants : un serveur API backend (Java), une base de données (MySQL ou PostgreSQL) pour stocker les métadonnées, Elasticsearch pour la recherche, et une interface web React. En production, il est recommandé de déployer ces composants de manière redondante pour garantir la disponibilité.
Pour réussir l'adoption d'OpenMetadata, plusieurs bonnes pratiques méritent d'être suivies :
-
Commencer par les données critiques : plutôt que de cataloguer exhaustivement toutes les sources, démarrer avec les datasets les plus utilisés permet de démontrer rapidement la valeur et d'encourager l'adoption.
-
Impliquer les équipes métiers dès le départ pour définir le glossaire et contribuer à la documentation. Un catalogue maintenu uniquement par les équipes techniques risque de ne pas répondre aux besoins des utilisateurs finaux.
-
Automatiser l'ingestion des métadonnées pour garantir que le catalogue reste synchronisé avec la réalité. Un catalogue obsolète perd rapidement la confiance des utilisateurs.
-
Définir clairement les ownership et responsabilités pour chaque domaine de données, en s'appuyant sur la fonctionnalité de propriété d'OpenMetadata.
-
Intégrer le catalogue dans les workflows existants : liens depuis les outils de BI vers les pages du catalogue, documentation dbt synchronisée automatiquement, alertes vers Slack ou Teams.
À découvrir : notre formation Data Engineer
Conclusion
OpenMetadata s'impose comme une alternative crédible et mature aux solutions propriétaires de catalogue de données. En proposant gratuitement des fonctionnalités de découverte, documentation, lignage et qualité des données, la plateforme démocratise l'accès à une gouvernance data structurée, y compris pour les organisations aux budgets contraints.
Son approche open source garantit transparence, personnalisation et indépendance vis-à-vis des éditeurs, tout en bénéficiant d'une communauté active et d'une roadmap ambitieuse. Pour les entreprises ayant les compétences pour opérer la plateforme, OpenMetadata représente un excellent rapport fonctionnalités/coût qui permet de construire une culture data solide sans compromis sur les capacités.
Pour les Data Engineers et les équipes data, maîtriser OpenMetadata devient une compétence pertinente. Au-delà de la construction de pipelines, il s'agit désormais de garantir que les données produites sont découvrables, documentées et fiables pour l'ensemble de l'organisation. Dans un monde où la donnée devient un actif stratégique, le catalogue de données n'est plus un luxe mais une fondation indispensable pour exploiter ce patrimoine en toute confiance.